python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列,
看一下单机的流程图:
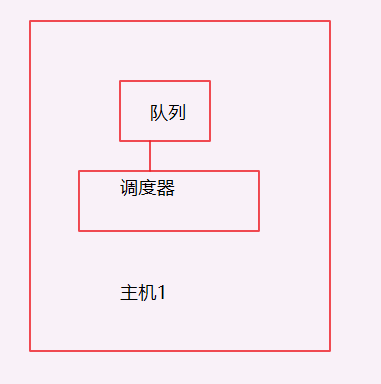
一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点出来了,共享请求队列,看一下架构:

三台主机由一个队列控制,意味着还需要一个主机来控制队列,我们一般来用REDIS来控制队列,形成如下分布式架构
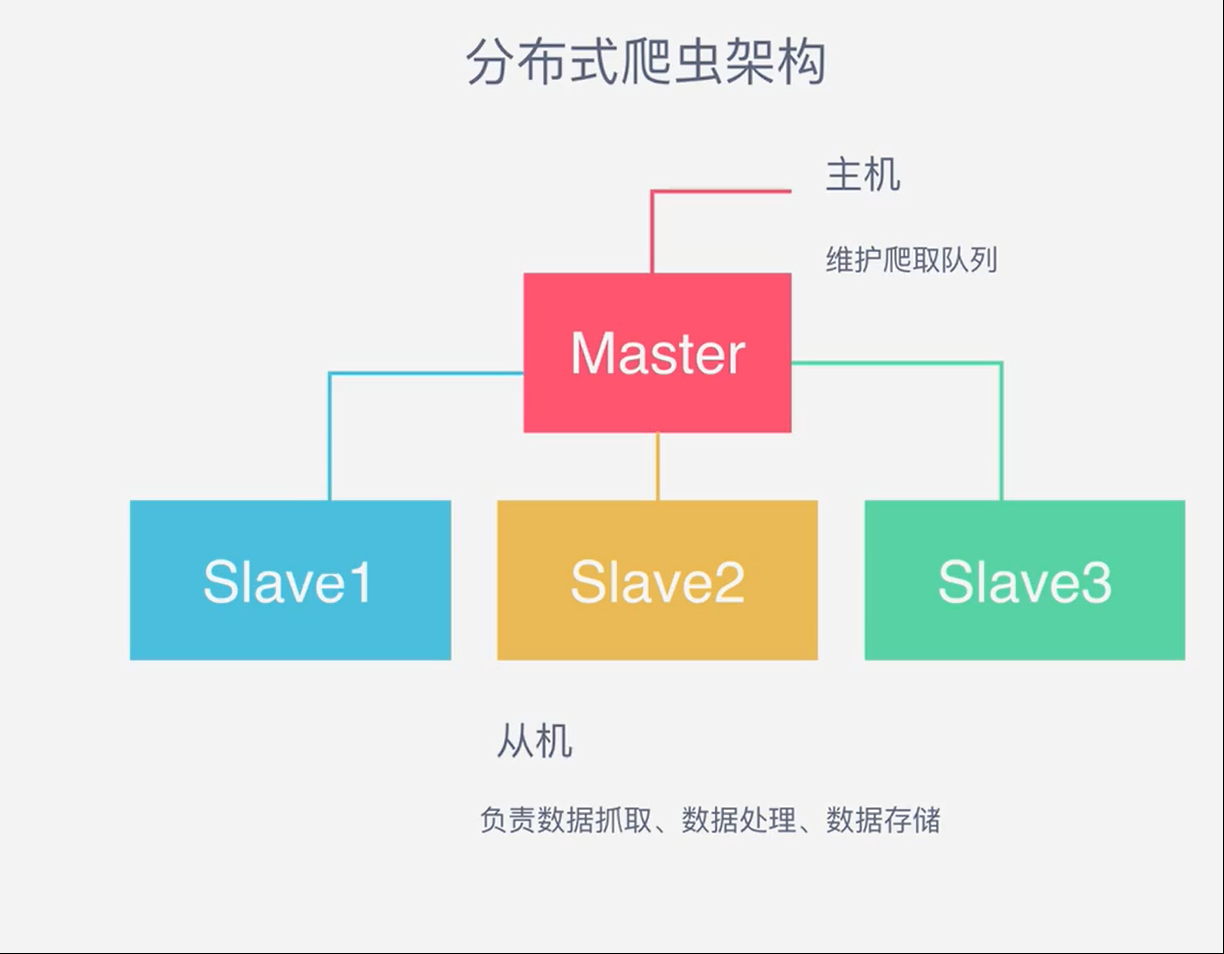
从机抓取,存储主机负责控制队列
SCRAPY_REDIS这个插件解决了SCRAPY不能做分布式爬取的问题
它内部的CONNECTION.PY作为连接MASTER的REDIS
DUPEFILTER.PY用作去重,添加指纹,以及判断功能,现在整个框架了解了,现在该做执行了
python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)的更多相关文章
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 21天打造分布式爬虫-Spider类爬取糗事百科(七)
7.1.糗事百科 安装 pip install pypiwin32 pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl pip install sc ...
