cs231n spring 2017 lecture13 Generative Models
1. 非监督学习
监督学习有数据有标签,目的是学习数据和标签之间的映射关系。而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构。
2. 生成模型(Generative Models)
已知训练数据,根据训练数据的分布(distribution)生成新的样例。
无监督学习中的一个核心问题是估计分布。
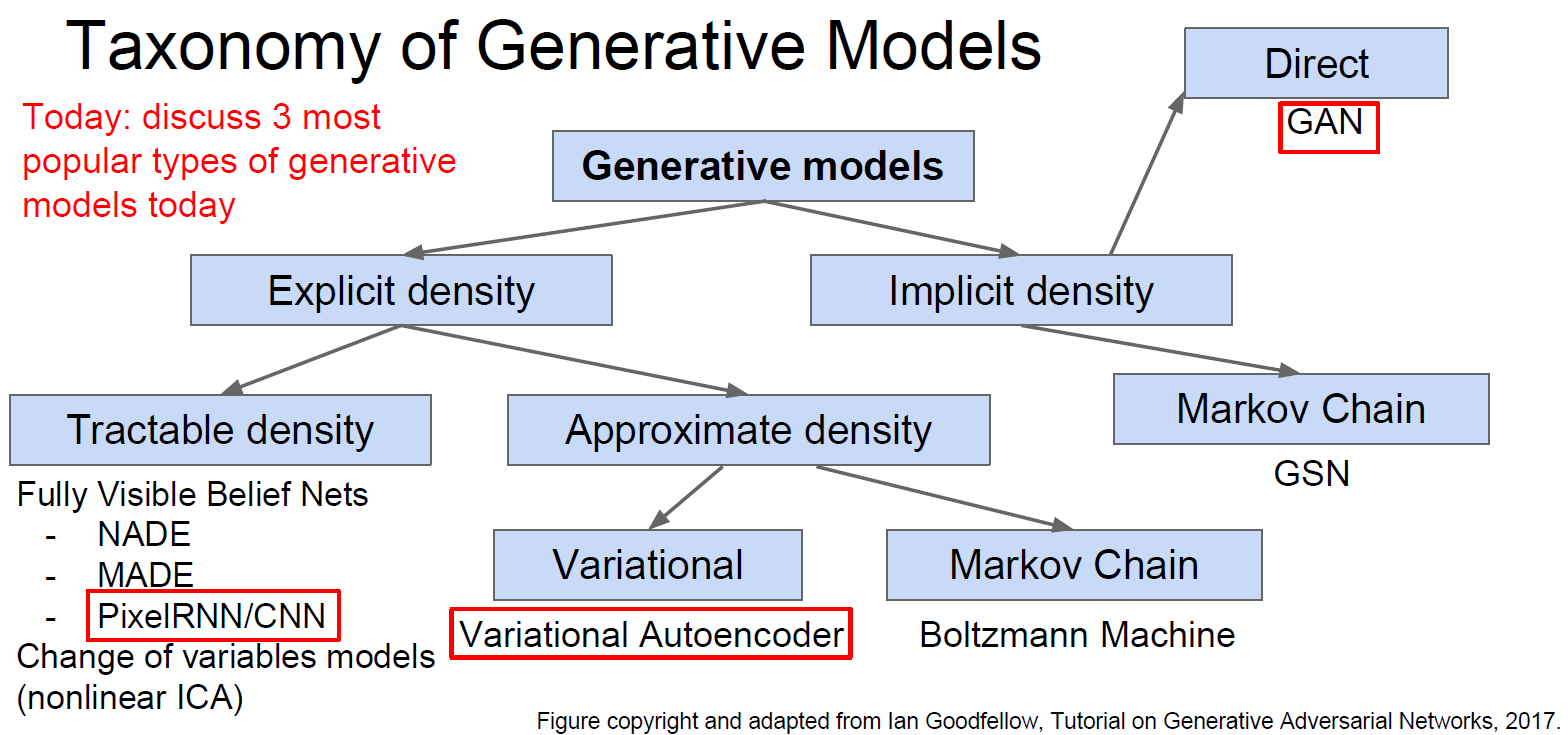
3. PixelRNN 和 PixelCNN
依次根据已知的像素估计下一个像素。

PixelRNN(van der Oord et al. NIPS 2016):利用RNN(LSTM)从角落开始依次生成像素。缺点是非常慢。

PixelCNN(van der Oord et al. NIPS 2016):利用CNN从角落开始依次生成像素。求像素的最大似然估计。比PixelRNN快,但依旧慢。
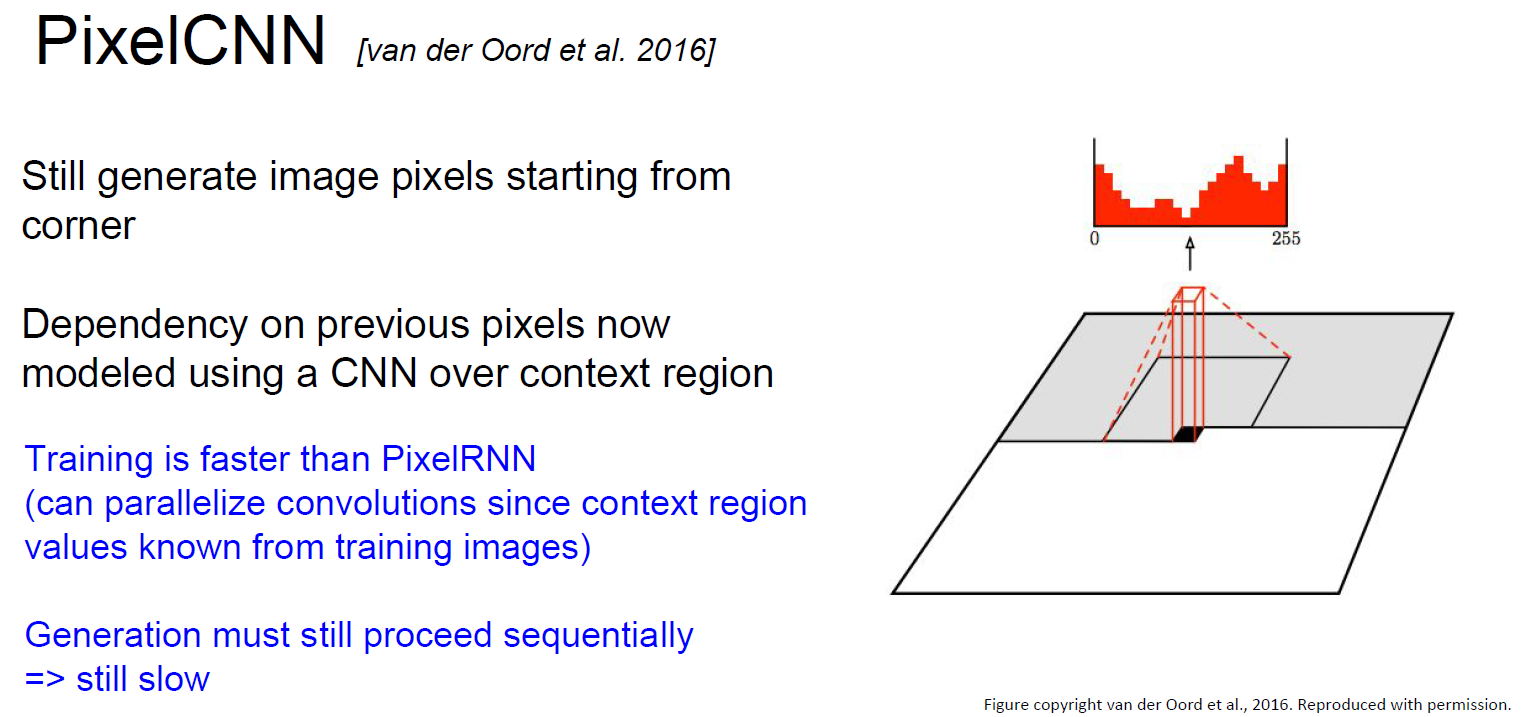
PixelRNN和PixelCNN的优点是可以显式地求出概率分布,并且给出评价尺度(evaluation metric),生成的结果也不错。缺点是慢。改进版本是PixelCNN++(Salimans et al. 2017)。
4. Variational Autoencoders (VAE)
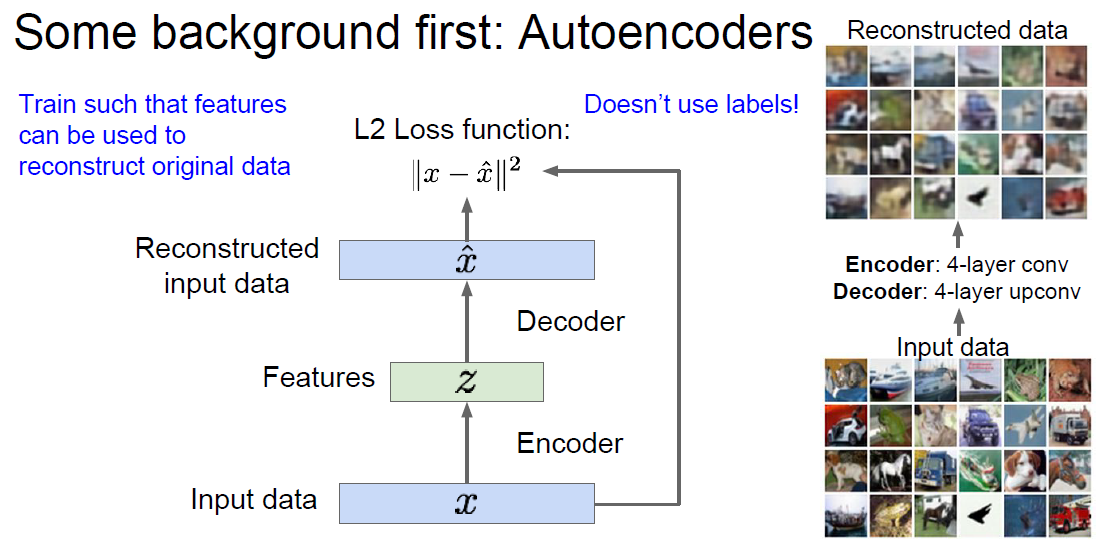
Autoencoder是一种从没有标签的训练数据学习低维度特征(lower-dimensional feature representation)的方法。最开始是用Linear+nonlinearity(sigmoid)的方法,后来人们用深度的全连接层,再后来人们用ReLU CNN。为什么要“低维度特征”?或者说为什么把输入的维度降低?目的是为了获得可靠的、不变的特征。
