【Spark】快来学习RDD的创建以及操作方式吧!
目录
RDD的创建
三种方式
从一个集合中创建
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
从文件中创建
val rdd2 = sc.textFile("/words.txt")
从其他的RDD转化而来
val rdd3=rdd2.flatMap(_.split(" "))
RDD编程常用API
算子分类
Transformation
概述
Transformation —— 根据数据集创建一个新的数据集,计算后返回一个新的RDD,但不会直接返回计算结果,二是记住这些应用到数据集(例如一个文件)上的转换动作,只有当发生一个要求返回结果给Driver的动作是,这些转换才会真正运行。
帮助文档
http://spark.apache.org/docs/2.2.0/rdd-programming-guide.html#transformations
常用Transformation表
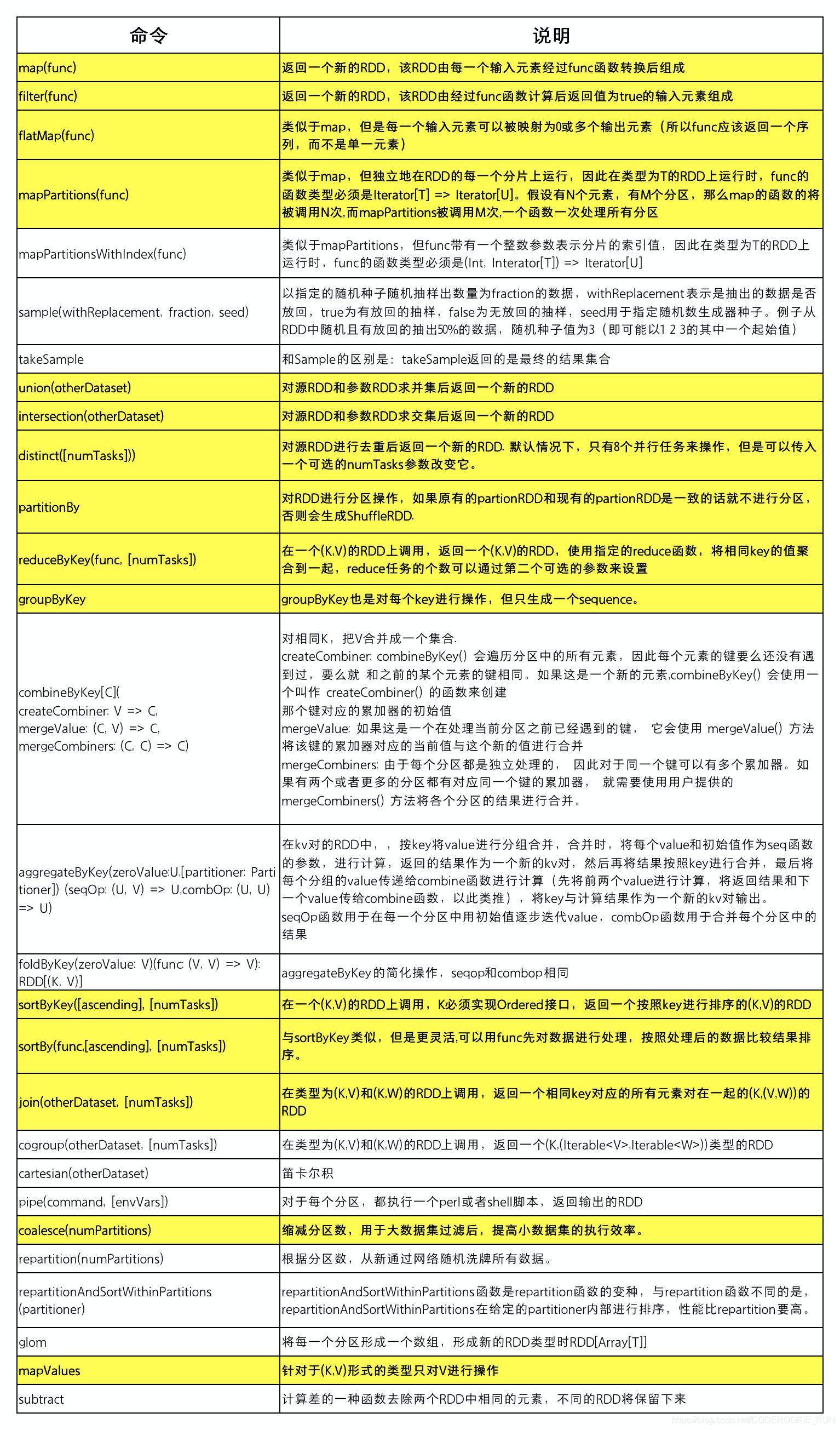
Transformation使用实例
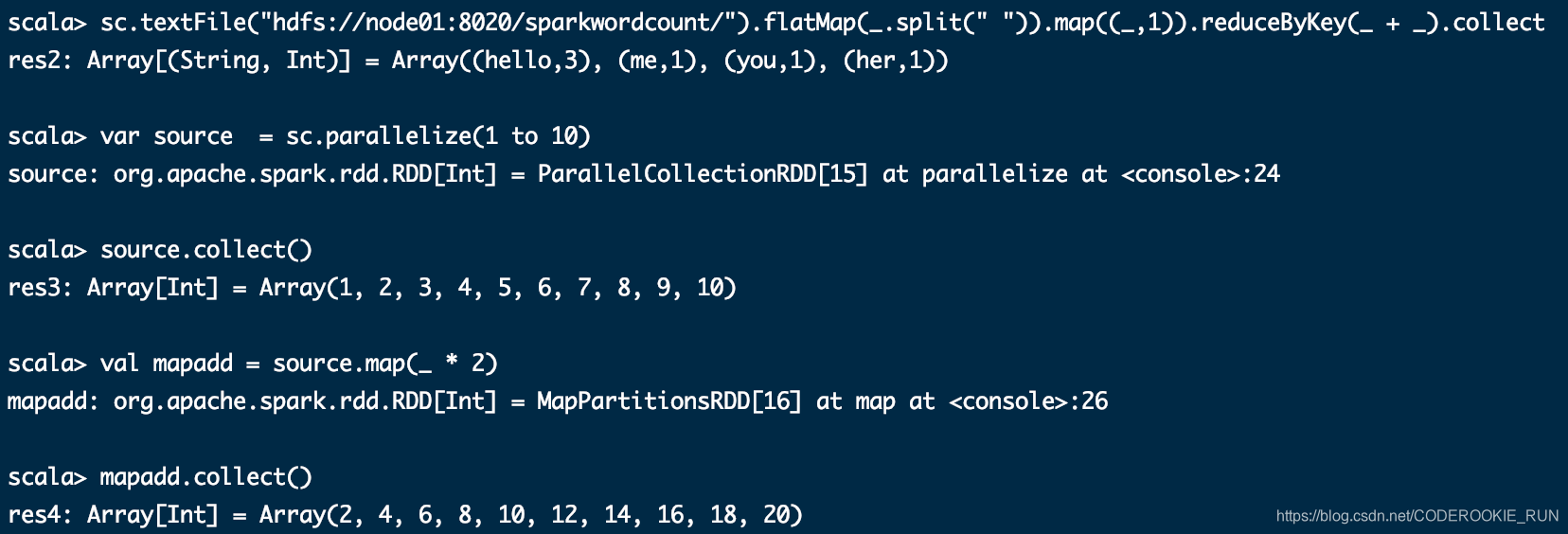
map(func)
将分区里面每一条数据取出来,进行处理
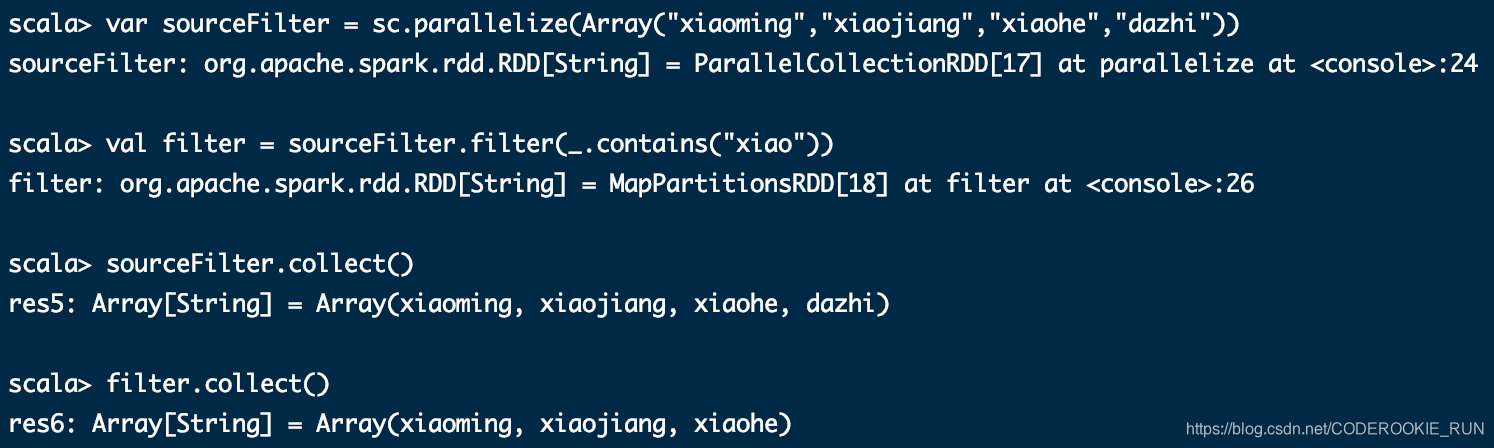
