Python笔记⑤爬虫
爬虫的前奏
# 爬虫前奏
# 明确目的
# 找到数据对应的网页
# 分析网页的结果找到数据所在的标签位置
# 模拟HTTP请求,向服务器发送这个请求,获取到服务器返回给我们的HTML
# 用正则表达式提取我们要的数据(名字,人气)
http://longzhu.com/channels/lol?from=left
VSCode中调试代码:
用面向对象来构建爬虫
#断点调试
F5 启动
F10 单步运行
F5 跳断点
F11 进入某一个函数或对象的内部
鼠标悬停在变量上方后会出现变量的详细内容
爬虫分析流程:寻找到一个标签或者标识符,因为我们需要一个标签帮助“定位”抓取的信息
两个原则:
1.寻找哪个作为定位标识符,尽量选择具有唯一标识性的标签
2.尽量寻找接近于提取数据的标签。从需要查找的数据附近寻找
数据提取层级分析及原则
数据提取层级分析
为了分析 名字和人气 所以将它们认为一起的 然后找上层的闭合标签 即找父级标签不能用兄弟标签如video-title


圈红部分
#用正则表达式取得信息
匹配所有字符的方式:
\w\W; \s\S;
[\s\S]*?
[]表示或关系,*表示匹配0次到无限多次,
?表示非贪婪模式。表示只匹配到下个</div>就结束,不然一次就会匹配多个livecard-modal
圆括号表示组的概念,去除圆括号外部内容
通过正则表达式进行提取根节点下的名字
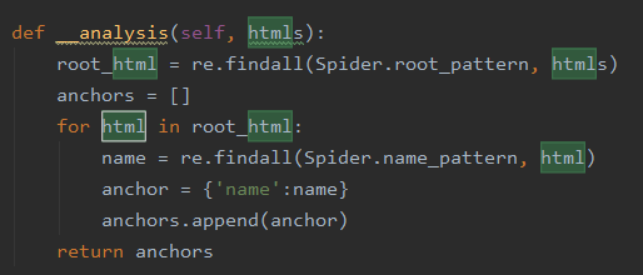
1,定义字典函数 anchor = {key:value},在这里 {'name':name,'number':number}
2,多个anchor需要存入一个列表中,因此定义多个字典的列表 anchors,即anchor单词的复数.
3,在anchors中插入anchor,即 anchors.append(anchor)
4,需要精简分析人数和名字,需要定义此类函数,需用refine函数表示
5,在入口go函数中增加self.__refine(param),这里的param则是anchors,
因此为 self.__refine(anchors)
数据精炼
(这个练习中)数据精炼目的
1.把换行符和空格去掉
2.把列表形式转换成单一字符串
def __refine(self,anchors):
l=lambda anchor:{
'name':anchor['name'][0].strip(),
'number':anchor['number][0]
}
return map(l, anchors)
#列表中每个字典元素的内部的name和number属性又都是一个列表,取出元素,列表就转换成了字符串
#内置函数strip可以去除字符串前后不需要的部分,默认值时空格和换行符(见【内置函数】)
案例总结
go是入口方法,里面展现了数据处理的流程步骤:
1. 提取内容(fetch)
2. 分析内容(analysis)
3. 精炼内容(refine)
4. 业务处理(如sort)
5. 展示方法(show)
这段代码直白,平铺直叙,可读性尚可
而最大的问题在于抵御业务变化的能力太差
如果要换一个不同的视频网站抓取,
代码就基本全部要改
如果要写中大型爬虫,
老师推荐BeautifulSoup库和Scrapy爬虫框架
对于框架,能不用就不用,因为研究框架要花费大量时间,
如果只是小项目,没有必要
应该从解决问题的角度出发
对于爬虫,还有反爬虫,和反反爬虫
而且爬虫只是手段,怎么处理分析爬到的数据同样重要
还有一个问题是ip被封,为了减少这种情况,把抓取的频率设置的小一点。
为了防止被封ip号 可以通过代理ip库来解决
注释的方法
类的注释和方法注释和模块注释是一样的
如: 
单行注释 在代码的上面写上注释 不推荐在代码后方注释

用字典映射代替switch case语句--(键值)
一,用原始的字典访问方式,不能解决default,也不能解决代码块的问题
1,键--对应case
2,值--对应的简单赋值语句
二,使用内置方法get(),第二个参数返回默认值(即key不存在时),解决默认值问题,但代码块问题也没能解决
三,使用函数式编程,解决case语句里面多个语句的问题
Switch case的解决方式

字典的解决方式

Python笔记⑤爬虫的更多相关文章
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
随机推荐
- 找不到方法:'System.Net.Http.HttpRequestMessage System.Web.Http.Controllers.HttpActionContext.get_Request()'
出现这种情况一般是引用了.net standard 库解决方案1:在web.config 文件中增加如下节点 <dependentAssembly> <assemblyIdentit ...
- linux文件或文件夹常见操作,排查部署在linux上程序问题常用操作
创建文件夹 mkdir [-p] DirName [ 在工作目录下,建立一个名为 A 新的子目录 : mkdir A 在工作目录下的 B目录中,建立一个名为 T 的子目录: 若 B 目录不存在,则 ...
- C# 将DataGridView中显示的数据导出到Excel(.xls和.xlsx格式)—NPOI
前言 https://blog.csdn.net/IT_xiao_guang_guang/article/details/104217491 本地数据库表中有46785条数据,测试正常 初次运行程 ...
- Django中的分页操作、form校验工具
批量插入数据 后端: def fenye(request): book_list=[] for i in range(100): book_list.append(models.Book(title= ...
- Dictionary-Guided Editing Networks for Paraphrase Generation解读
过程:输入->检索->编码->解码 解释:检索:输入一句话x,首先从PPDB中检索出M * 10 个释义对,并排序,记为x的本地字典: 编码:将所有的释义对编码为向量,单字转为字向量 ...
- Linux 内核内存池
内核中经常进行内存的分配和释放.为了便于数据的频繁分配和回收,通常建立一个空闲链表——内存池.当不使用的已分配的内存时,将其放入内存池中,而不是直接释放掉. Linux内核提供了slab层来管理内存的 ...
- INCA二次开发-INCACOM
1.INCA介绍 INCA是常用的汽车ECU测试和标定的,广泛应用于动力总成等领域.INCA提供了丰富的接口,供用户自动化.定制化.本公众号通过几篇文章,介绍下一些二次开发的方法,本篇介绍INCA-C ...
- 02-Spring的IOC示例程序(通过id获取对象)
*******通过IOC容器创建id对象并为属性赋值******** 整体结构: ①创建一个java工程 ②导包 ③创建log4j.properties日记配置文件 # Global logging ...
- December 31st, Week 53rd Tuesday, 2019
Nothing comes from nothing. 天下没有免费的午餐. Nothing comes from nothing, and in some cases, even something ...
- 【代码学习】PYTHON迭代器
一.迭代器 迭代是访问集合元素的一种方式.迭代器是一个可以记住遍历的位置的对象.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 二.可迭代对象 以直接作用于 ...