利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息
一、分析网站内容
本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics”
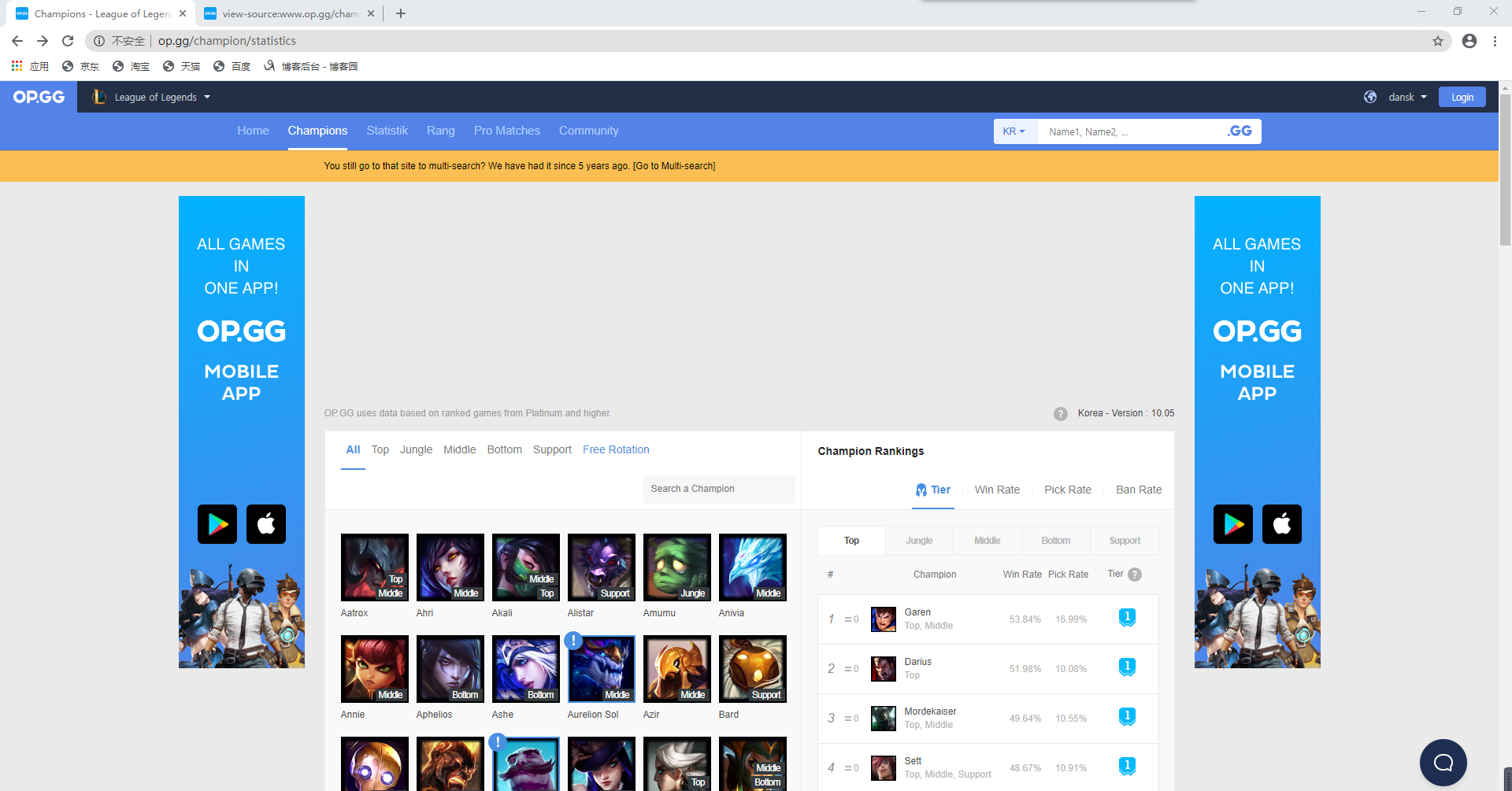
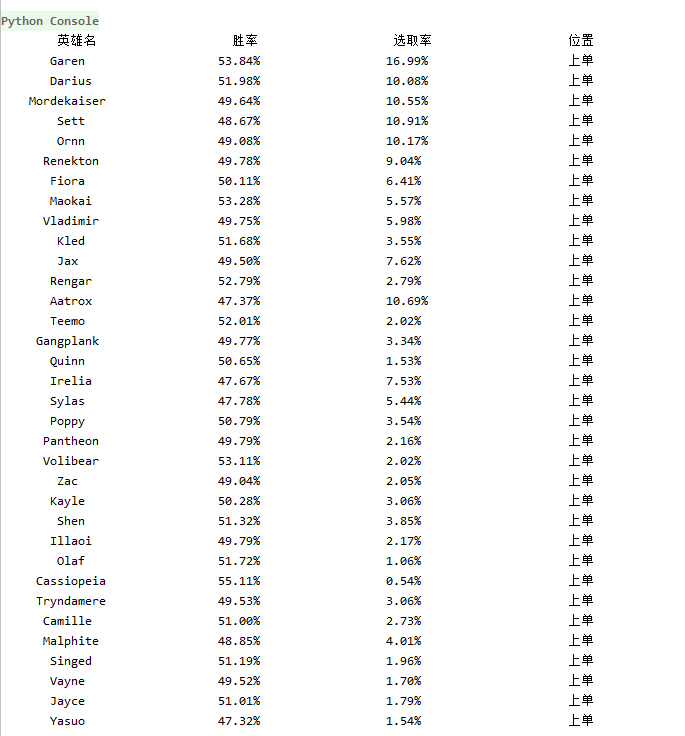
由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单
现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码)。通过查找“53.84%”快速定位Garen所在位置
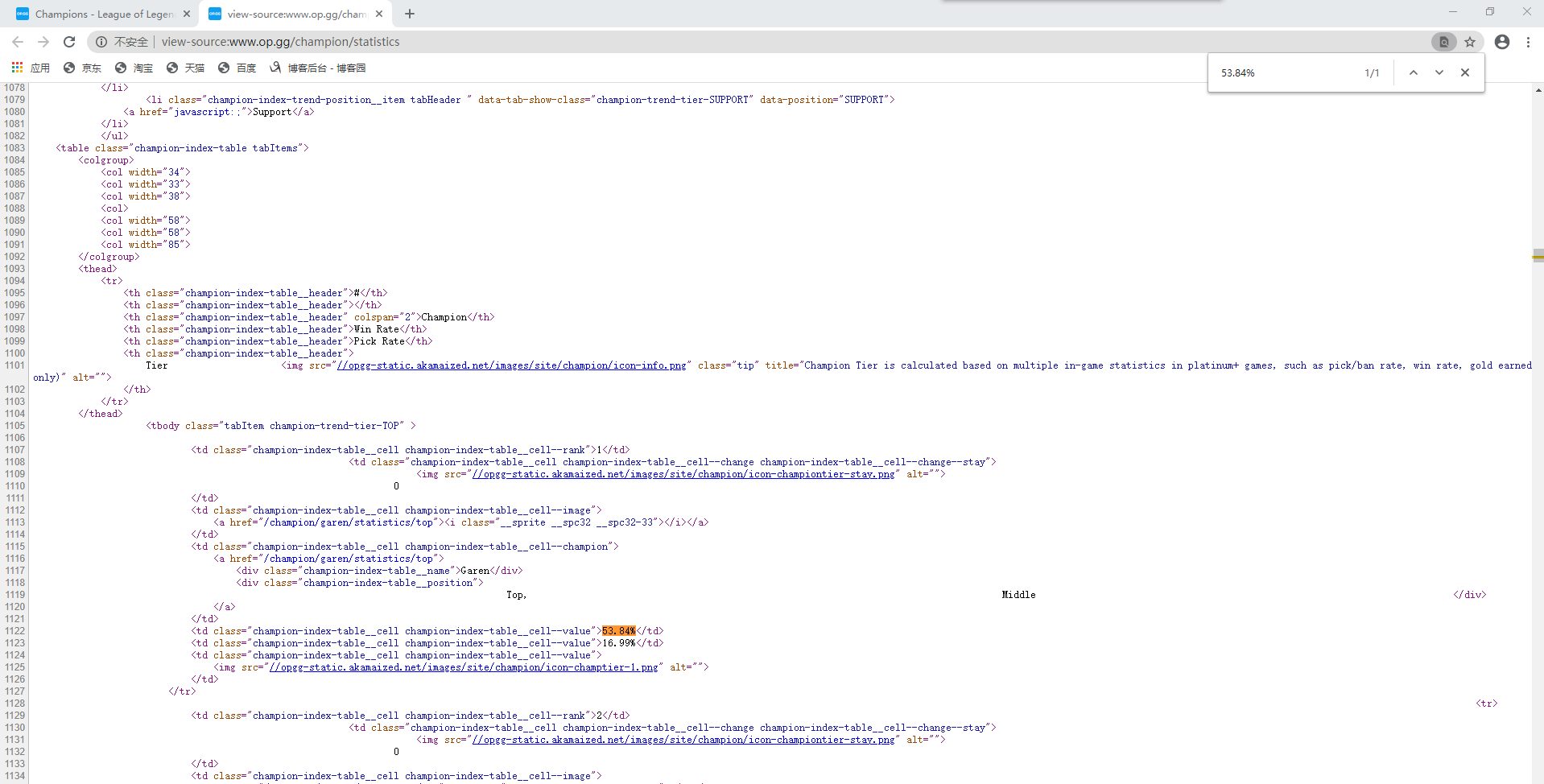
由代码可看出,英雄名、胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tbody标签。
对tbody标签进行查找

代码中共有5个tbody标签(tbody标签开头结尾均有”tbody”,故共有10个”tbody”),对字段内容分析,分别为上单、打野、中单、ADC、辅助信息
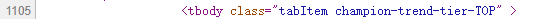

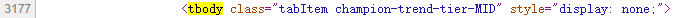

以上单这部分英雄为例,我们需要首先找到tbody标签,然后从中找到tr标签(每一条tr标签就是一个英雄的信息),再从子标签td标签中获取英雄的详细信息
二、爬取步骤
爬取网站内容->提取所需信息->输出英雄数据
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
getHTMLText(url)函数是返回url链接中的html内容
fillHeroInformation(hlist,html)函数是将html中所需信息提取出存入hlist列表中
printHeroInformation(hlist)函数是输出hlist列表中的英雄信息
