深入解析Dropout——基本思想:以概率P舍弃部分神经元,其它神经元以概率q=1-p被保留,舍去的神经元的输出都被设置为零
深度学习网络大杀器之Dropout——深入解析Dropout
摘要: 本文详细介绍了深度学习中dropout技巧的思想,分析了Dropout以及Inverted Dropout两个版本,另外将单个神经元与伯努利随机变量相联系让人耳目一新。
过拟合是深度神经网(DNN)中的一个常见问题:模型只学会在训练集上分类,这些年提出的许多过拟合问题的解决方案;其中dropout具有简单性并取得良好的结果:
Dropout
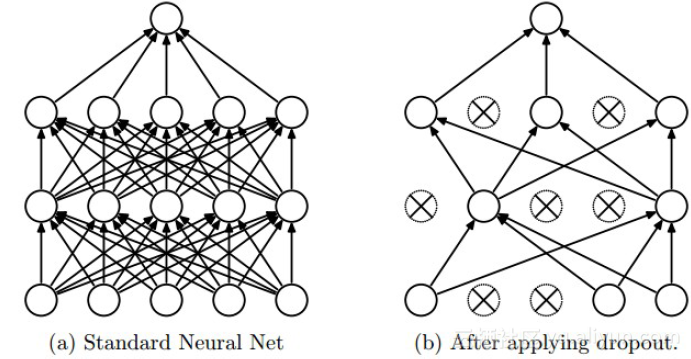
上图为Dropout的可视化表示,左边是应用Dropout之前的网络,右边是应用了Dropout的同一个网络。
Dropout的思想是训练整体DNN,并平均整个集合的结果,而不是训练单个DNN。DNNs是以概率P舍弃部分神经元,其它神经元以概率q=1-p被保留,舍去的神经元的输出都被设置为零。
引述作者:
在标准神经网络中,每个参数的导数告诉其应该如何改变,以致损失函数最后被减少。因此神经元元可以通过这种方式修正其他单元的错误。但这可能导致复杂的协调,反过来导致过拟合,因为这些协调没有推广到未知数据。Dropout通过使其他隐藏单元存在不可靠性来防止共拟合。
简而言之:Dropout在实践中能很好工作是因为其在训练阶段阻止神经元的共适应。
Dropout如何工作
Dropout以概率p舍弃神经元并让其它神经元以概率q=1-p保留。每个神经元被关闭的概率是相同的。这意味着:
假设:
h(x)=xW+b,di维的输入x在dh维输出空间上的线性投影;
a(h)是激活函数
在训练阶段中,将假设的投影作为修改的激活函数:
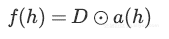
其中D=(X1,...,Xdh)是dh维的伯努利变量Xi,伯努利随机变量具有以下概率质量分布:
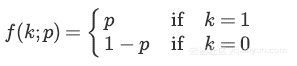
其中k是可能的输出。
将Dropout应用在第i个神经元上:
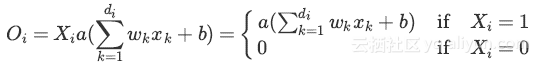
其中P(Xi=0)=p
由于在训练阶段神经元保持q概率,在测试阶段必须仿真出在训练阶段使用的网络集的行为。
为此,作者建议通过系数q来缩放激活函数:
训练阶段: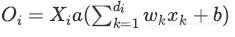
测试阶段: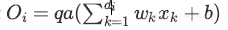
Inverted Dropout
与dropout稍微不同。该方法在训练阶段期间对激活值进行缩放,而测试阶段保持不变。
倒数Dropout的比例因子为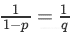 ,因此:
,因此:
训练阶段: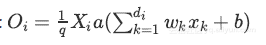
测试阶段: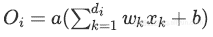
Inverted Dropout是Dropout在各种深度学习框架实践中实现的,因为它有助于一次性定义模型,并只需更改参数(保持/舍弃概率)就可以在同一模型上运行训练和测试过程。
一组神经元的Dropout
n个神经元的第h层在每个训练步骤中可以被看作是n个伯努利实验的集合,每个成功的概率等于p。
因此舍弃部分神经元后h层的输出等于:
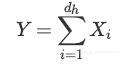
因为每一个神经元建模为伯努利随机变量,且所有这些随机变量是独立同分布的,舍去神经元的总数也是随机变量,称为二项式:
