hadoop地址配置、内存配置、守护进程设置、环境设置
1.1 hadoop配置
hadoop配置文件在安装包的etc/hadoop目录下,但是为了方便升级,配置不被覆盖一般放在其他地方,并用环境变量HADOOP_CONF_DIR指定目录。
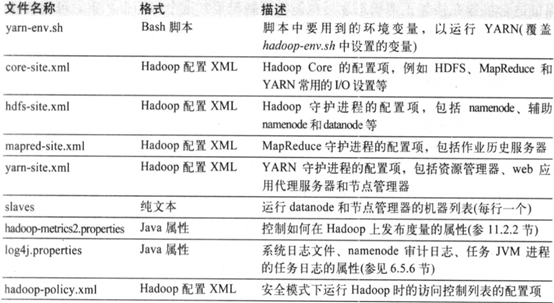
1.1.1 配置管理
集群中每个节点都维护一套配置文件,并由管理员完成文件的同步工作。集群管理工具Cloudera Manage和Apache Ambari可以在集群间传递修改信息。所有机器采用同一套配置文件,简单,但是如果机器的配置不同时,同一套配置文件不适合。Chef、Puppet、CFEngine和Bcfg2工具可以为每一台集群单独维护配置文件。尽量用工具,不用脚本,因为脚本无法感知异常状态。
1.1.2 环境设置
(1)mapred-env.sh和yarn-env.sh文件中配置的变量值会覆盖hadoop-env.sh文件中的变量。hadoop-env.sh文件的内容如下:
|
配置选项 |
说明 |
|
export JAVA_HOME=${JAVA_HOME} |
JAVA_HOME环境变量配置jdk路径 |
|
#export JSVC_HOME=${JSVC_HOME} |
配置jsvc路径,jsvc是一些库和应用程序,让java程序在linux环境下能更简单的运行,提供root权限的授权操作,需要运行安全节点,指定授权端口和授权协议。如果SASL(Simple Authentication and Security Layer)默认不用授权,可以不设置。 |
|
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} |
配置文件路径,默认HADOOP_CONF_DIR 没有值时,会赋予默认值/etc/hadoop。一般把hadoop包中的文件复制到别处,设置为复制到的路径,避免hadoop升级覆盖配置文件。 |
|
#export HADOOP_HEAPSIZE= |
# 内存堆大小单位 MB. 默认 1000M.yarn-env.sh文件中YARN_RESOURCEMANAGER_HEAPSIZE,会覆盖资源管理器的堆大小。-Xmx2000m表示分配2000MB的内存。 |
|
#export HADOOP_NAMENODE_INIT_HEAPSIZE="" |
Namenode初始化堆大小,默认1000M |
|
# export HADOOP_JAAS_DEBUG |
设置JAAS(Java Authentication Authorization Service,Java验证和授权API)绑定、开启Kerberos 安全认证, |
|
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" |
使用ip4,禁用ip6 |
|
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" |
Namenode的日志参数设置 |
|
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" |
Datanode的日志参数设置 |
|
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" |
第二namenode的日志参数配置 |
|
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" |
|
|
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" |
NFS(Network File System)网络文件系统设置 |
|
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" |
这个是在HDFS格式化时需要的JVM配置,也就是执行hdfs namenode -format时的JVM配置 |
|
export HADOOP_PID_DIR=${HADOOP_PID_DIR} |
Pid文件保存的路径,默认是./tmp |
|
export HADOOP_IDENT_STRING=$USER |
一个指向hadoop. $USER用户名的字符串 |
|
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} |
如果使用授权端口,这个必须配置,提供数据转换协议的授权。如果使用SASL授权方式,则不能设置,注释掉。 |
|
export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER |
设置系统日志的路径 |
(2)namenode会在内存中维护所有文件的数据块的引用,会占用很大的内存;数据块的个数=(集群节点数*节点磁盘空间)/(数据块大小*每个数据块的备份数),200个节点的集群,每个节点24TB,数据块大小为128MB,复本数量是3,则数据引用的个数=(200*24*1024*1024)/(128*3)=13107200个数据引用,这些引用需要占用多大内存,可以通过hadoop-env.sh的HADOOP_NAMENODE_OPTS来设置。
(3)系统日志路径通过export HADOOP_LOG_DIR= ${HADOOP_LOG_DIR}/$USER来设置,分为.log日志和.out标准输出和错误日志。
1.1.3 hadoop守护进程的关键属性
守护进程的配置信息可以访问该进程的web服务器conf界面http://resource-manager-host:8088/conf表示资源管理器当前的配置。
(1) HDFS
运行HDFS需要指定一台机器作为namecode的地址,core-site.xml文件中属性fs.defaultFS配置文件系统的uri,ip和端口号。例如hdfs://localhost:9000。
coree-site.xml配置文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/hadoop/hadoop-2.8.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop/hadoop-2.8.3/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop/hadoop-2.8.3/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>


(2) yarn属性设置
yarn-site.xml用于配置资源管理器的属性,需要设置运行资源的管理器的主机名、地址。
yarn.nodemanager.local-dirs属性用来指定mapreduce函数的中间数据的输出路径,包括map输出,可能输出非常大,目录空间要足够大。为了提高磁盘IO操作的效率,设置多个磁盘上的目录。
shuffle服务是将map任务的输出发送给reduce任务。需要将yarn-site.xml文件中属性yarn.nodemanager.aux-services设置mapreduce_shuffle来显示启用mapreduce的shuffle句柄。

(3) yarn和mapreduce中的内存设置
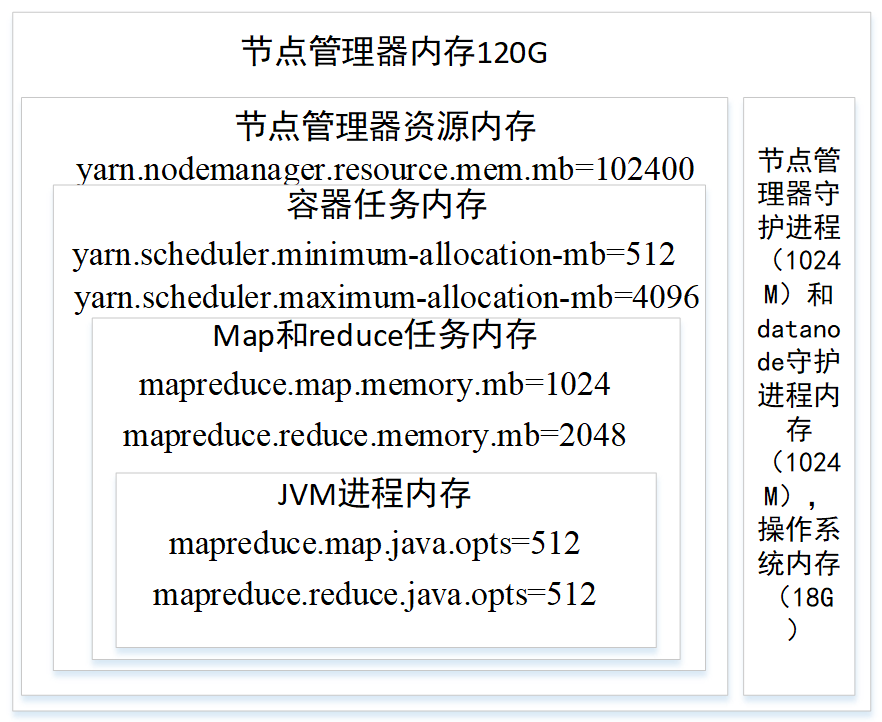
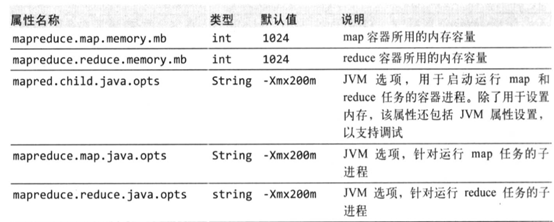
节点管理从内存池分配内存,节点管理器的内存要用于运行节点管理器守护进程和datanode守护进程各需要1000M内存和操作系统内存,剩下的内存则分配给节点上作业的内存(yarn.nodemanager.resource.memory-mb设置分配给容器的总内存,默认8092)。可以通过设置任务容器(mapreduce.map.memory.mb和mapreduce.reduce.memory.mb)的内存使用量和java进程的堆大小(mapred.child.java.opts, mapreduce.map.java.opts, mapreduce.reduce.java.opts)来控制作业的内存。mapreduce.map.memory.mb默认是1024M,节点管理器会分配1024M的容器,JVM会占用容器的200M内存(-Xmx200m配置的是最大JVM进程堆内存),如果容器中内存使用量超过1024,则任务会被终止。yarn.nodemanager.vmem-pmem-ratio(默认2.1)表示虚拟内存与物理内存的比例。容器的物理内存是1024,则最多使用的虚拟内存是1024*2.1=21150.4M。虚拟内存的使用量超过这个值,也会终止任务。
还可以通任务的内存计数器来统计内存使用量PHYSICAL_MEMORY_BYTES,VIRTUAL__MEMORY_BYTES和COMMITED_HEAP_BYTES。
(4) YARN和mapreduce的CPU设置
yarn.nodemanager.resource.cpuvcores设置分配给容器的核数量(不包括nodemanager和datanode守护进程的核数)。mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcores分别设置map和reduce任务的核数量,默认1。
(5) 内存和CPU配置实例
现在有个32核。120G内存的机器。要怎么配置内存和CPU呢?
