Wasserstein Generative Adversarial Nets (WGAN ) and CGAN
GAN目前是机器学习中非常受欢迎的研究方向。主要包括有两种类型的研究,一种是将GAN用于有趣的问题,另一种是试图增加GAN的模型稳定性。
事实上,稳定性在GAN训练中是非常重要的。起初的GAN模型在训练中存在一些问题,e.g., 模式塌陷(生成器演化成非常窄的分布,只覆盖数据分布中的单一模式)。模式塌陷的含义是发生器只能产生非常相似的样本(例如MNIST中的单个数字),即所产生的样本不是多样的。这当然违反了GAN的初衷。
GAN中的另一个问题是没有指很好的指标或度量说明模型的收敛性。生成器和鉴别器的损失并没有告诉我们关于这方面的任何信息。当然,我们可以通过查看生成器产生的数据来监控训练过程。但是,这是一个愚蠢的手动过程。所以,我们需要一个可解释的指标告诉我们训练过程的好坏。
Wasserstein GAN
Wasserstein GAN(WGAN)是一种新提出的GAN算法,可以在一定程度解决上述两个问题。对于WGAN背后的直觉和理论背景,可以查看相关资料。
整个算法的伪代码如下:

- 损失函数中没有log。判别器D(X)的输出不再是一个概率(标量),同时也就意味着没有sigmoid激活函数
- 对于判别器D(X)的权重W进行裁剪
- 训练判别器的次数多于生成器
- 采用RMSProp优化器,代替原先的ADAM优化器
- 非常低的learning rate, α=0.00005
WGAN TensorFlow implementation
GAN的基本实现可以在上一篇文章中介绍过。 我们只需要稍微修改下传统的GAN。 首先,让我们更新我们的判别器D(X)
""" Vanilla GAN """
def discriminator(x):
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1)
out = tf.matmul(D_h1, D_W2) + D_b2
return tf.nn.sigmoid(out) """ WGAN """
def discriminator(x):
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1)
out = tf.matmul(D_h1, D_W2) + D_b2
return out
接下来,修改loss函数,去掉log:
""" Vanilla GAN """
D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake))
G_loss = -tf.reduce_mean(tf.log(D_fake)) """ WGAN """
D_loss = tf.reduce_mean(D_real) - tf.reduce_mean(D_fake)
G_loss = -tf.reduce_mean(D_fake)
在每次梯度下降更新后,裁剪判别器D(X)的权重:
# theta_D is list of D's params
clip_D = [p.assign(tf.clip_by_value(p, -0.01, 0.01)) for p in theta_D]
然后,只需要训练更多次的判别器D(X)就行了
D_solver = (tf.train.RMSPropOptimizer(learning_rate=5e-5)
.minimize(-D_loss, var_list=theta_D))
G_solver = (tf.train.RMSPropOptimizer(learning_rate=5e-5)
.minimize(G_loss, var_list=theta_G)) for it in range(1000000):
for _ in range(5):
X_mb, _ = mnist.train.next_batch(mb_size) _, D_loss_curr, _ = sess.run([D_solver, D_loss, clip_D], feed_dict={X: X_mb, z: sample_z(mb_size, z_dim)}) _, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={z: sample_z(mb_size, z_dim)})
Conditional GAN
这里顺便简短的介绍下CGAN。
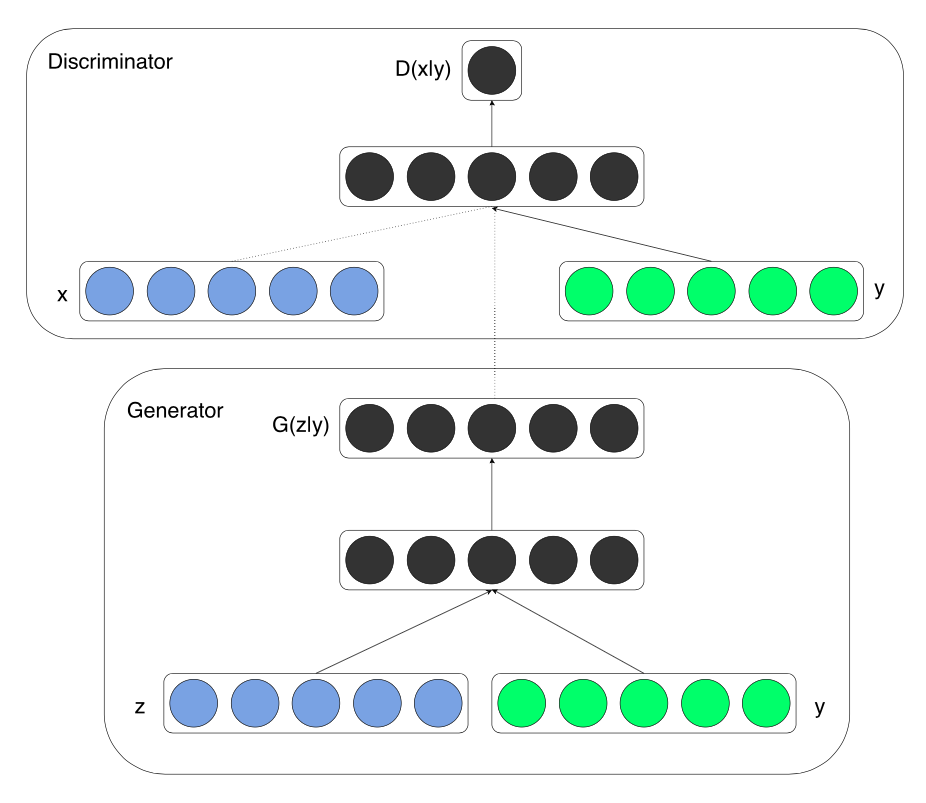
只需要在判别器D(X)和生成器G(Z)中的输入层额外拼接上向量y就可以了
额外的输入y:
y = tf.placeholder(tf.float32, shape=[None, y_dim])
再将它加入到判别器D(X)和生成器G(Z)中:
def generator(z, y):
# Concatenate z and y
inputs = tf.concat(concat_dim=1, values=[z, y]) G_h1 = tf.nn.relu(tf.matmul(inputs, G_W1) + G_b1)
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2
G_prob = tf.nn.sigmoid(G_log_prob) return G_prob def discriminator(x, y):
# Concatenate x and y
inputs = tf.concat(concat_dim=1, values=[x, y]) D_h1 = tf.nn.relu(tf.matmul(inputs, D_W1) + D_b1)
D_logit = tf.matmul(D_h1, D_W2) + D_b2
D_prob = tf.nn.sigmoid(D_logit) return D_prob, D_logit
改变权重的维数:
# Modify input to hidden weights for discriminator
D_W1 = tf.Variable(shape=[X_dim + y_dim, h_dim])) # Modify input to hidden weights for generator
G_W1 = tf.Variable(shape=[Z_dim + y_dim, h_dim]))
构建新的网络:
# Add additional parameter y into all networks
G_sample = generator(Z, y)
D_real, D_logit_real = discriminator(X, y)