filter(func)
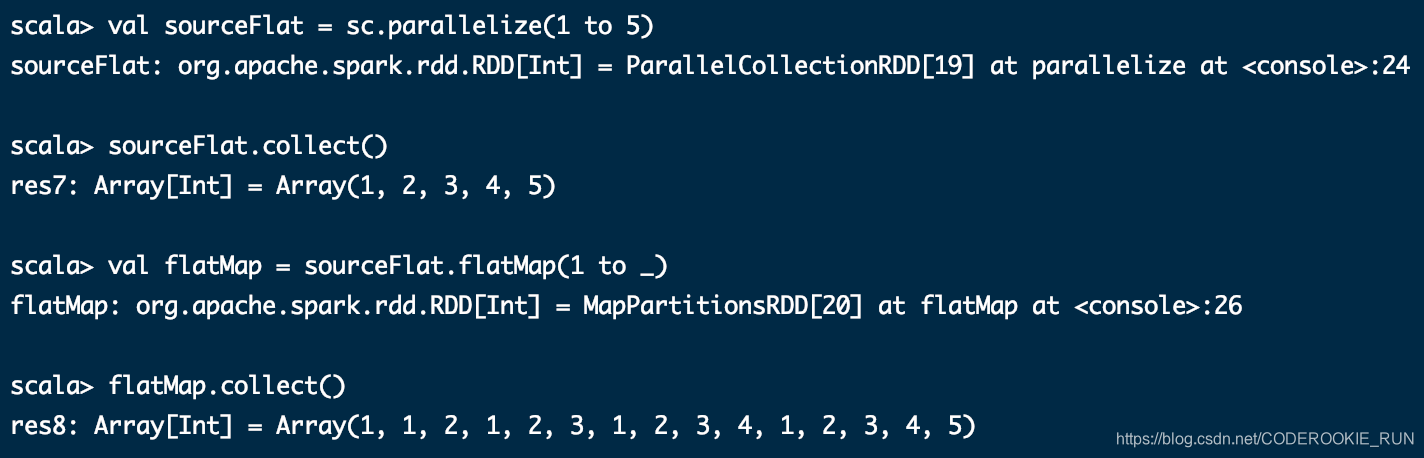
flatMap(func)
mapPartitions(func)
一次性将一个分区里面的数据全部取出来。效率更高
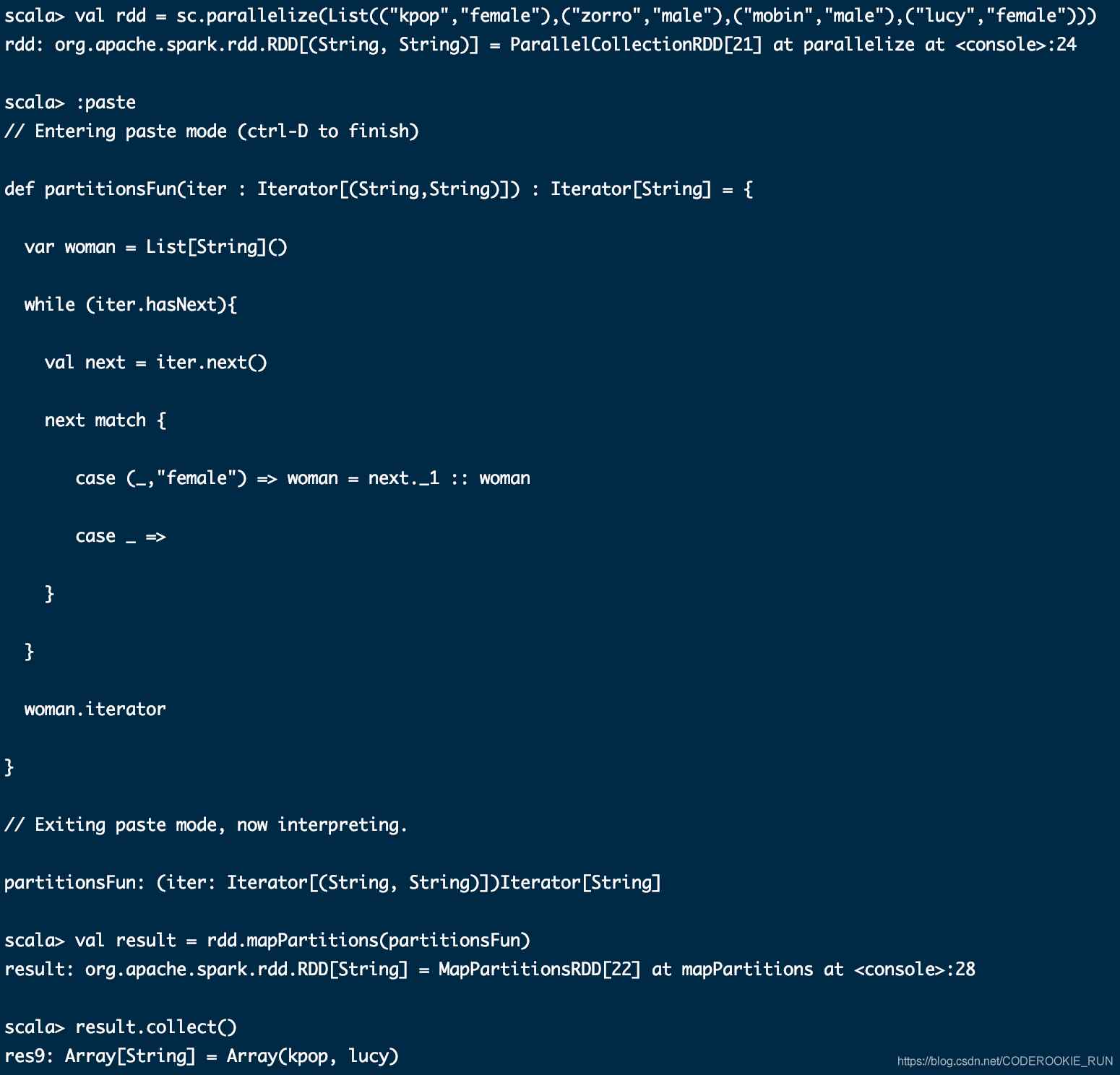
mapPartitionsWithIndex(func)
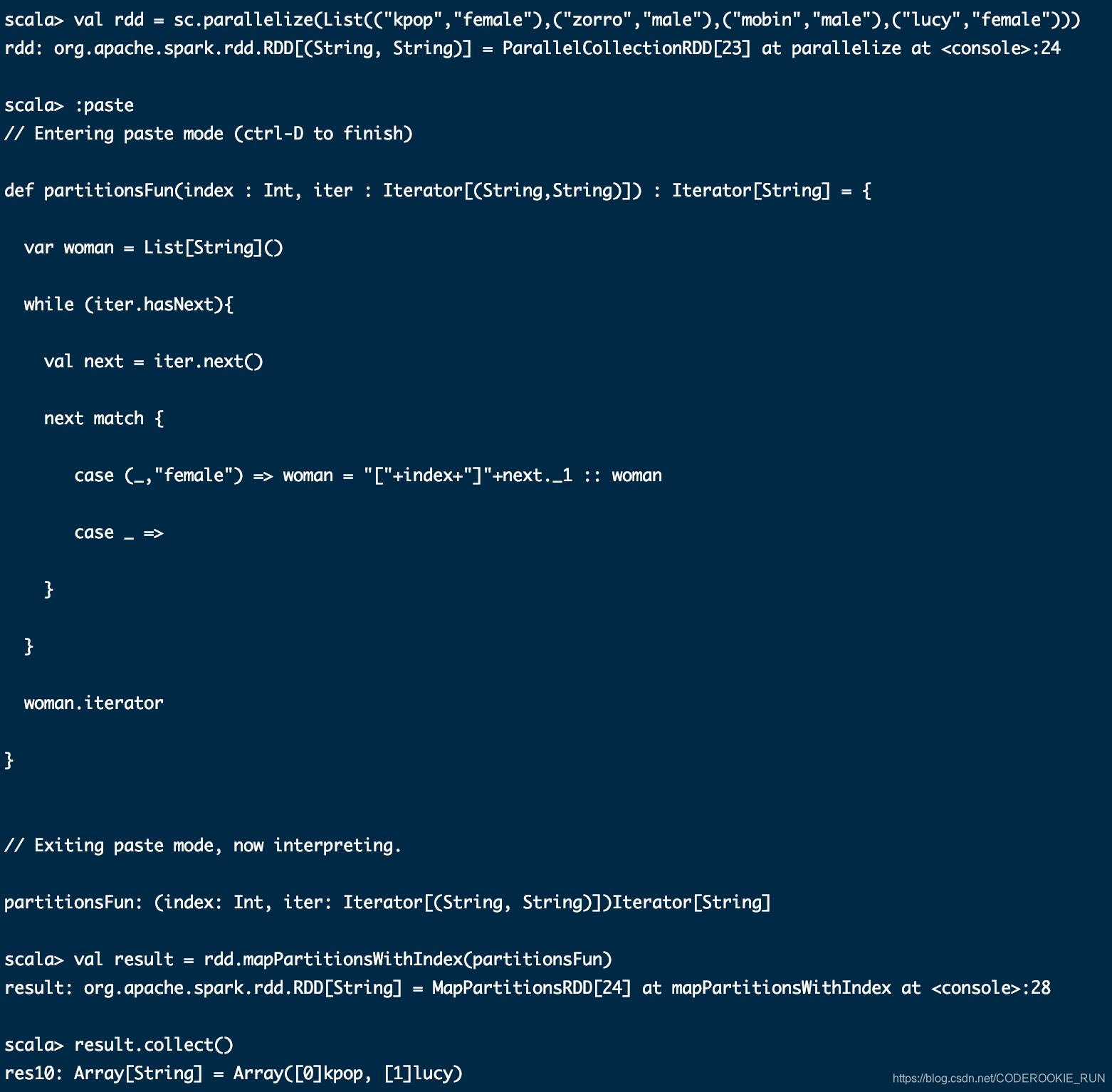
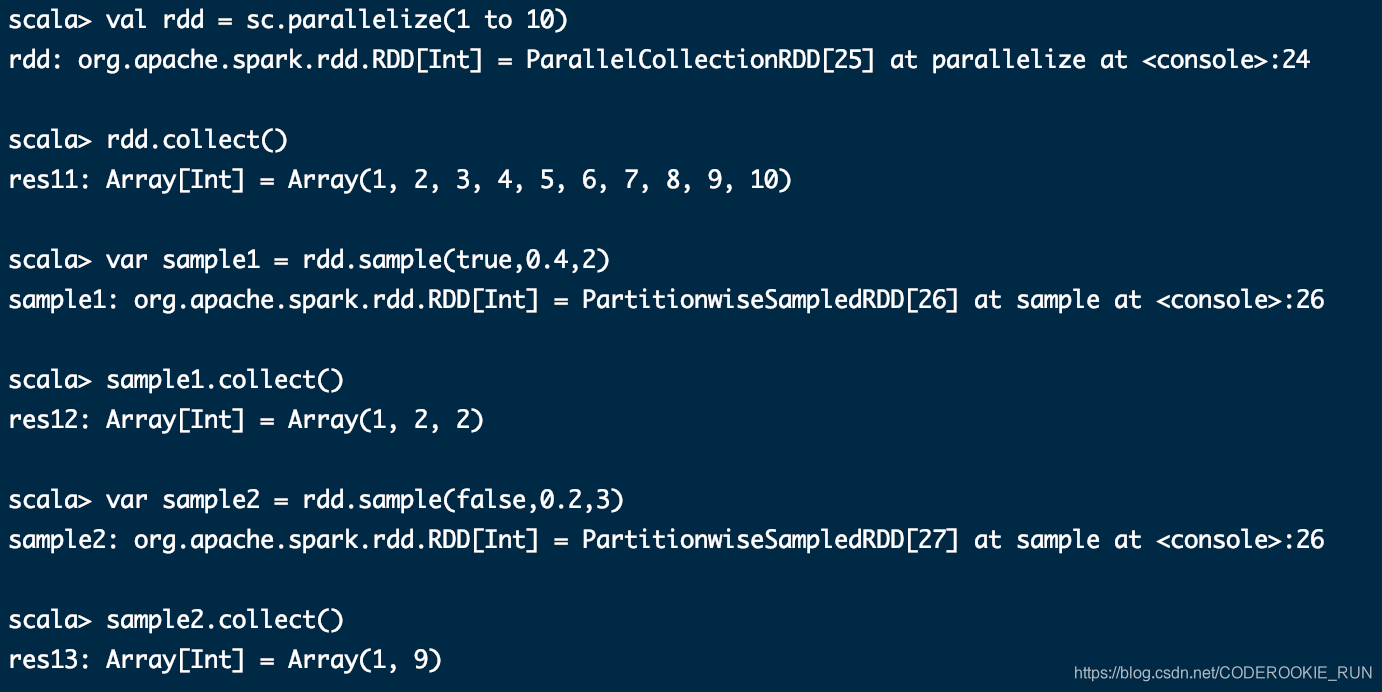
sample(withReplacement, fraction, seed)
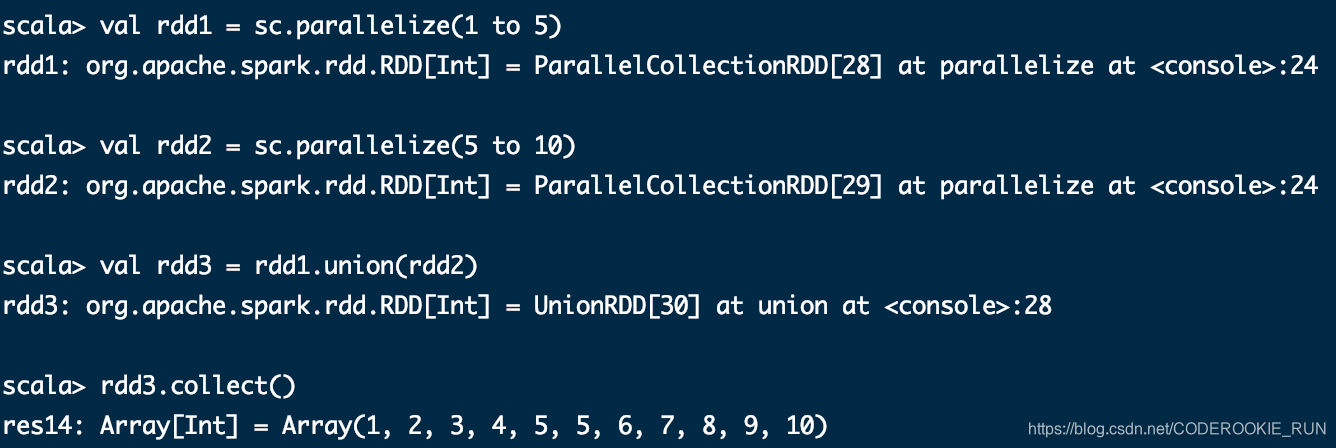
union(otherDataset)
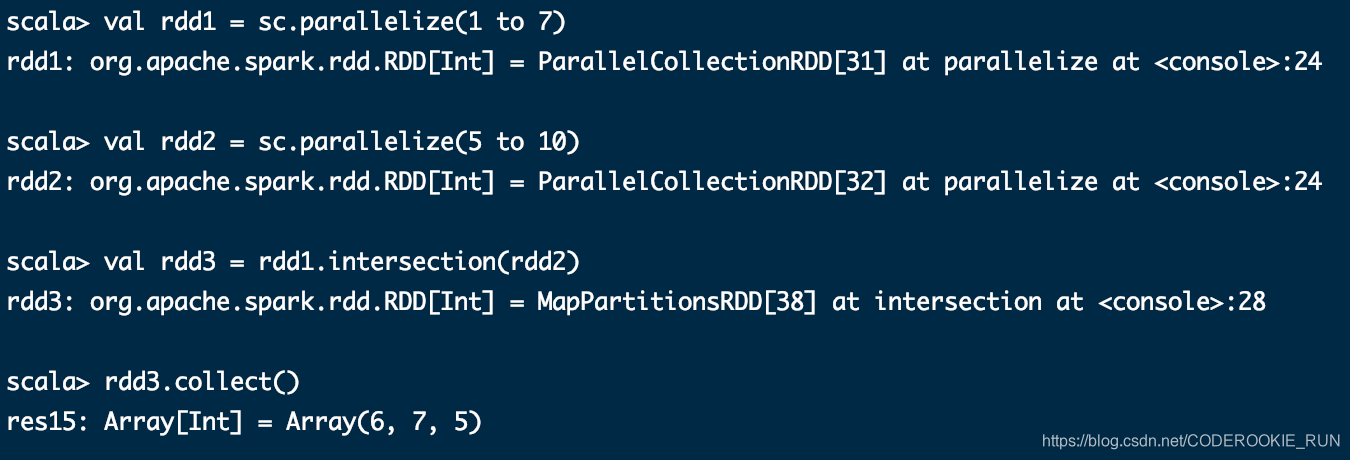
intersection(otherDataset)
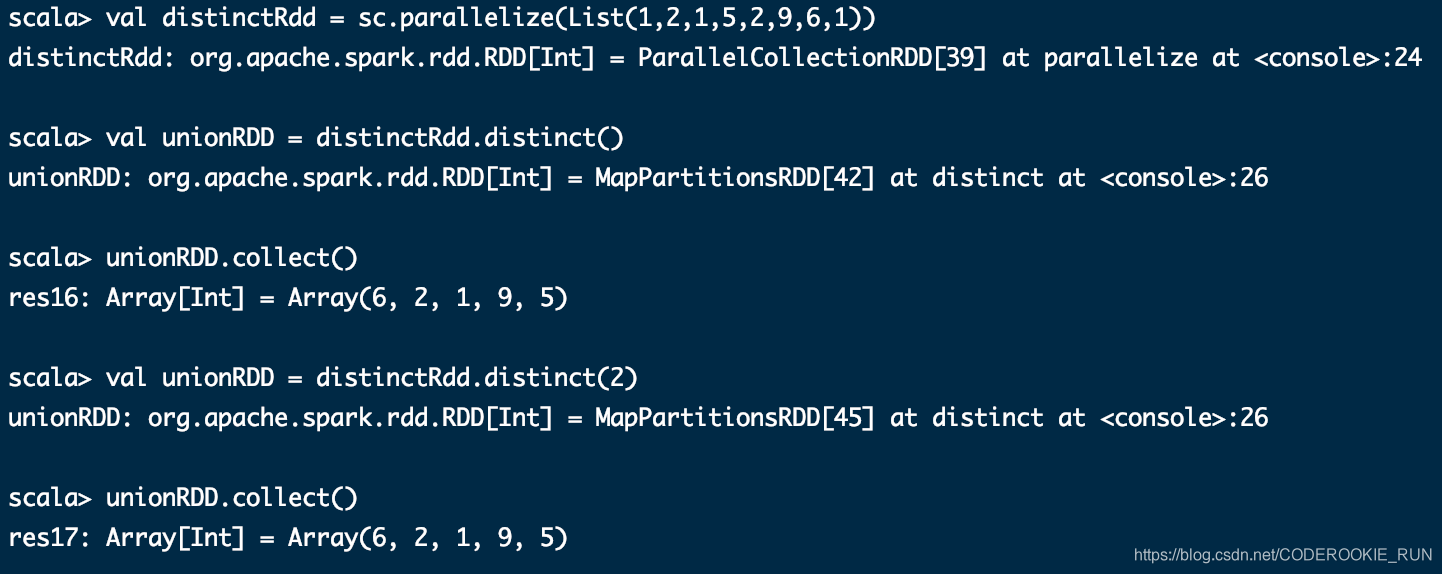
distinct([numTasks]))
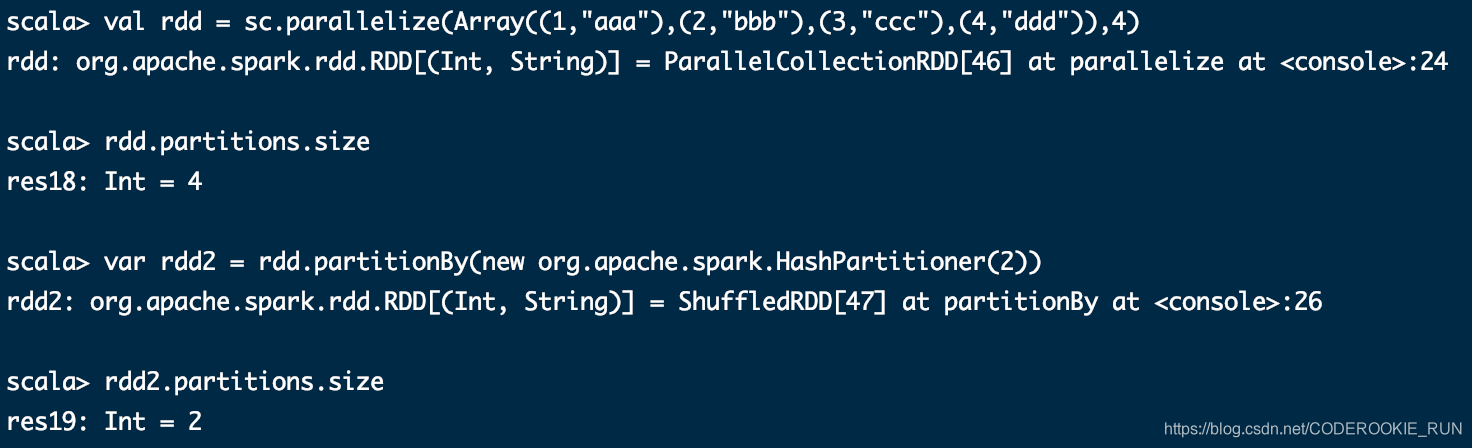
partitionBy
重新分区,分区数可以手动指定的。分区可能变多也可能变少,而且partitionBy还会产生shuffle过程
reduceByKey(func, [numTasks])