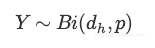
n次尝试中有k次成功的概率由概率质量分布给出:
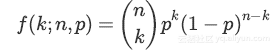
当使用dropout时,定义了一个固定的舍去概率p,对于选定的层,成比例数量的神经元被舍弃。
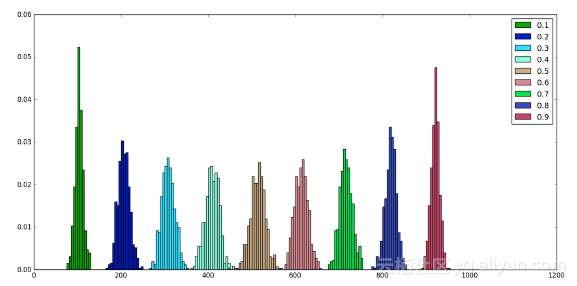
从上图可以看出,无论p值是多少,舍去的平均神经元数量均衡为np:
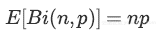
此外可以注意到,围绕在p = 0.5值附近的分布是对称。
Dropout与其它正则化
Dropout通常使用L2归一化以及其他参数约束技术。正则化有助于保持较小的模型参数值。
L2归一化是损失的附加项,其中λ是一种超参数、F(W;x)是模型以及ε是真值y与和预测值y^之间的误差函数。
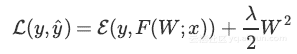
通过梯度下降进行反向传播,减少了更新数量。
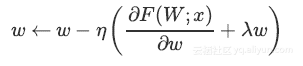
Inverted Dropout和其他正则化
由于Dropout不会阻止参数增长和彼此压制,应用L2正则化可以起到作用。
明确缩放因子后,上述等式变为:
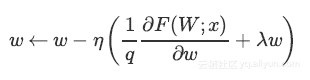
可以看出使用Inverted Dropout,学习率是由因子q进行缩放 。由于q在[0,1]之间,η和q之间的比例变化:
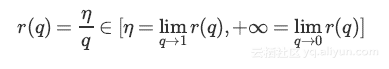
将q称为推动因素,因为其能增强学习速率,将r(q)称为有效的学习速率。
有效学习速率相对于所选的学习速率而言更高:基于此约束参数值的规一化可以帮助简化学习速率选择过程。
总结
1 Dropout存在两个版本:直接(不常用)和反转
2 单个神经元上的dropout可以使用伯努利随机变量建模
3 可以使用二项式随机变量来对一组神经元上的舍弃进行建模
4 即使舍弃神经元恰巧为np的概率是低的,但平均上np个神经元被舍弃。
5 Inverted Dropout提高学习率
6 Inverted Dropout应该与限制参数值的其他归一化技术一起使用,以便简化学习速率选择过程
7 Dropout有助于防止深层神经网络中的过度拟合
作者介绍:Paolo Galeone,计算机工程师以及深度学习研究者,专注于计算机视觉问题的研究

Blog:https://pgaleone.eu/
Linkedin:https://it.linkedin.com/in/paolo-galeone-6782b311b
Twitter:https://twitter.com/paolo_galeone
深入解析Dropout——基本思想:以概率P舍弃部分神经元,其它神经元以概率q=1-p被保留,舍去的神经元的输出都被设置为零的更多相关文章
- 深入解析Dropout
过拟合是深度神经网(DNN)中的一个常见问题:模型只学会在训练集上分类,这些年提出的许多过拟合问题的解决方案:其中dropout具有简单性并取得良好的结果: Dropout 上图为Dropout的可视 ...
- vue组件、数据解析的实现思想猜想与实践
Vue的全局组件,在注册后,可在全局范围内无限次使用,猜想是利用了闭包"可以保持形参"的特性,使初始化时的作用域得意保存,下面用原生js和部分jquery代码模拟了数据解析和组件渲 ...
- SpringBoot源码解析:AOP思想以及相应的应用
spring中拦截器和过滤器都是基于AOP思想实现的,过滤器只作用于servlet,表现在请求的前后过程中:拦截器属于spring的一个组件,由spring管理, 可以作用于spring任何资源,对象 ...