nodemanage和datanode守护进程各占一个核,守护进程内存各一个G。操作系统占用2核,内存占18G。剩下的28核和100G内存用于任务容器。
yarn.nodemanager.resource.mem.mb=102400
yarn.nodemanager.resource.cpuvcores=28
单个容器任务最小内存分配和最大内存分配属性设置为512M和4096M,最小内存值可以计算一个节点最大Container数量。
yarn.scheduler.minimum-allocation-mb=512
yarn.scheduler.maximum-allocation-mb=4096
然后给每个map任务和reduce任务设置内存上限和cpu分配,内存范围要在容器的内存范围内(512~4096)
mapreduce.map.cpu.vcores=1
mapreduce.reduce.cpu.vcores=2
mapreduce.map.memory.mb=1024
mapreduce.reduce.memory.mb=2048
然后在map和reduce任务中的JVM进程设置内存,JVM内存要小于map和reduce的任务内存mapred.child.java.opts总的设置,也可以用mapreduce.map.java.opts和mapreduce.reduce.java.opts分别设置。
mapred.child.java.opts=512
mapreduce.map.java.opts=512
mapreduce.reduce.java.opts=512
1.1.4 hadoop守护进程的地址和端口
hadoop守护进程一般有两个服务器,RPC服务器支持进程间通信。HTTP服务器则提供与用户的交互的web页面。
(1)RPC服务器设置


(2)HTTP服务器地址设置


地址配置决定了服务器绑定的地址,同时客户端和集群中的其他机器可以通过这个地址链接服务器通讯。将yarn.resourcemananger.hostname设置为主机名或IP地址,yarn.resourcemanager.bind-host设置为0.0.0.0,这样既能节点管理器和客户端端可以通过hostname去解析地址,确定位置,又可以确保资源管理器能够与机器上的所有地址绑定。
datanode运行TCP/IP服务器支持块传输,由属性dfs.datanode.adress设置;默认0.0.0.0:50010。
1.1.5 hadoop的其他属性设置
(1) 集群成员
为了方便添加和移除节点,dfs.hosts属性记录作为datanode加入集群的机器列表。属性yarn.resourcemanager.nodes.include-path记录作为节点管理器加入集的机器列表。dfs.hosts.exclude和yarn.resourcemanager.nodes.exclude-path指向解除的机器列表。
(2) IO缓冲区
core-site.xml中io.file.buffer.size属性来设置缓冲区大小,128kb常用。
(3) 块大小
hdfs-site.xml中dfs.blocksize设置HDFS的块大小,默认128M。
(4) 保留存储空间
计划将部分空间留给非HDFS,设置dfs.datanode.du.reserved设置保留空间。
(5) 回收站
core-site.xml中的fs.trash.interval设置回收站是否有效。默认0无效。trash类删除时会返回false。回收站有效时,shell命令删除的文件才会放入回收站(home目录下的.Trash目录),程序删除的文件直接删除,除非用trash类删除也会放入回收站。HDFS会自动删除超过时限的文件文件,其他文件系统不能,需要执行手动执行hadoop fs –expunge 命令来删除超过最小时限的文件。Trash.expunge()也具备这样的的功能。
(6) 慢启动reduce
调度器会一直等待直到map完成5%,才会调度reduce任务,可以将mapreduce.job.reduce.slowstart.completemaps的值设置为0.8,map完成80%才调度reduce任务。
(7) 短回路本地读
客户端和datanode在同一个几几节点上,则绕过TCP网路通讯,直接从磁盘中读取数据。dfs.client.read.shortcircuit设置为true。
hadoop地址配置、内存配置、守护进程设置、环境设置的更多相关文章
- 【Redis】redis开机自启动、设置守护进程、密码设置、访问权限控制等安全设置(redis默认端口6379)
一.redis设置开机自启动:centOS: 1.修改redis.conf中daemonize为yes,确保守护进程开启,也就是在后台可以运行. (守护进程:孤儿进程:独立于终端而存在的进程,不会因为 ...