效率更高,会对数据提前进行部分的聚合,减少数据的key的shuffle

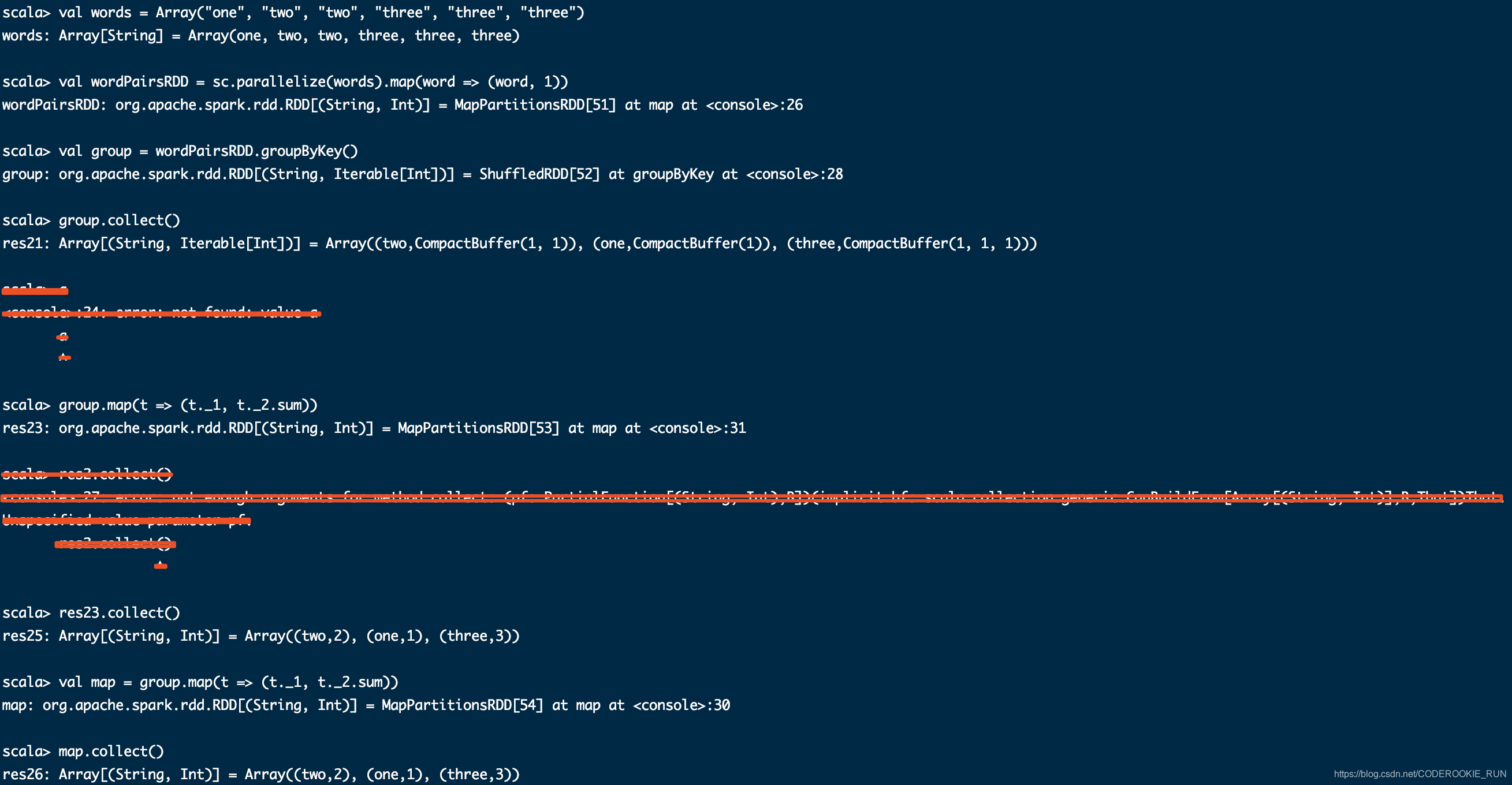
groupByKey
效率低下,尽量不要用
combineByKey
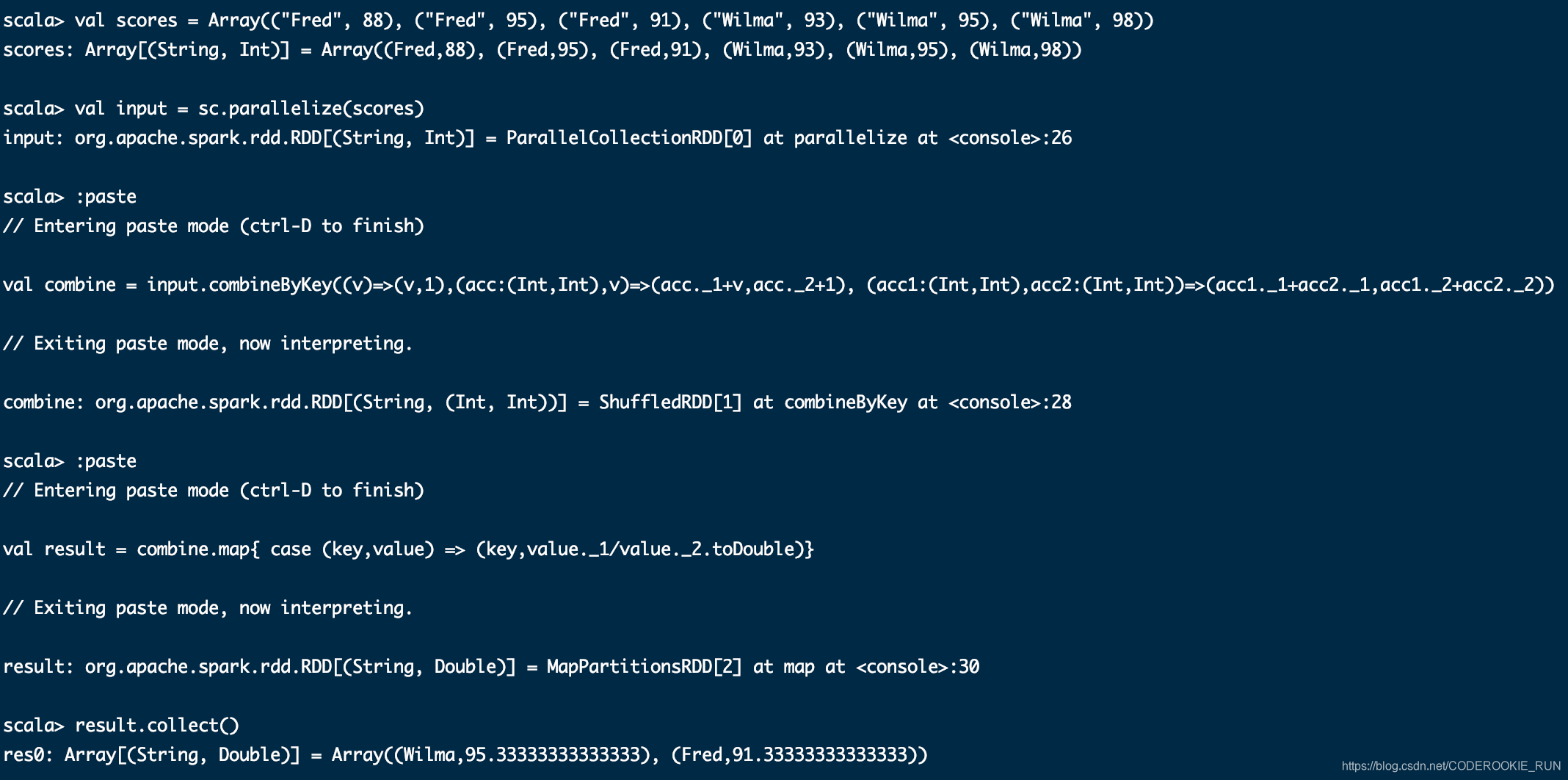
aggregateByKey(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)

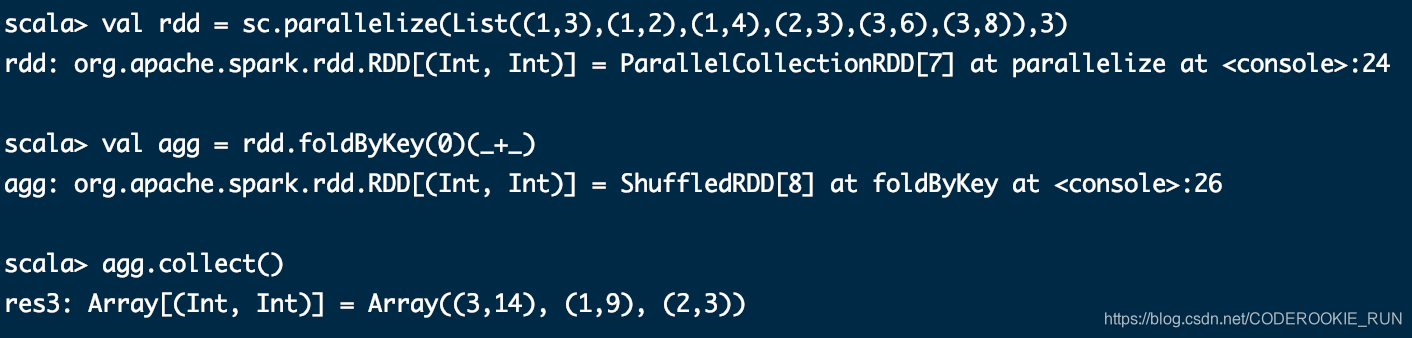
foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
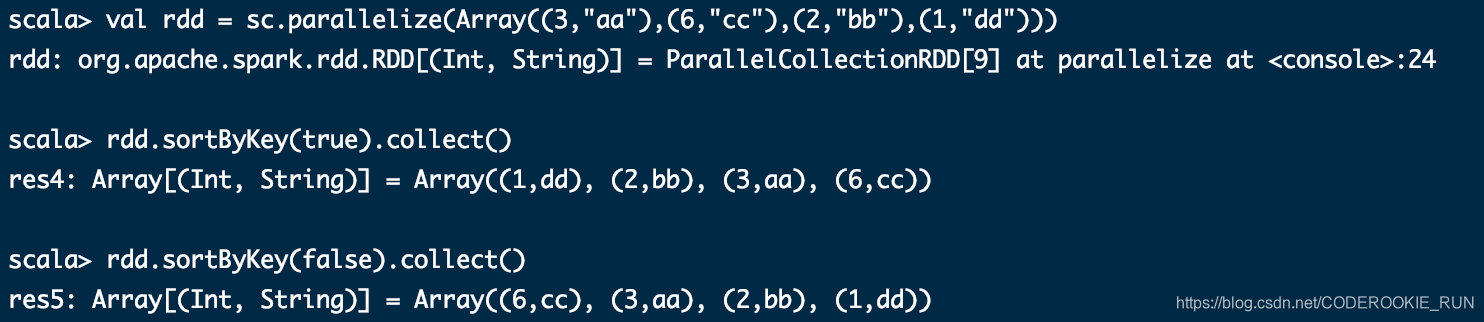
sortByKey([ascending], [numTasks])
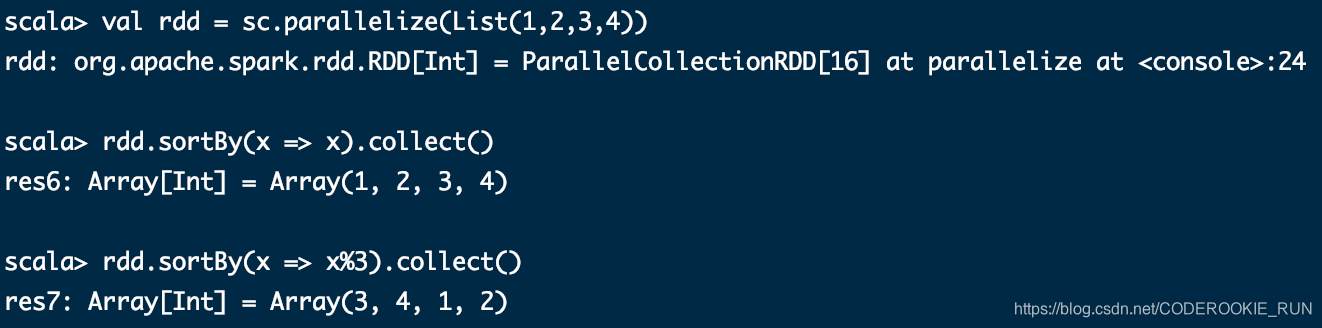
sortBy(func,[ascending], [numTasks])
join(otherDataset, [numTasks])
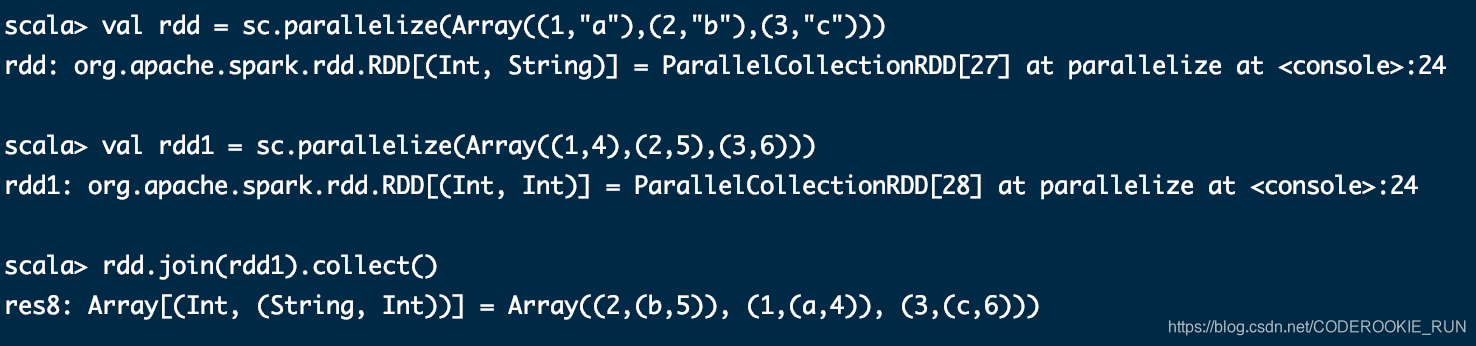
cogroup(otherDataset, [numTasks])
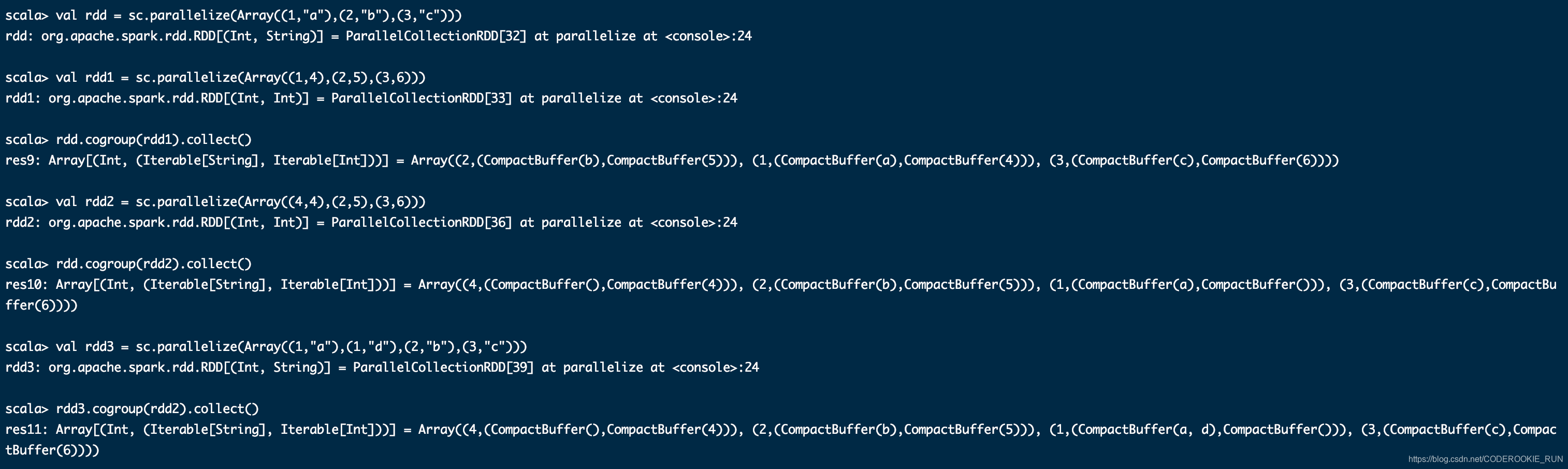