- U3D 飞机大战(MVC模式)解析--面向对象编程思想
在自己研究U3D游戏的时候,看过一些人的简单的游戏开发视频,写的不错,只是个人是java web 开发的人,所以结合着MVC思想,对游戏开发进行了一番考虑. 如果能把游戏更加的思想化,分工化,开发便明 ...
- CASE函数 sql server——分组查询(方法和思想) ref和out 一般处理程序结合反射技术统一执行客户端请求 遍历查询结果集,update数据 HBuilder设置APP状态栏
CASE函数 作用: 可以将查询结果集的某一列的字段值进行替换 它可以生成一个新列 相当于switch...case和 if..else 使用语法: case 表达式/字段 when 值 then ...
- hadoop MapReduce辅助排序解析
1.数据样本,w1.csv到w5.csv,每个文件数据样本2000条,第一列是年份从1990到2000随机,第二列数据从1-100随机,本例辅助排序目标是找出每年最大值,实际上结果每年最大就是100, ...
- [深入理解Android卷一全文-第七章]深入理解Audio系统
由于<深入理解Android 卷一>和<深入理解Android卷二>不再出版,而知识的传播不应该由于纸质媒介的问题而中断,所以我将在CSDN博客中全文转发这两本书的全部内容. ...
- 前向纠错码(FEC)的RTP荷载格式
http://www.rosoo.net/a/201110/15146.html 本文档规定了一般性的前向纠错的媒体数据流的RTP打包格式.这种格式针对基于异或操作的FEC算法进行了特殊设计,它允许终 ...
- 【转载】为什么我的网站加www是打不开的呢
在访问网站的过程中,我们发现有些网站访问不带www的主域名可以正常访问,反而访问加www的域名打不开,那为什么有的网站加www是打不开的呢?此情况很大可能是因为没有解析带www的域名记录或者主机Web ...
随机推荐
- W3C标准冒泡、捕获机制
(一) 捕获和冒泡如何相互影响 我们来做几个任务吧! 有一个前提,#parent为标签,#child为子标签,他们是嵌套关系支线任务1 //捕获模式 document.getElementById(' ...
- 【Linux】Vi中的各种命令
Ctrl+u:向文件首翻半屏: Ctrl+d:向文件尾翻半屏: Ctrl+f:向文件尾翻一屏: Ctrl+b:向文件首翻一屏: Esc:从编辑模式切换到命令模式: ZZ:命令模式下保存当前文件所做的修 ...
- (转载) ORA-12537:TNS连接已关闭
今天在远程客户端配置EBS数据库连接的时候发生“ORA-12537:TNS连接已关闭”的错误.进入服务器运行如下命令:$tnsping VIS 这里VIS如果定义服务名,可以写成 $ tnsping ...
- jQuery顺序加载图片(初版)
浏览器加载图片区别: IE:同时加载与渲染 其他:加载完之后再渲染 根据这个差异用jQuery做个实例:按顺序加载一组图片,加载完成后提示. <!DOCTYPE html> <htm ...
- semiautomatic annotated tools
在进行实验图像取样时,可能会用到大量的标签样本,拍摄大量图片进行手工标注要消耗大量时间,半自动化的标注工具可以节省一些时间. 原文链接:http://blog.sina.com.cn/s/blog_6 ...
- 【技术累积】【点】【编程】【13】XX式编程
(原)函数式编程 核心概念 函数式一等公民(输入输出啥的都可以是函数): 纯函数,固定输入带来固定输出: 阅读性良好,无并发问题,但效率偏低: 大历史背景 旨在描述问题如何计算: 有两位巨擘对问题的可 ...
- 25-Ubuntu-文件和目录命令-其他命令-重定向
重定向 Linux允许将命令执行结果重定向到一个文件. 将本应显示到终端上的内容输出或追加到指定文件中. 重定向命令 含义 > 表示输出,会覆盖原有文件. >> 表示追加,会将内容追 ...
- SQL第三节课
常用函数 一.数学函数 数学函数主要用于处理数字,包括整型.浮点数等. ABS(x) 返回x的绝对值 SELECT ABS(-1) -- 返回1 CEIL(x),CEILING(x) 返回大于或等于x ...
- nyoj112-指数运算
指数运算时间限制:600 ms | 内存限制:65535 KB难度:2描述写一个程序实现指数运算 X^N.(1<X<10,0<N<20)输入输入包含多行数据 每行数据是两个 ...
- Jquery-自定义表单验证
jQuery自定义表单验证