- mysql性能优化之服务器参数配置-内存配置
MySQL服务器参数介绍 MySQL获取配置信息路径 命令行参数 mysqld_safe --datadir=/data/sql_data 配置文件 mysqld --help --verbose | ...
- linux系统添加环境变量,node.js forever 守护进程添加环境变量
1.node.js 守护进程组件 forever 安装 npm install forever -g 安装完成后截图: 2.安装完成后在控制台输入 forever 出现 -bash: forever: ...
- R语言环境变量的设置 环境设置函数为options()
环境设置函数为options(),用options()命令可以设置一些环境变量,使用help(options)可以查看详细的参数信息. 1. 数字位数的设置,options(digits=n),n一般 ...
- centos通过Supervisor配置.net core守护进程
安装Supervisor easy_install supervisor 生成默认配置文件 echo_supervisord_conf > /etc/supervisord.conf 生成的配置 ...
- Supervisor安装与配置(非守护进程管理工具)
http://blog.csdn.net/xyang81/article/details/51555473
- Linux+Nginx+Asp.net Core及守护进程部署
上篇<Docker基础入门及示例>文章介绍了Docker部署,以及相关.net core 的打包示例.这篇文章我将以oss.offical.site站点为例,主要介绍下在linux机器下完 ...
- linux守护进程编写实践
主要参考:http://colding.bokee.com/5277082.html (实例程序是参考这的) http://wbwk2005.blog.51cto.com/2215231/400260 ...
- 守护进程与Supervisor
博客链接:http://www.cnblogs.com/zhenghongxin/p/8676565.html 消息队列处理后台任务带来的问题 在系统稍微大些的时候,我们经常会用到消息队列(实现的方式 ...
- [Linux] 守护进程和守护线程
对于JAVA而言,一般一个应用程序只有一个进程——JVM.除非在代码里面另外派生或者开启了新进程. 而线程,当然是由进程开启的.当开启该线程的进程离开时,线程也就不复存在了. 所以,对于JAVA而言, ...
随机推荐
- Hibernate一级缓存Session和对象的状态
建议看原文:https://blog.csdn.net/qq_42402854/article/details/81461496 一.session简介 首先,SessionFactor ...
- 新年在家学java之基础篇-参数&修饰符&构造器
可变参数 不知道可能给方法传递多少个参数时使用这个方法 public void printInfo (String[] args) --可以定义一个数组,在调用这个方法适合赋值给一个数组 public ...
- 24)PHP,数据库的基本知识
(1)数据库操作的基本流程: • 建立连接(认证身份) • 客户端向服务器端发送sql命令 • 服务器端执行命令,并返回执行的结果 • 客户端接收结果(并显示) • 断开连接 (2)php中操作数据库 ...
- Linux 设置开机启动项的几种方法
方法一:编辑rc.loacl脚本 Ubuntu开机之后会执行/etc/rc.local文件中的脚本. 所以我们可以直接在/etc/rc.local中添加启动脚本. $ vim /etc/rc.loca ...
- Exchange Online 权限管理
在Exchange管理中心,通过权限管理可为管理员.普通用户以及Outlook Web App分别制定不同的权限和策略,以满足精细化分工或差异化角色的需要. 一.管理角色组 组织管理者使用角色组来向管 ...
- OneDrive for Business
一.界面介绍 1.在Office 365主页 点击“OneDrive”登陆 2.进入OneDrive,可对文档进行存储.同步并共享文档. 3.点击,可对文档进行编辑.分享.重命名等操作 二.文档同步 ...
- python语法基础-函数-迭代器和生成器-长期维护
############### 迭代器 ############## """ 迭代器 这是一个新的知识点 我们学习过的可以迭代的对象有哪些? list str ...
- django框架进阶-form组件-长期维护
################## form组件做了什么事情? ####################### 之前web开发的模式,以注册为例 1,要有一个注册页面,然后有一个f ...
- GitHub之初始化
1.github上新建repository. 2.本地 mkdir git-init-demo. 3.cd git-init-demo. 4.git clone https://github.com/ ...
- FPGA的存储方式大全
好的时序是通过该严密的逻辑来实现的.http://blog.csdn.net/i13919135998/article/details/52117053介绍的非常好 有RAM(随机存储器可读可写)RO ...