- 21天打造分布式爬虫-Crawl类爬取小程序社区(八)
8.1.Crawl的用法实战 新建项目 scrapy startproject wxapp scrapy genspider -t crawl wxapp_spider "wxapp-uni ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下应用pymysql(第三卷)(数据自增-用于爬虫)
在上卷中我说出两种方法进行数据去重自增,第一种就是在数据库的字段中设置唯一字段,二是在脚本语言中设置重复判断再添加(建议,二者同时使用,真正开发中就会用到) 话不多说先上代码 第一步: 确定那一字段的 ...
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
6.1.爬取第一页的职位信息 第一页职位信息 from selenium import webdriver from lxml import etree import re import time c ...
- 21天打造分布式爬虫-requests库(二)
2.1.get请求 简单使用 import requests response = requests.get("https://www.baidu.com/") #text返回的是 ...
随机推荐
- 大数据高可用集群环境安装与配置(03)——设置SSH免密登录
Hadoop的NameNode需要启动集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登录来实现 Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录每台机器,需要将所有 ...
- ftp限制
/etc/hosts.deny /etc/vsftpd/user_list 从2.3.5之后,vsftpd增强了安全检查,如果用户被限定在了其主目录下,则该用户的主目录不能再具有写权限了!如果检查发现 ...
- [Python Cookbook]Pandas: How to increase columns for DataFrame?Join/Concat
1. Combine Two Series series1=pd.Series([1,2,3],name='s1') series2=pd.Series([4,5,6],name='s2') df = ...
- Dart异步编程-future
Dart异步编程包含两部分:Future和Stream 该篇文章中介绍Future 异步编程:Futures Dart是一个单线程编程语言.如果任何代码阻塞线程执行都会导致程序卡死.异步编程防止出现阻 ...
- 素小暖讲JVM:Eclipse运行速度调优
本系列是用来记录<深入理解Java虚拟机>这本书的读书笔记.方便自己查看,也方便大家查阅. 欲速则不达,欲达则欲速! 这两天看了JVM的内存优化,决定尝试一下,对Eclipse进行内存调优 ...
- 浅谈JVM - 内存结构(二)- 虚拟机栈|凡酷
2.1 定义 Java Virtual Machine Stacks(Java虚拟机栈) Java 虚拟机栈描述的是 Java 方法执行的内存模型,用于存储栈帧,是线程私有的,生命周期随着线程启动而产 ...
- nvm安装教程
nvm是一个nodejs的版本管理工具 默认安装位置 C:\Users\userName\AppData\Roaming\nvm x 1 C:\Users\userName\AppData\Ro ...
- css 传数据套路
<input type=hidden> 那么该标签就不会显示 但是我们可以用这个标签储存数据 这是一个利用标签元素隐藏
- 1016D.Vasya And The Matrix#矩阵存在
题目出处:http://codeforces.com/contest/1016/problem/D #include<iostream> #define ll long long int ...
- nginx配置文件说明(包含IP黑名单、代理反射、负载均衡的配置)
先看下nginx配置文件整体结构 图片来源51cto 配置文件及注解: #运行用户 主模块指令,指定Nginx Worker进程运行用户以及用户组,默认由nobody账号运行 user nobody; ...