吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率

,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有
30%的值是缺失的。下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归
和随机梯度上升算法来预测病马的生死。
准备数据:处理被据中的缺失值
因为有时候数据相当昂贵,扔掉和重新获取
都是不可取的,所以必须采用一些方法来解决这个问题。
下面给出了一些可选的做法:

这里选择实数0来替换所有缺失值,恰好能适用于Logistic回归。这样做的直觉在
于 ,我们需要的是一个在更新时不会影响系数的值。回归系数的更新公式如下:

使 用 Logistic
回归方法进行分类并不需要做很多工作,所需做的只是把测试集上每个特征向量乘以最优化方法
得来的回归系数,再将该乘积结果求和,最后输人到sigmoid 函数中即可0 如果对应的sigmoid值
大于0.5就预测类别标签为1,否则为0。
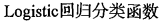
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5:
return 1.0
else:
return 0.0 def colicTest():
frTrain = open('F:\\machinelearninginaction\\Ch05\\horseColicTraining.txt')
frTest = open('F:\\machinelearninginaction\\Ch05\\horseColicTest.txt')
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
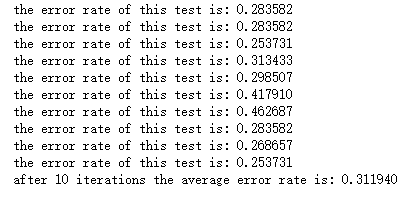
print("the error rate of this test is: %f" % errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))) multiTest()
小结:

吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率的更多相关文章
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 吴裕雄--天生自然python机器学习:使用朴素贝叶斯过滤垃圾邮件
使用朴素贝叶斯解决一些现实生活中 的问题时,需要先从文本内容得到字符串列表,然后生成词向量. 准备数据:切分文本 测试算法:使用朴素贝叶斯进行交叉验证 文件解析及完整的垃圾邮件测试函数 def cre ...
随机推荐
- 1, vm: PropTypes.instanceOf(VM).isRequired
子模块的文件引入父工程对象时,出现红色warning,提示传入的对象类型不是所要求的类型. 思路是父工程引用的JS包和子模块使用的包不是同一个包,解决办法是父工程和子工程都使用同一个包. resolv ...
- vnpy交易接口学习
1.按照github中环境准备要求,配置好环境要求. https://github.com/vnpy/vnpy mongdb安装在D:\Program Files\MongoDB\Server\3.4 ...
- 洛谷 P2719 搞笑世界杯
题目传送门 解题思路: f[i][j]表示买i张A票,j张B票的概率. AC代码: #include<iostream> #include<cstdio> using name ...
- Springboot 2.x 如何解决重复提交 (本地锁的实践)
有没有遇到过这种情况:网页响应很慢,提交一次表单后发现没反应,然后你就疯狂点击提交按钮(12306就经常被这样怒怼),如果做过防重复提交还好,否则那是什么级别的灾难就不好说了... 本文主要是应用 自 ...
- 五年Java经验,面试还是说不出日志该怎么写更好?——日志规范与最佳实践篇
本文是一个系列,欢迎关注 查看上一篇文章可以扫描文章下方的二维码,点击往期回顾-日志系列即可查看所有相关文章 概览 上一篇我们讨论了为什么要使用日志框架,这次我们深入问题的根源,为什么我们需要日志? ...
- 开源PLM软件Aras详解七 在Aras的Method中如何引用外部DLL
在实际的项目中,Aras内部的方法可能并不能完全满足我们,比如Office的组件,就必须引入,那么在Aras内部的Method中,我们如何引入外部Dll文件 首先,我们新建一个Dll文件,简单的Dem ...
- php中const和define的区别
define部分:宏不仅可以用来代替常数值,还可以用来代替表达式,甚至是代码段.(宏的功能很强大,但也容易出错,所以其利弊大小颇有争议.)宏的语法为:#define 宏名称 宏值作为一种建议和一种广大 ...
- Cisco连接失败问题处理
连接公司的VPN时软件一直安装不上,试了几种方法,在此总结. 原文链接:http://www.itsystemadmin.com/error-27850-unable-to-manage-networ ...
- Ribbon使用及其客户端负载均衡实现原理分析
1.ribbon负载均衡测试 (1)consumer工程添加依赖 <dependency> <groupId>org.springframework.cloud</gro ...
- autorclone使用心得
一边使用一边更新. 0x00 SAs最坑的那地方在于,当我新建了一个group,却只能每天添加100个SAs.但是autorclone在本地调用的SAs却有500个,这样每次copy的时候,auto ...