Cross-entropy Cost Function for Classification Problem
在Machine Learning的Regression Problem中,常用Quadratic Function来做Cost Function,用以表征Hypothesis与Y之间的差距。而通过Gradient Descent来不断调整参数,从而缩小这个Gap从而训练我们的算法。
而在Neural Network的Classification Problem中,如果依然使用Quadratic Function,则会出现学习速率过慢的问题,这时我们就需要选用Cross-entropy来做Cost Function。首先,在NN的Backpropagation过程中,我们可以知道Cost对于最后一层的weight矩阵的梯度为:
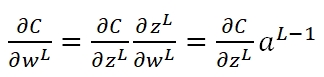
其中C对激励输入zL的梯度记为:
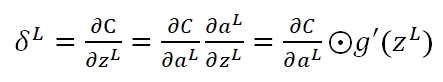
而在使用Quadratic作为Cost的情况下:
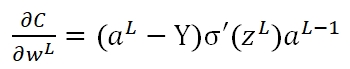
可以看出,该梯度是由Hypothesis与Y的差值以及σ'(z)决定。此时存在一个问题:在训练的最初阶段,我们的参数的随机的,这意味着初期Z值有可能很大,也有可能很小,假如y=0,但由于z值很大导致最终的输出aL=1,此时预测结果与期望值正好相反,但此时σ的梯度却近似于0,导致学习速率很慢。我们对照下面的两张图即可有所体会:
如果初始值选择的不好,就会是这个情况。在最初训练时,cost下降很慢,当过了某个临界点,学习加快:
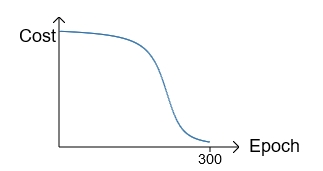
然而,我们的期望是,结果差的越多,理应学习速率越快。就像开车出门,如果走了目的地相反的方向,那就要调头呀!而σ'(z)作为斜率,在z很大或很小的地方斜率几乎为零,导致学习速率很慢。所以我们引入一个新的Cost Function:Cross-entropy,其形式如下:
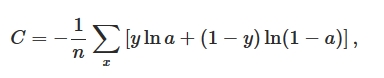
首先,如果我们计算输出cost对第L层第j结点权重ω的偏导(梯度):
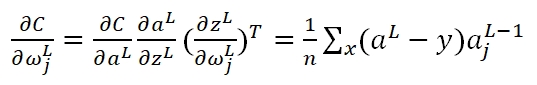
在运算过程中g'(z)被消掉了,也就是说,无论g'(z)是什么情况,不影响我们的梯度,而决定性因素,仅仅是真实输出值与期望值的差。此外,Cost Function变更了,那么在最后一层的δ变更为:
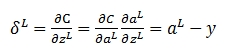
但在Deep Learning中,其实仅仅一个Cross-entropy是无法解决全部的梯度问题的,在另一篇文章中,我也介绍到了Gradient Vanishing的问题。
Cross-entropy Cost Function for Classification Problem的更多相关文章
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- 一篇博客:分类模型的 Loss 为什么使用 cross entropy 而不是 classification error 或 squared error
https://zhuanlan.zhihu.com/p/26268559 分类问题的目标变量是离散的,而回归是连续的数值. 分类问题,都用 onehot + cross entropy traini ...
- machine learning(11) -- classification: advanced optimization 去求cost function最小值的方法
其它的比gradient descent快, 在某些场合得到广泛应用的求cost function的最小值的方法 when have a large machine learning problem, ...
- machine learning(10) -- classification:logistic regression cost function 和 使用 gradient descent to minimize cost function
logistic regression cost function(single example) 图像分布 logistic regression cost function(m examples) ...
- 【机器学习】代价函数(cost function)
注:代价函数(有的地方也叫损失函数,Loss Function)在机器学习中的每一种算法中都很重要,因为训练模型的过程就是优化代价函数的过程,代价函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过 ...
- Model Representation and Cost Function
Model Representation To establish notation for future use, we’ll use x(i) to denote the “input” vari ...
- 【机器学习基础】交叉熵(cross entropy)损失函数是凸函数吗?
之所以会有这个问题,是因为在学习 logistic regression 时,<统计机器学习>一书说它的负对数似然函数是凸函数,而 logistic regression 的负对数似然函数 ...
- [Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢? 我个人理解 ...
- logistic回归具体解释(二):损失函数(cost function)具体解释
有监督学习 机器学习分为有监督学习,无监督学习,半监督学习.强化学习.对于逻辑回归来说,就是一种典型的有监督学习. 既然是有监督学习,训练集自然能够用例如以下方式表述: {(x1,y1),(x2,y2 ...
随机推荐
- 动画可以暂停animation-play-state
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- React项目 - 几种CSS实践
前言团队在使用react时,不断探索,使用了很多不同的css实现方式,此篇blog总结了,react项目中常见的几种css解决方案:inline-style/radium/style-componen ...
- Codeforces Round #545 (Div. 2) C. Skyscrapers (离散化)
题目传送门 题意: 给你n*m个点,每个点有高度h [ i ][ j ] ,用[1,x][1,x]的数对该元素所处十字上的所有元素重新标号, 并保持它们的相对大小不变.n,m≤1000n,m≤1000 ...
- C#设计模式:命令模式(Command Pattern)
一,什么是命令模式(Command Pattern)? 命令模式:将请求封装成命令对象,请求的具体执行由命令接收者执行: 二,如下代码 using System; using System.Colle ...
- Github之利用SSH完成Git与GitHu 的绑定
第 1 步:生成 SSH key 在 Git Bash 中输入ssh命令,查看本机是否安装 SSH: 输入ssh-keygen -t rsa命令,表示我们指定 RSA 算法生成密钥,然后敲三次回车键, ...
- TP中如何去掉index.php
使用过TP的同学都知道,在URL始终会有index .php 我们如何才能够去掉呢? 1. 确认httpd.conf配置文件中加载了mod_rewrite.so模块 2. AllowOverride ...
- installsheild2011打包程序internal build error 6213
今天打包一个安装程序,总是出现报错,internal build error -6213,然后搜遍都没有找到什么解决方案.看到一个帖子,说是因为installsheild里面的build的时候自动扫描 ...
- JavaScript基础1——在末尾添加节点
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- ASE Beta Sprint - backend scrum 4
本次scrum于2019.12.10在sky garden进行,持续10分钟. 参与人: Xin Kang, Zhikai Chen, Lihao Ran, Hao Wang 请假: Ning Jia ...
- Altium Designer设计PCB中如何开槽
在不同层画槽孔形状实际得到的PCB效果(注意槽孔边缘) 在不同层画槽孔形状进行(注意槽孔边缘) 很多坛友问在使用Altium Designer设计PCB时,想在板子上开一个槽或者挖一个孔该如何操作,是 ...