cartesian(otherDataset)
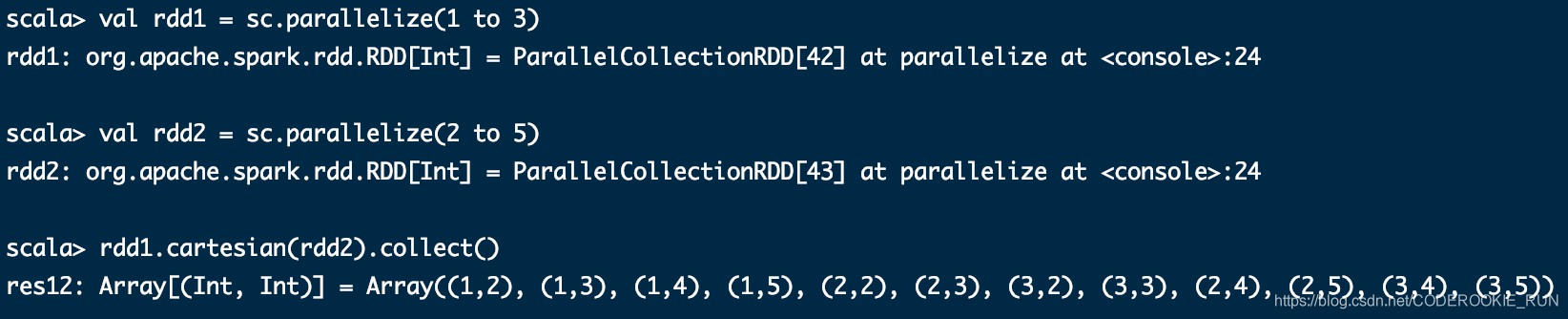
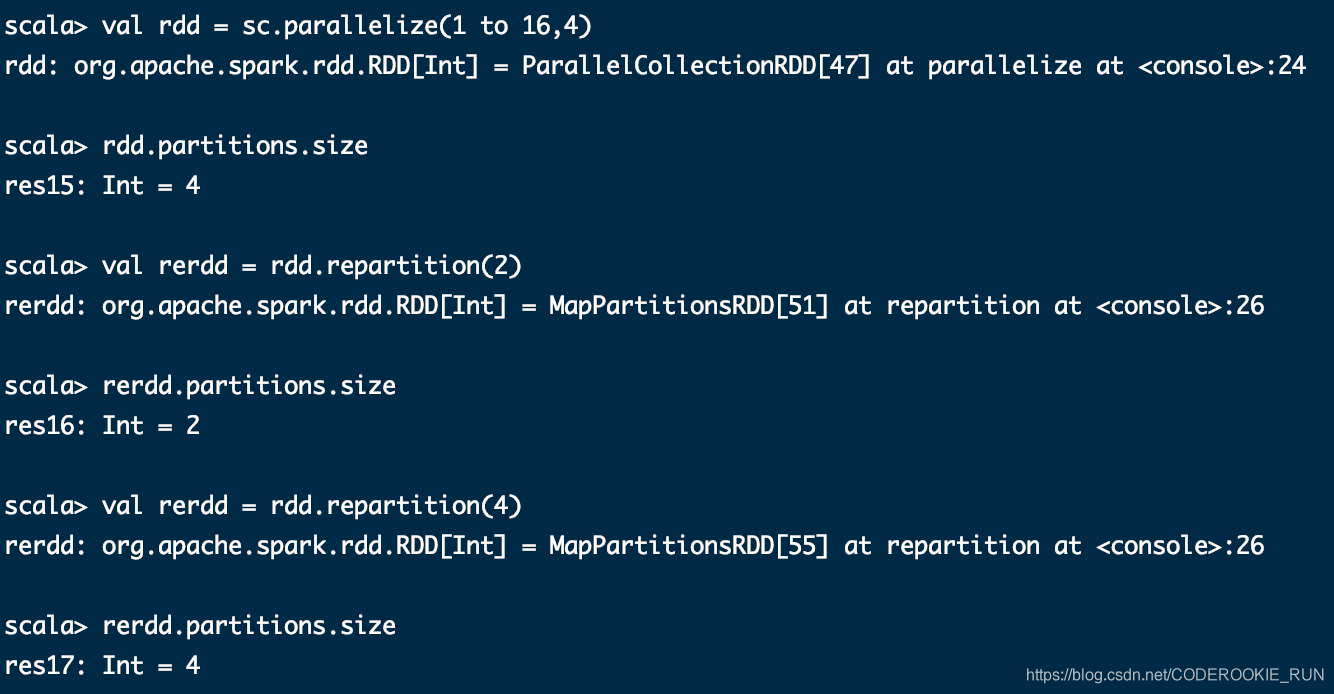
coalesce(numPartitions)
缩减分区数到指定的值,分区的个数只能减少,不能变多。不会产生shuffle过程
适用于一些大的数据集filter过滤之后,进行缩减分区,提高效率
1280M数据 ==> 10个block块 ==> 10个分区,每个分区128M数据 ==> filter ==> 10个分区,每个分区里面剩下了1KB数据 ==> coalesce => 1个分区
repartition(numPartitions)
数据随机洗牌冲洗分区,没有任何规则,可以将分区数变大,或者变小,会产生shuffle的过程
glom

mapValues

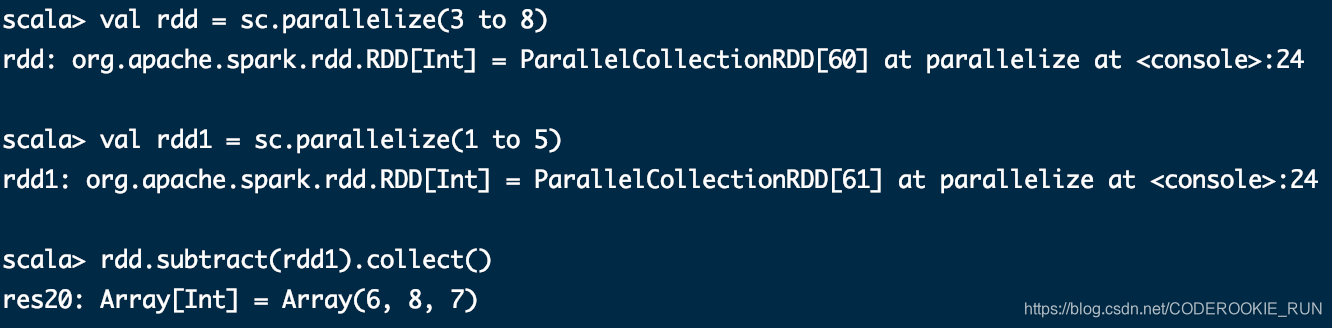
subtract
Action
帮助文档
http://spark.apache.org/docs/2.2.0/rdd-programming-guide.html#actions
常用Action表
Action使用实例
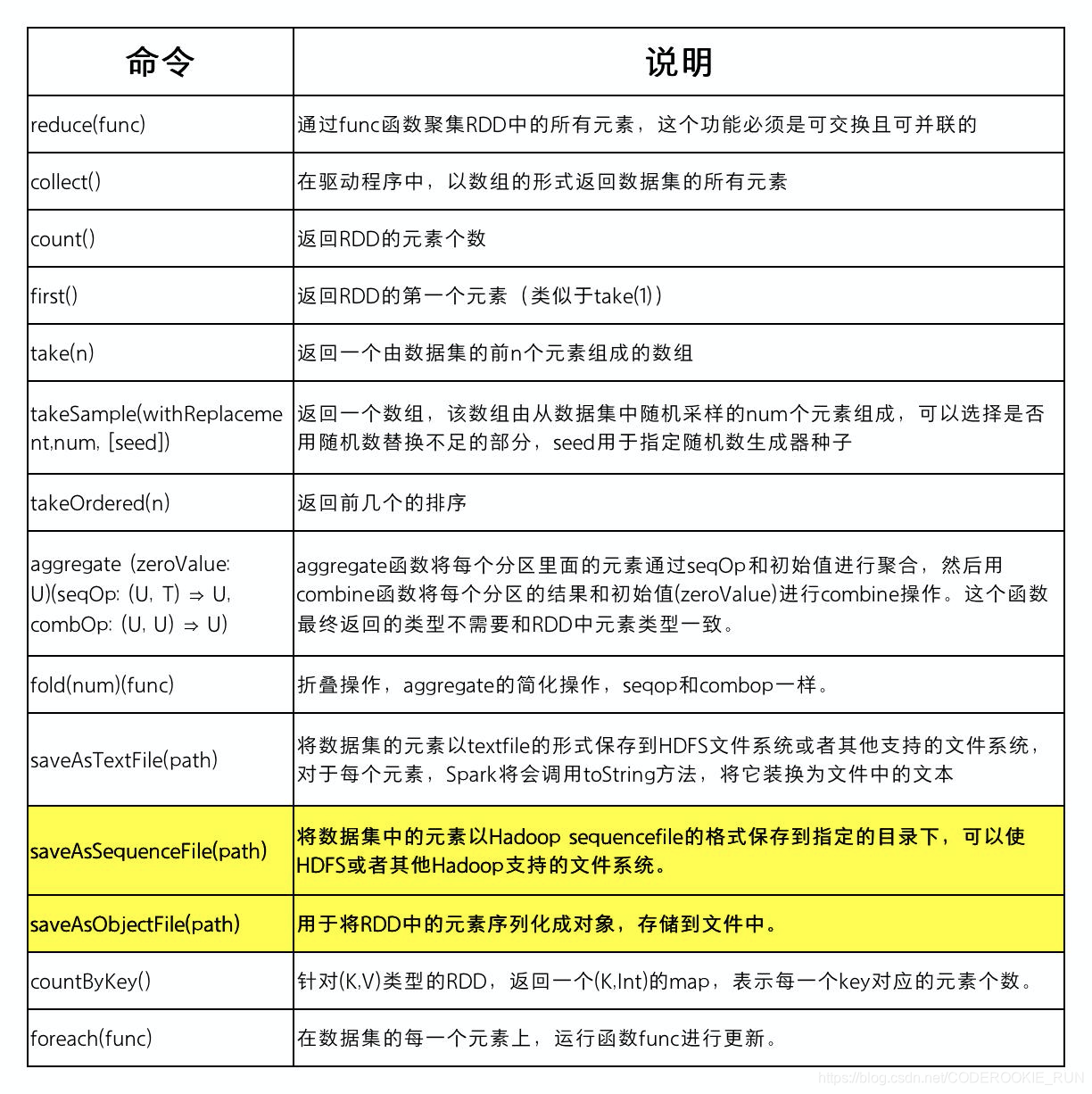
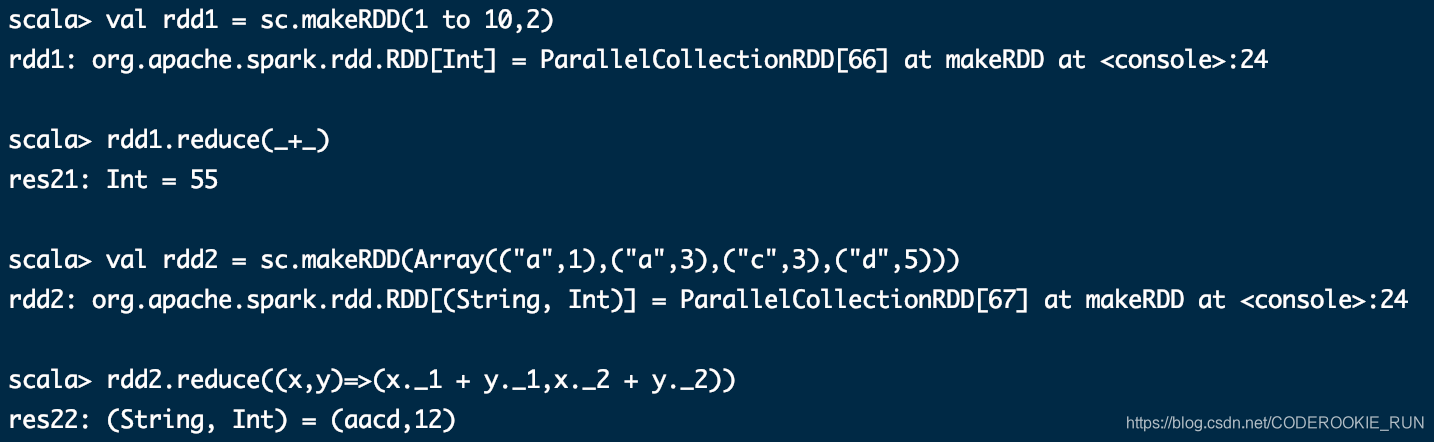