三、代码实现
1、getHTMLText(url)函数
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
2、fillHeroInformation(hlist,html)函数

以一个tr标签为例,tr标签内有7个td标签,第4个td标签内属性值为"champion-index-table__name"的div标签内容为英雄名,第5个td标签内容为胜率,第6个td标签内容为选取率,将这些信息存入hlist列表中
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
3、printHeroInformation(hlist)函数
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
4、main()函数
网站地址赋值给url,新建一个hlist列表,调用getHTMLText(url)函数获得html文档信息,使用fillHeroInformation(hlist,html)函数将英雄信息存入hlist列表,再使用printHeroInformation(hlist)函数输出信息
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
四、结果演示
1、网站界面信息
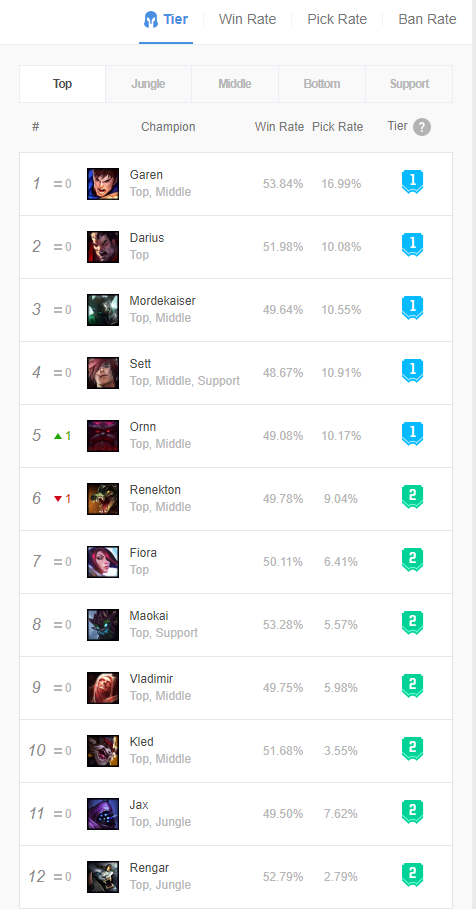
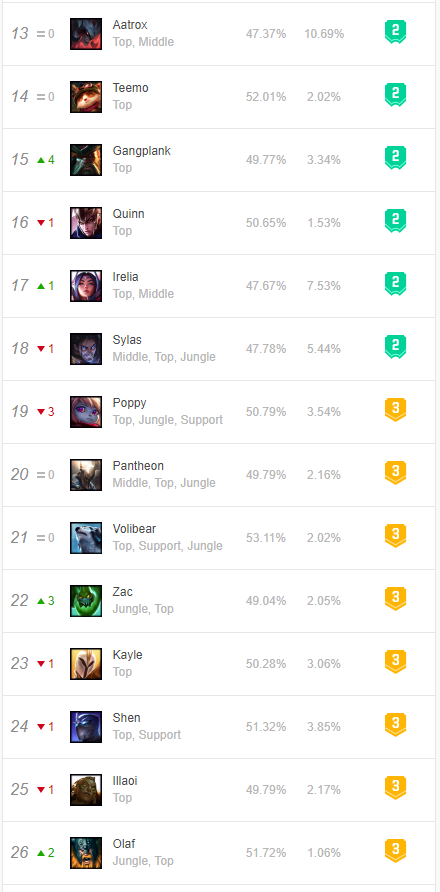

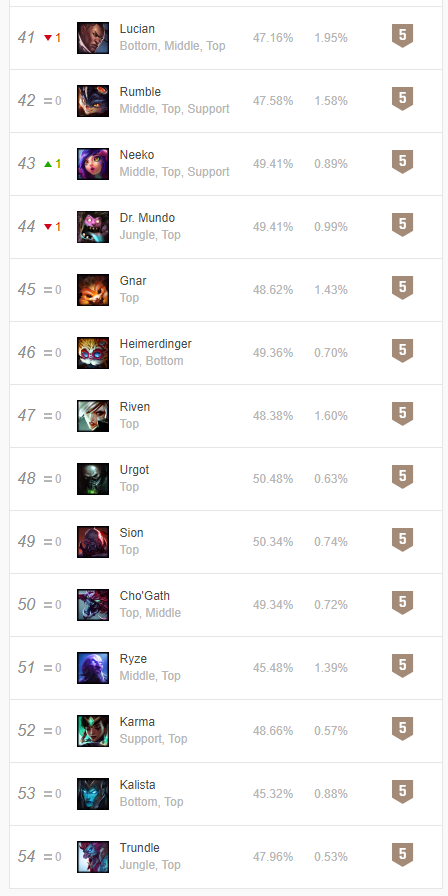
2、爬取结果

五、完整代码
import requests #导入requests库
import bs4 #导入bs4库