第一种用法是和监督学习配合使用。在训练阶段,可以再用一个Decoder把低维度特征解码成和输入类似的数据。这样可以建立损失函数。训练完成之后可以把Decoder扔掉,把Encoder出的特征当成某个监督学习的输入,预测出结果,建立Loss function。在有大量没有标签的训练数据和少量有标签的数据的情况下,这样做很有效。图中的 z 叫 “latent factors”。
第二种用法是生成新的数据。对于编码出的 z(“latent factors” )的分布 p(z),可以直接选择简单的概率分布,比如高斯。而对于条件概率 p(x|z),则是比较复杂的,用神经网络来模拟。训练的过程如下图所示,(推导过程完全没听懂。。。)。训练完了之后可以只用Decoder network,渐进地改变z的各个分量(比如z1表示微笑的程度,z2表示头的姿态,则可以生成各种头的姿态各种微笑程度的人脸),生成不同的样例x_hat。
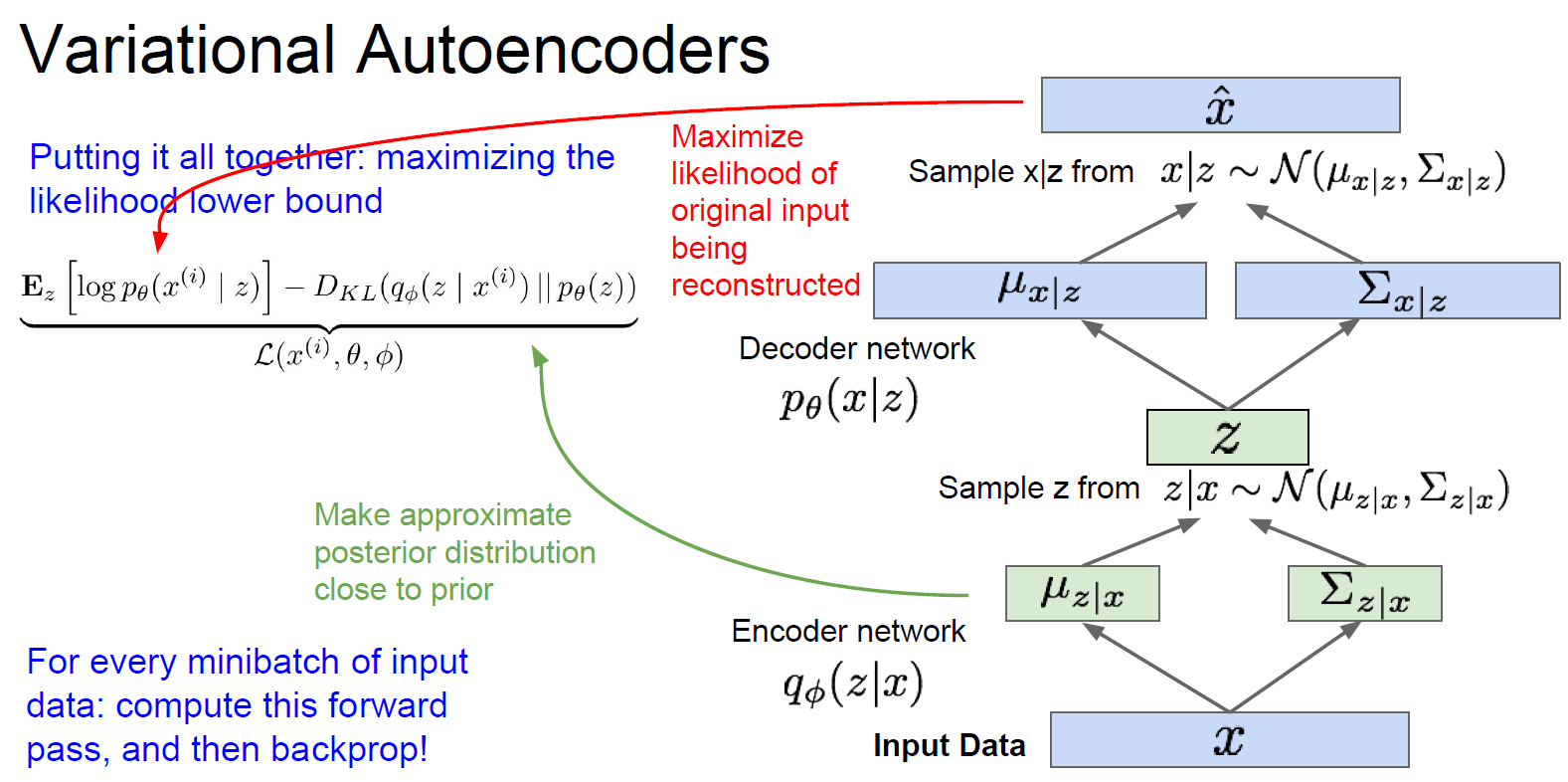
Variational Autoencoders的优点:生成模型的主要方法(principled approach);可以估计q(z|x)(没搞明白这里q是什么。。。),对于其他任务可能是很好的特征描述。缺点:最大化似然估计的下限,而不是直接最大化似然估计,从评估的角度说不如PixelRNN和PixelCNN;相比于GAN,生成的图片比较模糊,质量不高。
5. Generative Adversarial Networks (GAN) (Ian Goodfellow et al., "Generative Adersarial Nets", NIPS 2014)
