HDFS-Suffle
一、Shuffle机制
1、官网图
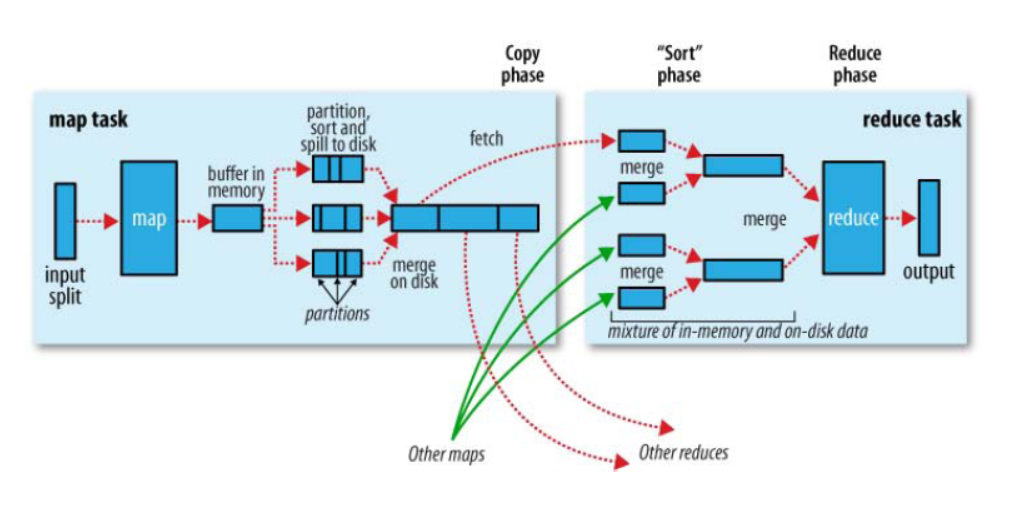
2、MR确保每个Reducer的输入都是按照key排序的。系统执行排序的过程(即将Mapper输出作为输入传给Reducer)成为Shuffle
二、Partition分区
1、默认分区HashPartitioner
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默认分区是根据key的hashcode对ReduceTeasks个数取模得到的。用户不能控制key存储的分区
2、自定义分区
(1)自定义类继承Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
//TODO
return 分区;
}
}
job.setPartitionerClass(CustomPartitioner.class)
(3)自定义partition后,要根据自定义partitioner的逻辑设置相应数量的reduceTask
job.setNumReduceTasks(5)
3、分区总结
(1)如果reduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
4、分区案例
假设自定义分区数为5
job.setNumReduceTasks(1) #正常运行,产生一个输出文件
job.setNumReduceTasks(2) #报错
job.setNumReduceTasks(6) #大于5,正常运行,会产生一个空文件
三、排序
1、概述
(1)排序是MapReduce框架中最重要的操作之一
(2)Map Task和Reduce Task均会对数据(按照key)进行排序。
(3)该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
(4)默认排序时按照字典顺序排序,且实现该排序的方法是快速排序
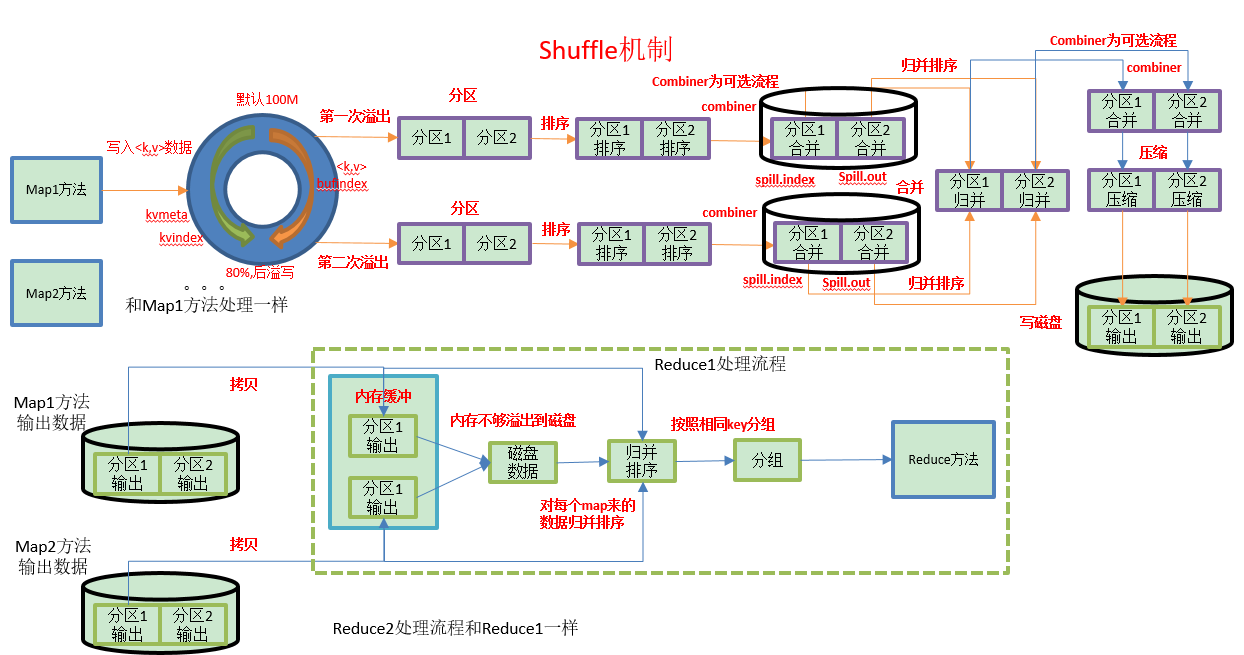
(5)对于Map Task,它会将处理的结果暂时放到一个缓冲区中,当缓冲区使用率达到一定阈值(默认100M)后,再对缓冲区中的数据进行一次局部(区内)排序,排序完成后,并将这些有序数据写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行一次合并(Combiner如果有),以将这些文件合并成一个大的有序文件。
(6)对于Reduce Task,它从每个Map Task上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则放到磁盘上,否则放到内存中。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完毕后,Reduce Task统一对内存和磁盘上的所有数据进行一次合并。
2、排序分类
(1)部分排序:MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部排序。
(2)全排序:
最终输出结果只有一个文件,且文件内部有序。
但该方法在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了MapReduce所提供的并行架构。
解决:首先创建一系列排好序的文件;其次,串联这些文件;最后,生成一个全局排序的文件。主要思路是使用一个分区来描述输出的全局排序。例如:可以为上述文件创建3个分区,在第一分区中,记录的单词首字母a-g,第二分区记录单词首字母h-n, 第三分区记录单词首字母o-z。
(3)辅助排序:(GroupingComparator分组):
Mapreduce框架在记录到达reducer之前按键对记录排序,但键所对应的值并没有被排序。甚至在不同的执行轮次中,这些值的排序也不固定,因为它们来自不同的map任务且这些map任务在不同轮次中完成时间各不相同。一般来说,大多数MapReduce程序会避免让reduce函数依赖于值的排序。但是,有时也需要通过特定的方法对键进行排序和分组等以实现对值的排序。
(4)二次排序:在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
3、排序实现
(1)bean对象实现WritableComparable接口重写compareTo方法,就可以实现排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
(2)自定义排序器,实现WritableComparable接口重写compare方法