reduce(func)
collect()

count()

first()

take(n)

takeSample(withReplacement,num, [seed])
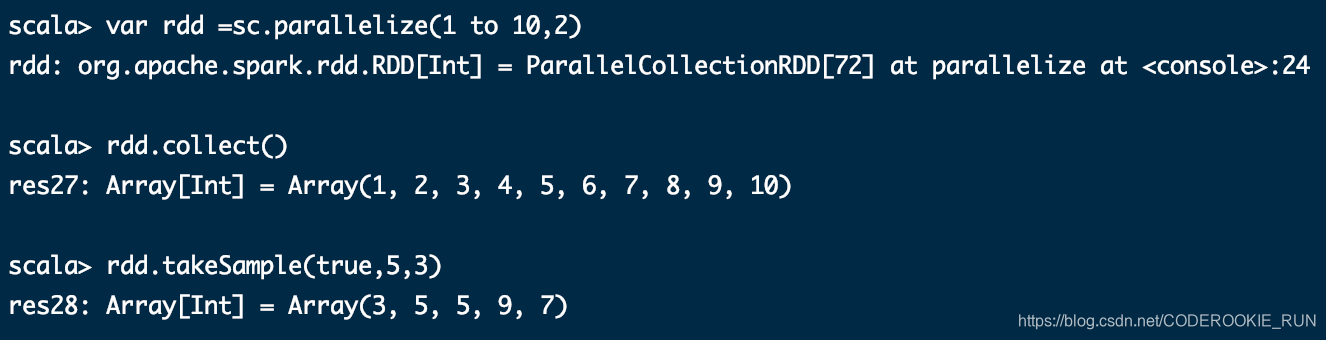
takeOrdered(n)
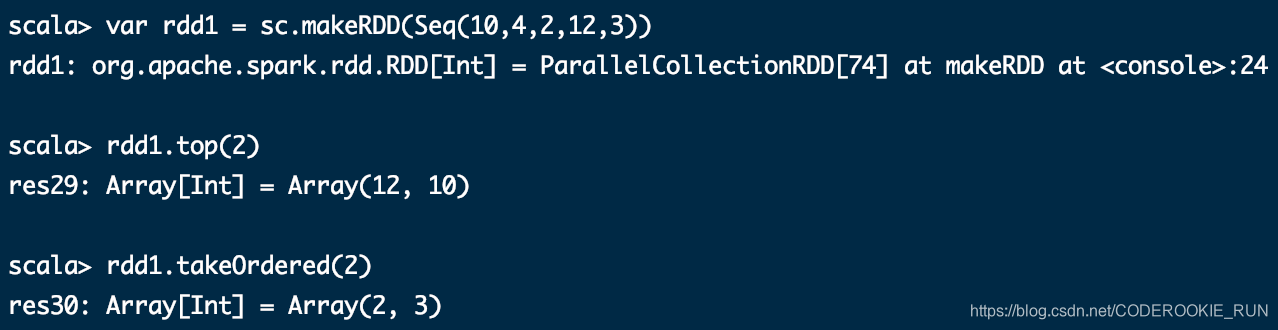
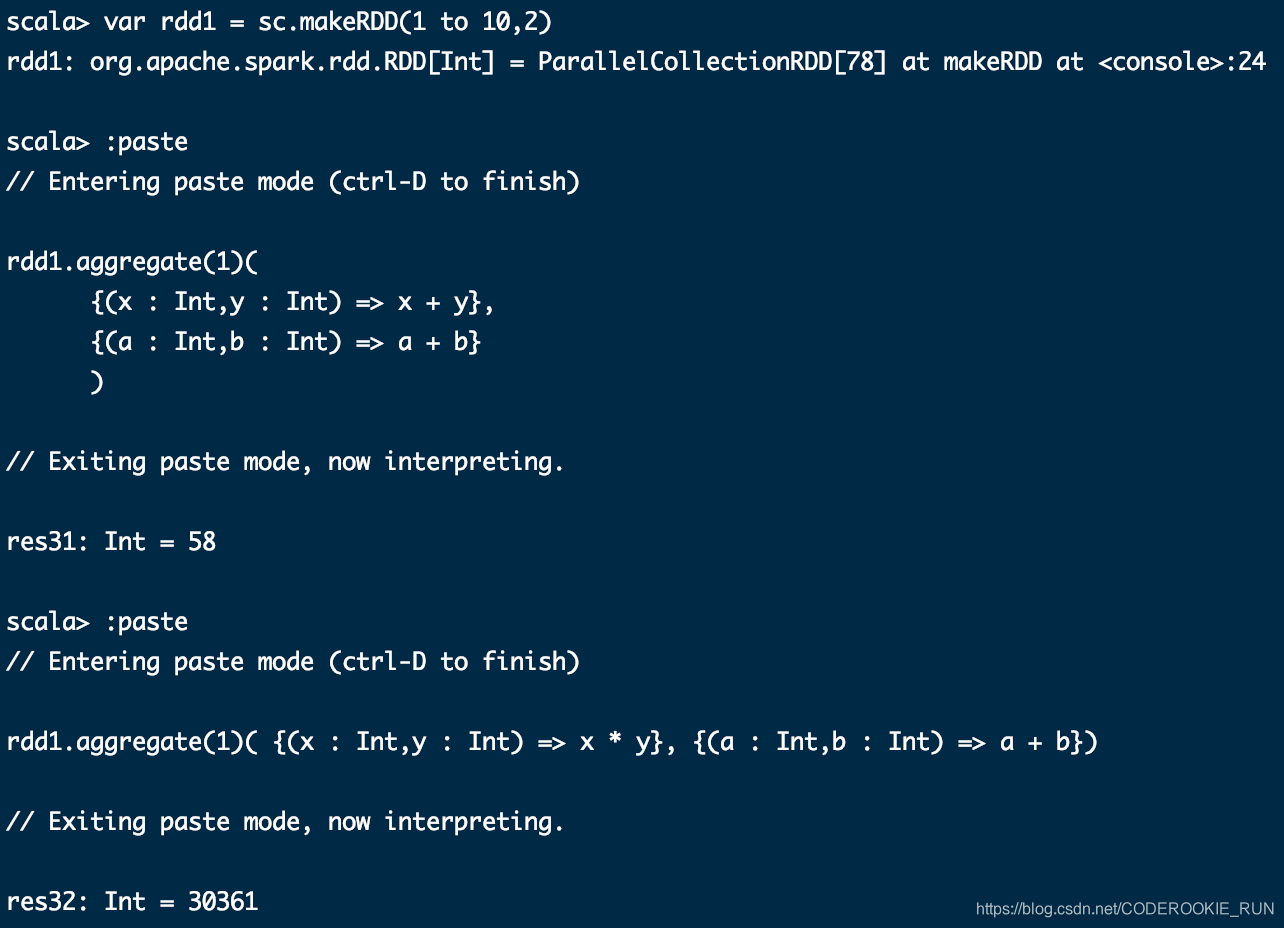
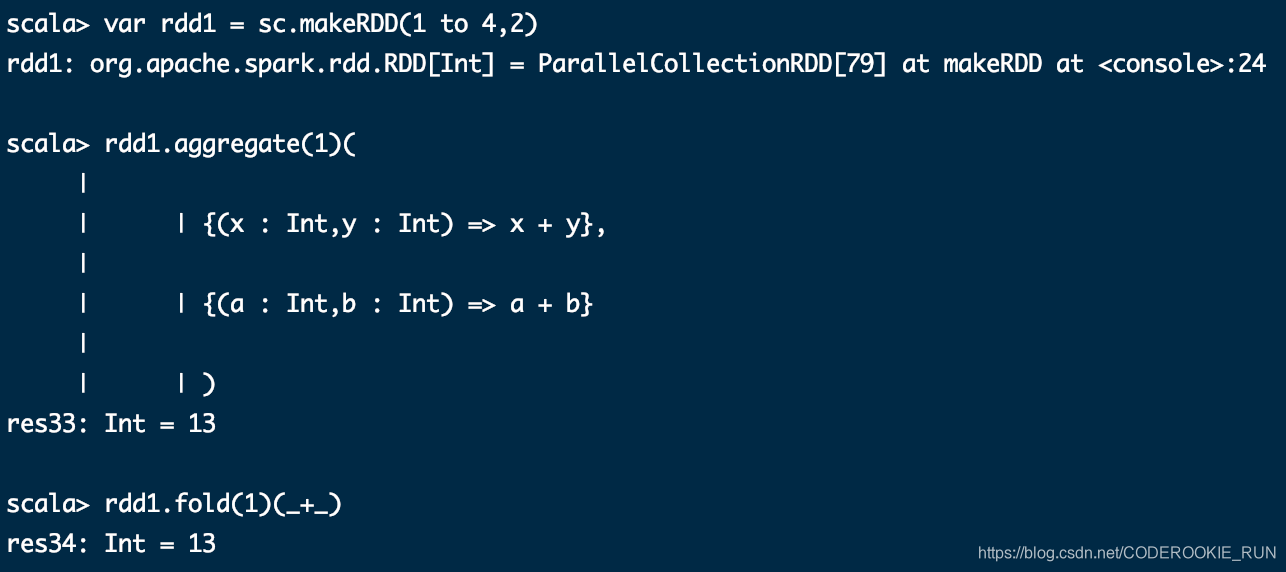
aggregate (zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
fold(num)(func)
countByKey

foreach(func)
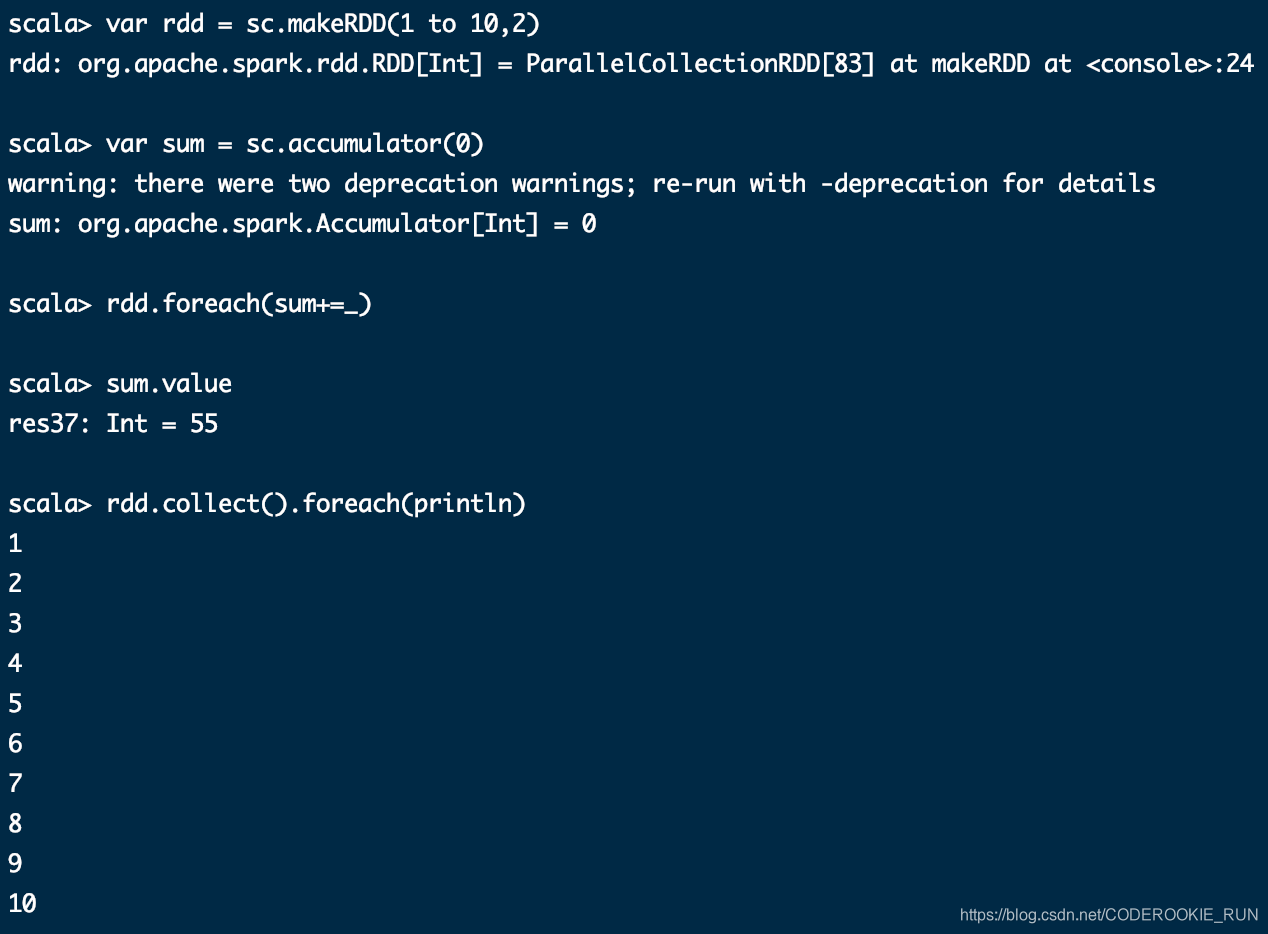
这里没有列出所有的算子,更多算子可以到RDD的源码中查看
【Spark】快来学习RDD的创建以及操作方式吧!的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
- Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- 【Spark】【RDD】初次学习RDD 笔记 汇总