不考虑显式地描述density function,而是根据对抗直接生成样例。我们没有办法直接从复杂的、高维度的训练集分布中生成样例,那么就先从简单的分布生成样例(比如随机噪音),然后从训练集分布学习把这个简单分布生成的样例转变成(transformation)符合训练集分布。神经网络就是用来描述这个复杂的transformation(神经网络的作用似乎一直就是用来描述高维度、非线性的某种函数、映射、转换等等)。该神经网络的输入是随机噪声,输出是符合训练集分布的样例。
GAN有两个网络,生成网络(generator network)和区分网络(discriminator network),生成网络尽一切努力生成图片欺骗区分网络,区分网络尽一切努力区分原图和生成的图。

具体的训练过程是先优化区分网络k次迭代,再优化生成网络一次迭代,然后不断重复。

训练完成之后,可以丢掉区分网络,只用生成网络来生成样例。
改进方案如下:

2017年是GAN的爆发年,出了成吨的相关研究。生成的样例越来越好。
GAN的优点:效果非常好。缺点:训练的过程不稳定,很需要经验和技巧;不能给出对得density function的估计。
6. 总结:生成模型的对比
PixelRNN和PixelCNN:显式的density model,优化似然函数,效果不错,低效、慢。
Variational autoencoders (VAE):优化似然函数的下限,latent representation很有用,inference queries,生成的图片的质量不够好。
Generative Adversarial Network (GANs):博弈的原理,生成的图片的质量超级好,难训练,no inference queries。
cs231n spring 2017 lecture13 Generative Models的更多相关文章
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 Python/Numpy基础 (1)