public class MyRawComparator extends WritableComparator{
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
return (thisValue<thatValue ? 1 : (thisValue==thatValue ? 0 : -1));
}
}
在Driver里面设置自定义排序器
conf.set("mapreduce.job.output.key.comparator.class", "com.mr.sort.MyRawComparator");
(3)自定义排序器,实现RawComparator接口重写compare方法
private final DataInputBuffer buffer;
private final F key1;
private final Fkey2; public FCompartor() { buffer=new DataInputBuffer();
key1=new F();
key2=new F(); }
public int compare(F o1, F o2) {
return -o1.getXXX().compareTo(o2.getSumXXX());
} @Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer); buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer); buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
} return compare(key1, key2);
}
在Driver里面设置自定义排序器
conf.set("mapreduce.job.output.key.comparator.class", "com.mr.sort.FCompartor");
四、Combiner合并
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果
(4)combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
(5)combiner能够应用的前提是不能影响最终的业务逻辑
(6)combiner的输出kv应该跟reducer的输入kv类型要对应起来
(7)使用场景:加减计算适用,乘除不适用
(8)运行时机:
①在溢写之前运行(如果设置了Combinner,MapTask的shuffle中,一定会运行)
在溢写前,对需要溢写的KV进行合并,合并后可以将相同Key的KV合并为1个KV
例如: (hadoop,1),(hive,1),(spark,1),(hadoop,1),(hive,1),(spark,1),(hadoop,1),(hive,1),(spark,1)
启动: (hadoop,3),(hive,3),(spark,3)
②在最终的merge阶段,当溢写的片段 >= 3时,才会再次运行Combiner
split0: (hadoop,3),(hive,3),(spark,3)
split1: (hadoop,3),(hive,3)
。。。N
split.final :(hadoop,3),(hive,3),(spark,3),(hadoop,3),(hive,3)
2、自定义Combiner
(1)自定义一个combiner继承Reducer,重写reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable v :values){
count = v.get();
}
context.write(key, new IntWritable(count));
}
}
(2)在job驱动类中设置
job.setCombinerClass(WordcountCombiner.class);
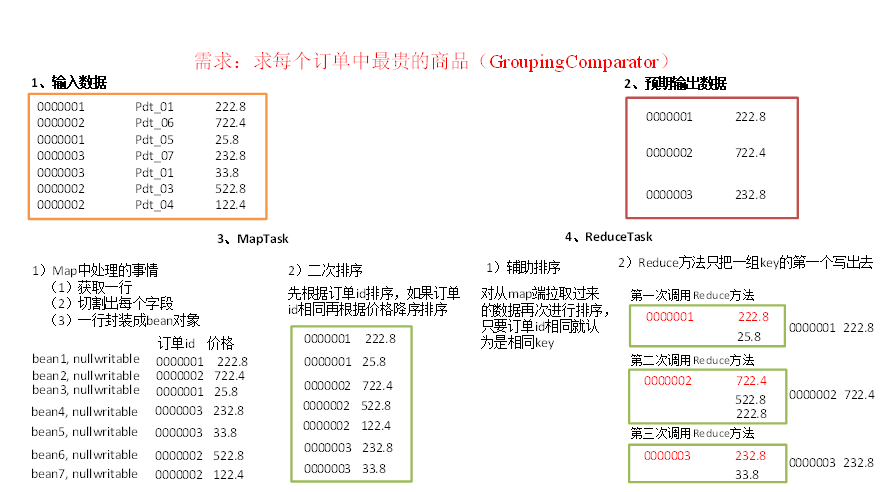
五、GroupingComparator分组(辅助排序)
对reduce阶段的数据根据某一个或几个字段进行分组。
使用案例:
如求每个订单中最贵的商品
HDFS-Suffle的更多相关文章
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- python基础操作以及hdfs操作
目录 前言 基础操作 hdfs操作 总结 一.前言 作为一个全栈工程师,必须要熟练掌握各种语言...HelloWorld.最近就被"逼着"走向了python开发之路, ...