D_fake, D_logit_fake = discriminator(G_sample, y)
训练时,额外加入y即可:
X_mb, y_mb = mnist.train.next_batch(mb_size) Z_sample = sample_Z(mb_size, Z_dim)
_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: Z_sample, y:y_mb})
_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: Z_sample, y:y_mb})
接下来进行生成器验证的时候,可以固定y的值:
n_sample = 16
Z_sample = sample_Z(n_sample, Z_dim) # Create conditional one-hot vector, with index 5 = 1
y_sample = np.zeros(shape=[n_sample, y_dim])
y_sample[:, 7] = 1 samples = sess.run(G_sample, feed_dict={Z: Z_sample, y:y_sample})






PS:用下面的loss函数,收敛特别快,效果会更加好。
D_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real,labels=tf.ones_like(D_real)))
D_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake,labels=tf.zeros_like(D_fake)))
D_loss=D_loss_real+D_loss_fake
G_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake,labels=tf.ones_like(D_fake)))
Wasserstein Generative Adversarial Nets (WGAN ) and CGAN的更多相关文章
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
- Generative Adversarial Nets[Pre-WGAN]
本文来自<towards principled methods for training generative adversarial networks>,时间线为2017年1月,第一作者 ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- Generative Adversarial Nets[pix2pix]
本文来自<Image-to-Image Translation with Conditional Adversarial Networks>,是Phillip Isola与朱俊彦等人的作品 ...
- Generative Adversarial Nets(原生GAN学习)
学习总结于国立台湾大学 :李宏毅老师 Author: Ian Goodfellow • Paper: https://arxiv.org/abs/1701.00160 • Video: https:/ ...
- GAN(Generative Adversarial Nets)的发展
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度慢 3.resolution太小,大了无语义信息 4.无reference ...
- 论文笔记之:Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets arXiv 2014 本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加"激烈 ...
随机推荐
- PLSQL导出表的数据insert语句
“Where clause”可以设置查询条件.设置好文件导出的路径(“Output file”),点击[Export]按钮,就可以导出INSERT语句了. 导出之后使用nodepad打开: 但是如果我 ...
- 使用ViewPager实现广告自动轮播的效果
package com.loaderman.viewpgerlunbodemo; import android.os.Bundle; import android.os.Handler; import ...
- 【flask】处理表单数据
表单数据的处理涉及很多内容,除去表单提交不说,从获取数据到保存数据大致会经历以下步骤: 解析请求,获取表单数据. 对数据进行必要的转换,比如将勾选框的植转换为Python的布尔值. 验证数据是否符合 ...
- 通过JavaScript让页面只刷新一次
1.充分利用地址栏可带参数的选项,用脚本来取得页面间的传递参数,并不需要后台程序的支持. 2.函数名 function reurl(){ url = location.href; //把当前页面的地址 ...
- SAS数据挖掘实战篇【六】
SAS数据挖掘实战篇[六] 6.3 决策树 决策树主要用来描述将数据划分为不同组的规则.第一条规则首先将整个数据集划分为不同大小的 子集,然后将另外的规则应用在子数据集中,数据集不同相应的规则也不同 ...
- Kafka集群搭建和配置
Kafka配置优化 https://www.jianshu.com/p/f62099d174d9 1.安装&配置 下载tar包 解压后即可使用 修改配置文件 将server.propertie ...
- Pytorch调整学习率
每隔一定的epoch调整学习率 def adjust_learning_rate(optimizer, epoch): """Sets the learning rate ...
- Spring数据库主从分离
1.spring+spring mvc +mybatis+druid 实现数据库主从分离 2.Spring+MyBatis主从读写分离 3.MyCat痛点 4.Spring+MyBatis实现数据库读 ...
- 服务器被植入木马,CPU飙升200%
线上服务器用的是某云的,欢快的完美运行着Tomcat,MySQL,MongoDB,ActiveMQ等程序.突然一则噩耗从前线传来:网站不能访问了! 此项目是我负责,我以150+的手速立即打开了服务器, ...
- 洛谷 P1233 木棍加工 题解
题面 Dilworth定理:在数学理论中的序理论与组合数学中,Dilworth定理根据序列划分的最小数量的链描述了任何有限偏序集的宽度. 反链是一种偏序集,其任意两个元素不可比:而链则是一种任意两个元 ...