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
- cs231n spring 2017 lecture11 Detection and Segmentation
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种“Unpooling”.“Transpose Conv ...
- cs231n spring 2017 lecture9 CNN Architectures
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 Python/Numpy基础
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
随机推荐
- CodeForces - 350B(反向建图,)
B - Resort CodeForces - 350B B. Resort time limit per test 2 seconds memory limit per test 256 megab ...
- UIWindow statusBar消失
1.新建UIWindow 程序崩溃 报无根控制器错误 Xcode7环境下,新建UIWindow需添加rootViewController 2.新建UIWindow后 statusBar消失 Info. ...
- 洛谷 P4342 [IOI1998]Polygon
题目传送门 解题思路: 一道环形dp,只不过有个地方要注意,因为有乘法,两个负数相乘是正数,所以最小的数是负数,乘起来可能比最大值大,所以要记录最小值(这道题是紫题的原因). AC代码: #inclu ...
- dozer
1.简介 dozer是用来两个对象之间属性转换的工具,有了这个工具之后,我们将一个对象的所有属性值转给另一个对象时,就不需要再去写重复的set和get方法了. 2.如果两个类之间的属性有些属性意思一样 ...
- Java线程——线程之间的几点重要说明
在Java中,可以通过配合调用Object对象的wait()方法和notify()方法或notifyAll()方法来实现线程间的通信.在线程中调用wait()方法,将阻塞等待其他线程的通知(其他线程调 ...
- SVN的import和export的使用
import 上传到服务器 export 下载到本地 import这个命令在使用的时候,都要多加一级目录 比如 目录结构是 E:\\1\\2 在1目录下执行import 只会把2目录提交上去,1的 ...
- python——print函数
.print()函数概述 print() 方法用于打印输出,是python中最常见的一个函数. 该函数的语法如下: print(*objects, sep=' ', end='\n', file=sy ...
- Python基础学习五
Python基础学习五 迭代 for x in 变量: 其中变量可以是字符串.列表.字典.集合. 当迭代字典时,通过字典的内置函数value()可以迭代出值:通过字典的内置函数items()可以迭代出 ...
- 哈夫曼编码的理解(Huffman Coding)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种.Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最 ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:多线程队列操作
import tensorflow as tf #1. 定义队列及其操作. queue = tf.FIFOQueue(100,"float") enqueue_op = queue ...