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。
一.Hadoop环境配置概述 三台虚拟机,操作系统为:Ubuntu 16.04. Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72. ...
- HDFS的架构
主从结构 主节点,只有一个: namenode 从节点,有很多个: datanodes 在版本1中,主节点只有一个,在 版本2中主节点有两个. namenode 负责(管理): 接收用户操作请求 维护 ...
- hdfs以及hbase动态增加和删除节点
一个知乎上的问题:Hbase的Region server和hadoop的datanode是否可以部署在一台服务器上?如果是的话,二者是否是一对一的关系?部署在同一台服务器上,可以减少数据跨网络传输的流 ...
- hadoop程序问题:java.lang.IllegalArgumentException: Wrong FS: hdfs:/ expected file:///
Java代码如下: FileSystem fs = FileSystem.get(conf); in = fs.open(new Path("hdfs://192.168.130.54:19 ...
- 01 HDFS 简介
01.HDFS简介 大纲: hadoop2 介绍 HDFS概述 HDFS读写流程 hadoop2介绍 框架的核心设计是HDFS(存储),mapReduce(分布式计算),YARN(资源管理),为海量的 ...
- 何为HDFS?
该文来自百度百科,自我收藏. Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
随机推荐
- 前端校招知识体系之css
本文将从以下四个方面展开介绍: 选择器 样式表继承 css3部分特性 BFC css选择器优先级策略 先附上个链接:css选择器参考手册 内联>id>class=属性选择器=伪类选择器&g ...
- Conference - open source drives IOT from device to edge
Open source drives IOT from device to edge 以下都是针对IOT领域的项目: ACRN A Big Little Hypervisor for IoT Deve ...
- tpcc-mysql测试mysql5.6 (xfs文件系统)
操作系统版本:CentOS release 6.5 (Final) 2.6.32-431.el6.x86_64 #1 内存:32G CPU:Intel(R) Xeon(R) CPU E5-2450 ...
- html5 新增和改良的input 类型实例
url test1.html <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- pycharm中能运行,但是往往py都要放到服务器上去跑,问题来了
py文件在linux上运行,导包错误: 在py文件中添加项目的根目录: import sys sys.path.append('项目路径') sys.path.append(os.path.dirna ...
- LOJ 2840「JOISC 2018 Day 4」糖
有趣的脑子题(可惜我没有脑子 好像也可以称为模拟费用流(? 我们考虑用链表维护这个东西 再把贡献扔到堆里贪心就好了 大概就是类似于有反悔机制的贪心?我们相当于把选中的一个打上一个-v的tag然后如果选 ...
- 企业级监控软件Zabbix搭建部署之zabbix在WEB页面中的配置
企业级监控软件zabbix搭建部署之zabbix在WEB页面中的配置 企业级监控软件zabbix搭建部署之zabbix在WEB页面中的配置 关于安装请看 http://www.linuxidc.com ...
- 【leetcode】861. Score After Flipping Matrix
题目如下: 解题思路:本题需要知道一个数字规律,即pow(2,n) > sum(pow(2,0)+pow(2,1)+...+pow(2,n-1)).所以,为了获得最大值,要保证所有行的最高位是1 ...
- 对webpack的初步研究8
模块 编辑文档 在模块化编程中,开发人员将程序分解为称为模块的离散功能块. 每个模块的表面积小于完整程序,使验证,调试和测试变得微不足道.编写良好的模块提供了可靠的抽象和封装边界,因此每个模块在整个应 ...
- maven-enforcer-plugin查看冲突
我们会经常碰到这样的问题,在pom中引入了一个jar,里面默认依赖了其他的jar包.jar包一多的时候,我们很难确认哪些jar是我们需要的,哪些jar是冲突的.此时会出现很多莫名其妙的问题,什么类找不 ...