logstash之OutPut插件
output插件是经过了input,然后过滤结构化数据之后,接下来我们需要借助output传到我们想传到的地方.output相当于一个输出管道。
2.3.1: 将采集数据标准输出到控制台
配置示例:
output {
stdout {
codec => rubydebug
}
}
Codec 来自 Coder/decoder
两个单词的首字母缩写,Logstash 不只是一个input | filter | output 的数据流,
而是一个input | decode | filter | encode | output 的数据流,codec 就是用来decode、encode 事件的。
简单说,就是在logstash读入的时候,通过codec编码解析日志为相应格式,从logstash输出的时候,通过codec解码成相应格式。
演示:
input {stdin{}}
output {
stdout {
codec => rubydebug
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout.conf
展示:

2.3.2:将采集数据保存到file文件中
通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求;
需求:将数据采集到logstash的日志文件中,区分业务和采集日期(哪天采集的)
input {stdin{}}
output {
file {
path => "/home/angel/logstash-5.5.2/logs/stdout/mobile-collection/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
gzip => true
}
}
启动:
bin/logstash -f /home/angel/servers/logstash-5.5.2/logstash_conf/stdout_file.conf
2.3.3:将采集数据保存到elasticsearch
Logstash可以直接将采集到的信息下沉到elasticsearch中
input {stdin{}}
output {
elasticsearch {
hosts => ["hadoop01:9200"]
index => "logstash-%{+YYYY.MM.dd}" #这个index是保存到elasticsearch上的索引名称,如何命名特别重要,因为我们很可能后续根据某些需求做查询,所以最好带时间,因为我们在中间加上type,就代表不同的业务,这样我们在查询当天数据的时候,就可以根据类型+时间做范围查询
flush_size => 20000 #表示logstash的包数量达到20000个才批量提交到es.默认是500
idle_flush_time => 10 #多长时间发送一次数据,flush_size和idle_flush_time以定时定量的方式发送,按照批次发送,可以减少logstash的网络IO请求
user => elastic
password => changeme
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout_es.conf
向控制台中输入6条数据:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
2.3.4:将采集的数据保存到redis
配置:
input { stdin {} }
output {
redis {
host => "hadoop01"
data_type => "list"
db => 2
port => "6379"
key => "logstash-chan-%{+yyyy.MM.dd}"
}
}
数据落地到redis的优化:
• 批处理类(仅用于data_type为list)
o batch:设为true,通过发送一条rpush命令,存储一批的数据
o 默认为false:1条rpush命令,存储1条数据
o 设为true之后,1条rpush会发送batch_events条数据
o batch_events:一次rpush多少条
o 默认50条
o batch_timeout:一次rpush最多消耗多少s
o 默认5s
• 拥塞保护(仅用于data_type为list)
o congestion_interval:每隔多长时间进行一次拥塞检查
o 默认1s
o 设为0,表示对每rpush一个,都进行检测
o congestion_threshold:list中最多可以存在多少个item数据
o 默认是0:表示禁用拥塞检测
o 当list中的数据量达到congestion_threshold,会阻塞直到有其他消费者消费list中的数据
o 作用:防止OOM
启动redis 将数据打入logstash控制台:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
去redis上做认证,查看是否已经存储redis中:
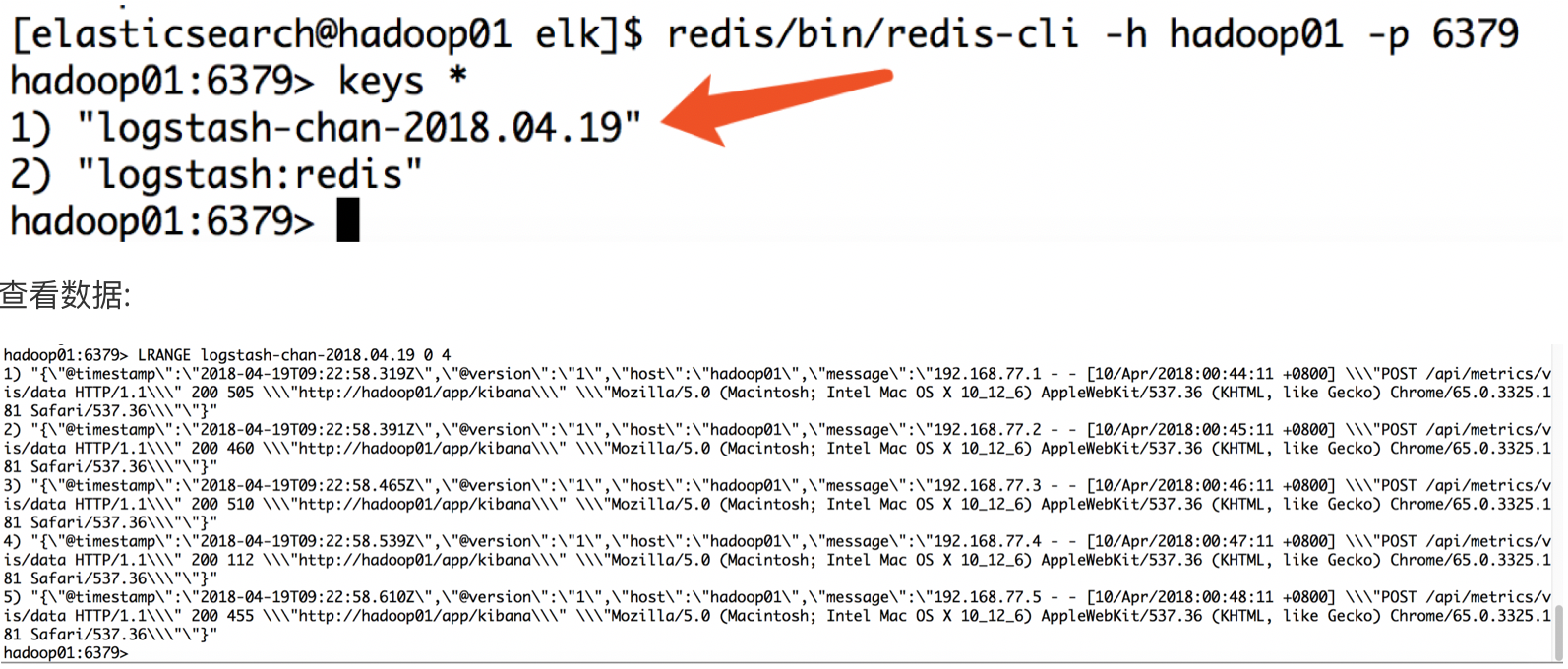
logstash之OutPut插件的更多相关文章
- logstash的output插件
logstash 的output插件 nginx,logstash和redis在同一台机子上 yum -y install redis,vim /etc/redis.conf 设置bind 0.0.0 ...