from bs4 import BeautifulSoup #导入BeautifulSoup库 def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return "" def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中 def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单")) def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息 main()
如果需要爬取打野、中单、ADC或者辅助信息,只需要修改
fillHeroInformation(hlist,html)函数中的
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children语句,将attrs属性值修改为
"tabItem champion-trend-tier-JUNGLE"、"tabItem champion-trend-tier-MID"、"tabItem champion-trend-tier-ADC"、"tabItem champion-trend-tier-SUPPORT"等即可
转载请声明原作者并附上原文链接!
利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
随机推荐
- Redis实现高并发分布式锁
分布式锁场景在分布式环境下多个操作需要以原子的方式执行首先启一个springboot项目,再引入redis依赖包: <!-- https://mvnrepository.com/artifa . ...
- GIL锁和进程/线程池
GIL锁 1.GIL锁 全局解释器锁,就是一个把互斥锁,将并发变成串行,同一时刻只能有一个线程使用共享资源,牺牲效率,保证数据安全,也让程序员避免自己一个个加锁,减轻开发负担 带来的问题 感觉单核处理 ...
- 【Linux_Shell 脚本编程学习笔记三、分支与循环结构】
if 语句是实际生产工作中最重要且最常用的语句,所以,必须掌握牢固 if 条件语法 1. 单分支机构 if [ 条件 ] then 指令 fi 或 if [ 条件 ]; then 指令 fi ...
