python获取豆瓣日记
最近迷上了看了四个春天,迷上了饭叔的豆瓣日记,想全部抓取下来,简单了写了下面的脚本
import urllib.request
import os
from bs4 import BeautifulSoup
def get_html(url):
"""通用方法,获取整个链接得html·"""
web = urllib.request.urlopen(url)
soup = BeautifulSoup(web, "html.parser")
# print(soup)
data = soup.find("div", id="content")
return data
def get_diary(data,path):
"""获取日记链接,并且存储起来"""
data = data.find_all("div",class_="note-header-container")
for link in data:
# print(link)
diary_url = link.find('div', class_="rr").find('a').get("href")
with open(path, 'a+', encoding='UTF-8') as f:
f.write(diary_url+'\n')
def get_num(url):
#获取最大页数
html_data = get_html(url)
paginator_data = html_data.find("div",class_="paginator")
page_num =[]
for link in paginator_data.find_all("a"):
page_num.append(link.get_text())
return "".join(page_num[-2:-1])
def get_diary_data(url,path):
"""获取日记内容,保存为txt文件"""
data = get_html(url)
title = data.find("h1").get_text()
file_name = path+"/"+title+".txt"
with open(file_name,'a+',encoding='UTF-8') as f:
f.write(title)
note_data = data.find("div",id="link-report")
for node_line in note_data.stripped_strings:
with open(file_name, 'a+', encoding='UTF-8') as f:
f.write(repr(node_line))
if __name__ == '__main__':
url = 'https://www.douban.com/people/luqy/notes'
path = "d://陆导"
diary_url_path = path + "/"+"diary_url.txt"
page_num = get_num(url)
for i in range(14):
url1 = url + "?start=%d&type=note"%(i*10)
get_diary(get_html(url1),diary_url_path)
f = open(diary_url_path,'r',encoding='utf-8')
for line in f.readlines():
try:
get_diary_data(line,path)
except Exception as e:
print(e)
f.close()
目前存在一个问题
1,抓取次数过多会被分IP地址
爬取结果:
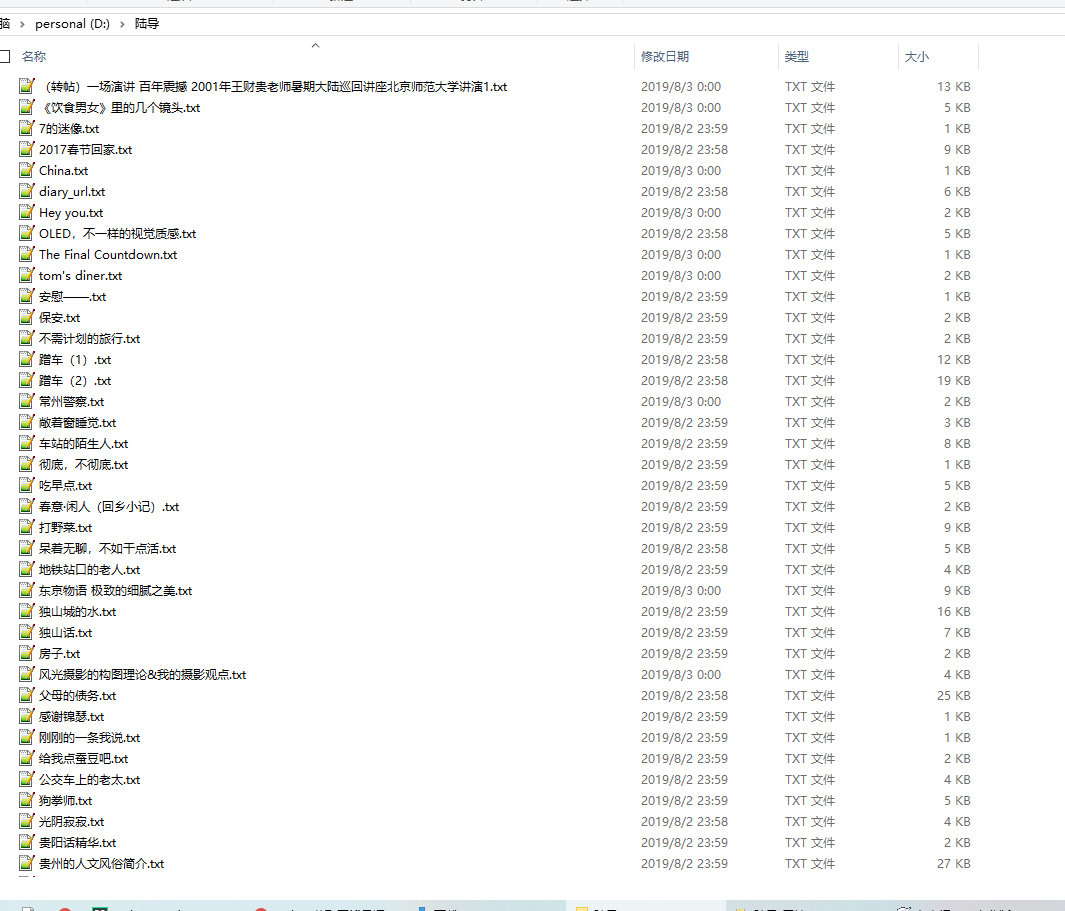
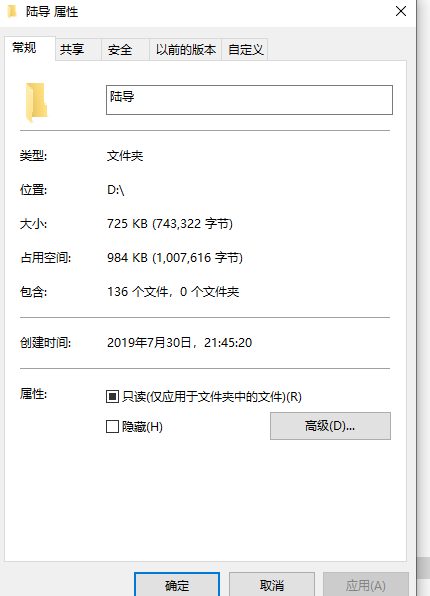
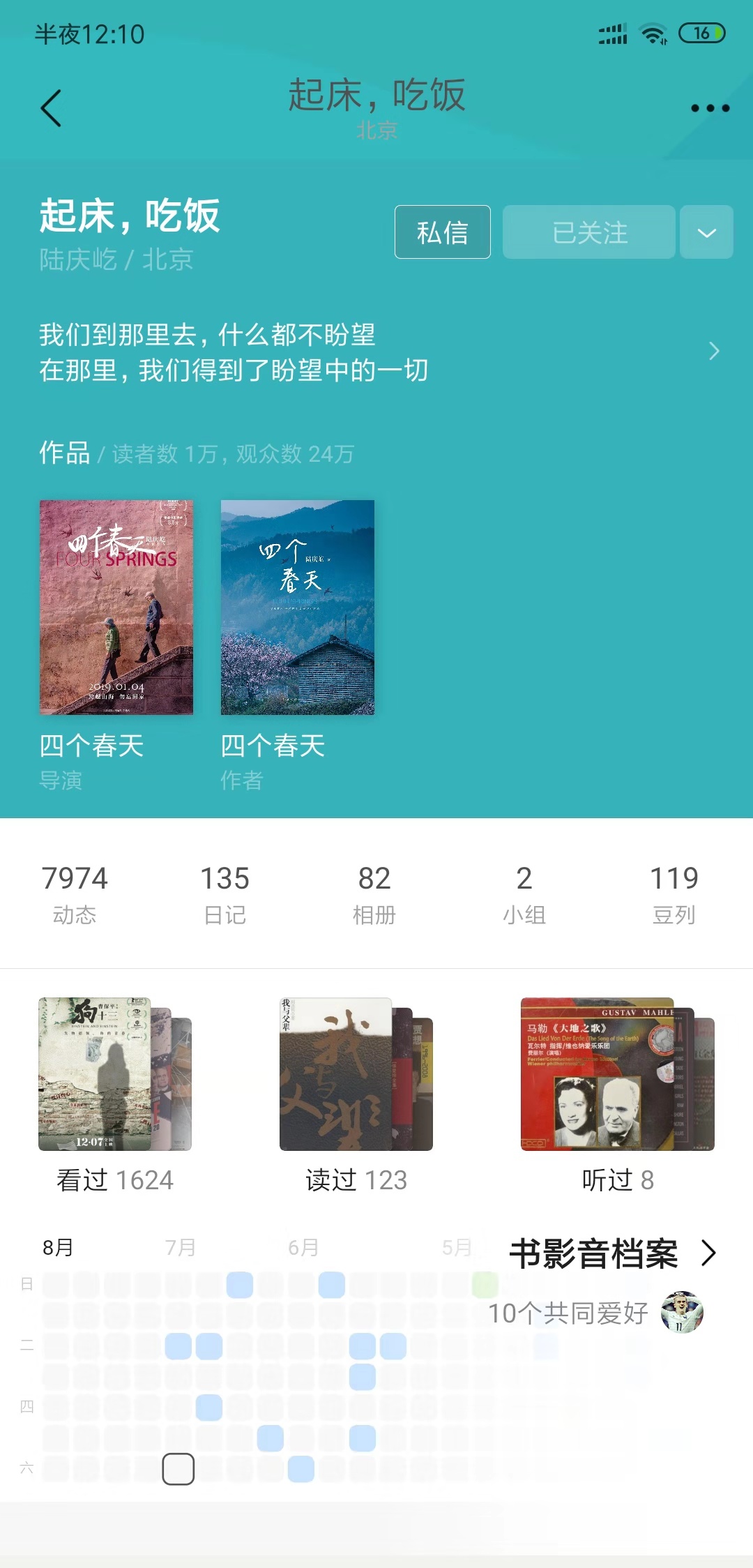
python获取豆瓣日记的更多相关文章
- 爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片. 今天我们在豆瓣上获取一些热门电影的信息. 页面分析 首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影, ...
- Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记
涉及关键词:requests库 requests.post方法 cookies登陆 version 1.5(附录):使用post方法登陆豆瓣,成功! 缺点:无法获得登陆成功后的cookie,要使用js ...
- python爬虫实战 获取豆瓣排名前250的电影信息--基于正则表达式
一.项目目标 爬取豆瓣TOP250电影的评分.评价人数.短评等信息,并在其保存在txt文件中,html解析方式基于正则表达式 二.确定页面内容 爬虫地址:https://movie.douban.co ...
- Python 豆瓣日记爬取
无聊写了个豆瓣日记的小爬虫,requests+bs4. cookies_src可填可不填,主要是为了爬取仅自己可见的日记. url填写的是日记页面,即https://www.douban.com/pe ...
- python监控tomcat日记文件
最近写了一个用python监控tomcat日记文件的功能 实现的功能: 监控日记文件中实时过来的记录,统计每分钟各个接口调用次数,统计结果插入oracle #!/usr/bin/python # -* ...
- HTTP协议与使用Python获取数据并写入MySQL
一.Http协议 二.Https协议 三.使用Python获取数据 (1)urlib (2)GET请求 (3)POST请求 四.爬取豆瓣电影实战 1.思路 (1)在浏览器中输入https://movi ...
- 使用shell/python获取hostname/fqdn释疑
一直以来被Linux的hostname和fqdn(Fully Qualified Domain Name)困惑了好久,今天专门抽时间把它们的使用细节弄清了. 一.设置hostname/fqdn 在Li ...
- python 获取日期
转载 原文:python 获取日期 作者:m4774411wang python 获取日期我们需要用到time模块,比如time.strftime方法 time.strftime('%Y-%m-% ...
- python获取字母在字母表对应位置的几种方法及性能对比较
python获取字母在字母表对应位置的几种方法及性能对比较 某些情况下要求我们查出字母在字母表中的顺序,A = 1,B = 2 , C = 3, 以此类推,比如这道题目 https://project ...
随机推荐
- Django 数据库模块 单独使用
pip install django pip install psycopg2 pip install mysqlclient Entity.py from django.db import mode ...
- nfs服务的配置
nfs服务 nfs简介 Network file system 网络文件系统.NFS server可以看作是一个 file server.它可以让你的pc通过网络将远端的nfs server共享出来的 ...
- parfile解决exp时tables过多问题
parfile 一般用于表数据过大.使用导出.导入命令参数过多等场景: 在对oracle数据库使用exp命令导出数据时,如果tables=后面跟的表比较多,就是导致命令行放不下,从而不能导出.百度一把 ...
- 【未知来源】K-th String
题意 求有多少种 前 \(n\) 个小写字母的排列 \(t\),满足其所有子串按字典序从小到大排列,第 \(k\) 个子串是一个给定字符串 \(s\).答案模 \(10^9+7\). \(1\le n ...
- mysql连接类与ORM的封装
ORM: - ORM什么是? 类名 ---> 数据库表 对象 ---> 记录 对象.属性 ---> 字段 - ORM的优缺点: 优点: 可跨平台,可以通过对象.属性取值,对象.方法, ...
- HihoCoder1052基因工程(简单模拟题)
描述 小Hi和小Ho正在进行一项基因工程实验.他们要修改一段长度为N的DNA序列,使得这段DNA上最前面的K个碱基组成的序列与最后面的K个碱基组成的序列完全一致. 例如对于序列"ATCGAT ...
- fedora29 安装mongodb 4.0,6问题记录
如果运行mongod命令时提示 无加载共享库libcrypto.so.10,那就到页面下载http://www.rpmfind.net/linux/rpm2html/search.php?query= ...
- 【leetcode】1234. Replace the Substring for Balanced String
题目如下: You are given a string containing only 4 kinds of characters 'Q', 'W', 'E' and 'R'. A string i ...
- Python 文件I/OⅢ
read()方法 read()方法从一个打开的文件中读取一个字符串.需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字. 语法: 在这里,被传递的参数是要从已打开文件中读取的字节计 ...
- C# DataGridView 更改类型 重绘
DataGridView 更改类型 需要用到重绘 DataGridViewTextBoxColumn aa01 = new DataGridViewTextBoxColumn(); aa00.Da ...