- 五十八.Kibana使用 、 Logstash配置扩展插件
1.导入数据 批量导入数据并查看 1.1 导入数据 1) 使用POST方式批量导入数据,数据格式为json,url 编码使用data-binary导入含有index配置的json文件 ]# ...
- 使用logstash的grok插件解析springboot日志
使用logstash的grok插件解析springboot日志 一.背景 二.解决思路 三.前置知识 四.实现步骤 1.准备测试数据 2.编写`grok`表达式 3.编写 logstash pipel ...
- logstash的output配置中指定elasticsearch的template
转自:https://blog.csdn.net/felix_yujing/article/details/78930389 之前采用的是通过filebeat收集nginx的日志,直接到elastic ...
- ELK 学习笔记之 Logstash之output配置
Logstash之output配置: 输出到file 配置conf: input{ file{ path => "/usr/local/logstash-5.6.1/bin/spark ...
- logstash之multiline插件,匹配多行日志
在外理日志时,除了访问日志外,还要处理运行时日志,该日志大都用程序写的,比如log4j.运行时日志跟访问日志最大的不同是,运行时日志是多行,也就是说,连续的多行才能表达一个意思. 在filter中,加 ...
- logstash 安装zabbix插件
<pre name="code" class="html">[root@xxyy yum.repos.d]# yum install ruby Lo ...
- Logstash使用grok插件解析Nginx日志
grok表达式的打印复制格式的完整语法是下面这样的: %{PATTERN_NAME:capture_name:data_type}data_type 目前只支持两个值:int 和 float. 在线g ...
- logstash实战filter插件之grok(收集apache日志)
有些日志(比如apache)不像nginx那样支持json可以使用grok插件 grok利用正则表达式就行匹配拆分 预定义的位置在 /opt/logstash/vendor/bundle/jruby/ ...
随机推荐
- Codeforces 1140F Extending Set of Points (线段树分治+并查集)
这题有以下几个步骤 1.离线处理出每个点的作用范围 2.根据线段树得出作用范围 3.根据分治把每个范围内的点记录和处理 #include<bits/stdc++.h> using name ...
- kafka工作原理
https://blog.csdn.net/qq_29186199/article/details/80827085 https://www.jianshu.com/p/4bf007885116 ht ...
- redis 模拟redis server接收信息
一.实现说明 客户端使用jedis正常set值到redis服务器 2. 模拟服务器接收jedis发送的信息 二.jedis客户端代码 package com.ahd.redis; import r ...
- Django设置 DEBUG=False后静态文件无法加载
修改setting.py STATIC_URL = '/static/' STATIC_ROOT = 'static' ## 新增行 STATICFILES_DIRS = [ os.path.join ...
- SIP协议 会话发起协议(二)
SIP - 响应码 SIP响应是由用户代理服务器(UAS)或SIP服务器生成的用于回复客户端生成的请求的消息.这可能是一个正式的确认,以防止UAC转发请求. 响应可能包含UAC所需的一些额外的信息头字 ...
- PAT Advanced 1033 To Fill or Not to Fill (25 分)
With highways available, driving a car from Hangzhou to any other city is easy. But since the tank c ...
- Jam's balance HDU - 5616 (01背包基础题)
Jim has a balance and N weights. (1≤N≤20) The balance can only tell whether things on different side ...
- 单调队列优化DP || [NOI2005]瑰丽华尔兹 || BZOJ 1499 || Luogu P2254
题外话:题目极好,做题体验极差 题面:[NOI2005]瑰丽华尔兹 题解: F[t][i][j]表示第t时刻钢琴位于(i,j)时的最大路程F[t][i][j]=max(F[t-1][i][j],F[t ...
- 如何在通过脚手架create-react-app 创建的react项目中配置 less
首先感慨下 自己竟然有半年没登账户 ,干嘛去啦? 从刚接触vue 接手做两次版本之后 又让我这个小菜鸡 开始开发react项目,连react生命周期还没搞明白的时候 就开始进行第一版本的开发了,第一个 ...
- Java并发编程实战 第10章 避免活跃性危险
死锁 经典的死锁:哲学家进餐问题.5个哲学家 5个筷子 如果没有哲学家都占了一个筷子 互相等待筷子 陷入死锁 数据库设计系统中一般有死锁检测,通过在表示等待关系的有向图中搜索循环来实现. JVM没有死 ...