- cs231n spring 2017 lecture14 Reinforcement Learning
(没太听明白,下次重新听) 1. 增强学习 有一个 Agent 和 Environment 交互.在 t 时刻,Agent 获知状态是 st,做出动作是 at:Environment 一方面给出 Re ...
- [LC] 129. Sum Root to Leaf Numbers
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number ...
- [LC] 56. Merge Intervals
Given a collection of intervals, merge all overlapping intervals. Example 1: Input: [[1,3],[2,6],[8, ...
- 最简化的DirectX 11开发环境的配置 VS2010
转载自:http://blog.csdn.net/zhmxy555/article/details/7672101 在编写基于DirectX 11的应用程序之前,我们当然需要在IDE中加入Direct ...
- js 函数的防抖(debounce)与节流(throttle)
原文:函数防抖和节流: 序言: 我们在平时开发的时候,会有很多场景会频繁触发事件,比如说搜索框实时发请求,onmousemove, resize, onscroll等等,有些时候,我们并不能或者不想频 ...
- docker 使用:创建nginx容器
在上一节中了解了镜像和容器.对于镜像可以这样的理解,镜像相当于一个光盘,里面刻录了一个系统这个系统已经带有相关的服务了. 容器是通过镜像这个光盘安装的一个操作系统,光盘预加了什么服务,容器就有什么服务 ...
- 企业级rancher搭建Kubernetes(采用rancher管理平台搭建k8s)
一.简介 Rancher简介 来源官方:https://www.cnrancher.com/ Rancher是一个开源的企业级容器管理平台.通过Rancher,企业再也不必自己使用一系列的开源软件去从 ...