RDD Author:萌狼蓝天 [哔哩哔哩]萌狼蓝天 [博客]https://mllt.cc [博客园]萌狼蓝天 - 博客园 [微信公众号]mllt9920 [学习交流QQ群]238948804 目录 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- SPARK快学大数据分析概要
Spark 是一个用来实现快速而通用的集群计算的平台.在速度方面,Spark 扩展了广泛使用的MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理.在处理大规模数据集时,速 ...
- 【原创】大数据基础之Spark(4)RDD原理及代码解析
一 简介 spark核心是RDD,官方文档地址:https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-di ...
- spark第一篇:RDD Programming Guide
预览 在高层次上,每一个Spark应用(application)都包含一个驱动程序(driver program),该程序运行用户的主函数(main function),并在集群上执行各种并行操作. ...
- Spark 并行计算模型:RDD
Spark 允许用户为driver(或主节点)编写运行在计算集群上,并行处理数据的程序.在Spark中,它使用RDDs代表大型的数据集,RDDs是一组不可变的分布式的对象的集合,存储在executor ...
随机推荐
- Html5移动端弹幕动画实现示例代码
已知20条内容要有弹幕效果,分成三层,速度随机. 先来看看效果: 所以这里不考虑填写生成的.只是一个展现的效果. 如果要看填写生成的,请不要浪费Time 思路 把单个内容编辑好,计算自身宽度,确定初始 ...
- python基础--str.split
string = 'This +is -a /string' process = string.split('-') process1 = string.split('-')[-1]#-1和-2可能存 ...
- 文本文件的合并操作方法 - Python
我们有时候,看到几k的日志文件,一大堆,一个一个打开又很麻烦,少看几个,又担心遗漏,这个时候,如果有一个可以合并所有文本文件的工具就好了. 下面这个代码就可以实现,它不局限于.txt格式,基本上字符型 ...
- python第三方库安装与卸载
一.检查python环境是否正常 python安装完毕并设置环境变量后,可在cmd中运行python查看,显示版本等信息 二.查看已经安装的第三方库 通过pip list可查看已安装的库,以及对应的 ...
- 《Spring In Action》阅读笔记之装配bean
Spring主要装配机制 1.在XML中进行显式配置 2.在Java中进行显式配置 3.隐式的的bean发现机制和自动装配 自动化装配bean Spring从两个角度来实现自动化装配 1.组件扫描:S ...
- 最通俗易懂的Redis发布订阅及代码实战
发布订阅简介 除了使用List实现简单的消息队列功能以外,Redis还提供了发布订阅的消息机制.在这种机制下,消息发布者向指定频道(channel)发布消息,消息订阅者可以收到指定频道的消息,同一个频 ...
- GOLANG 闭包和普通函数的区别
闭包和匿名函数是一回事 闭包使用完毕之后不会自动释放,值依然存在 普通函数调用完毕后,值会自动释放
- wincache 与 zend guard 的冲突
ZendLoader.dll 与wincache.dll 同时开启 问题分析:zend与wincache冲突 解决方法: 关掉wincache: 在php.ini中的 extension=php_w ...
- 利用python画出动态高优先权优先调度
之前写过一个文章. 利用python画出SJF调度图 动态高度优先权优先调度 动态优先权调度算法,以就绪队列中各个进程的优先权作为进程调度的依据.各个进程的优先权在创建进程时所赋予,随着进程的推进或其 ...
- JNI与NDK简析(一)
1 JNI 简介 在Android Framework中,需要提供一种媒介或 桥梁,将Java层(上层)与C/C++层(下层)有机的联系起来,使得他们互相协调完成某些任务.而充当这种媒介的就是Java ...