Net的网络层的构建(源码分析)
概述
网络层的构建是在Net<Dtype>::Init()函数中完成的,构建的流程图如下所示:
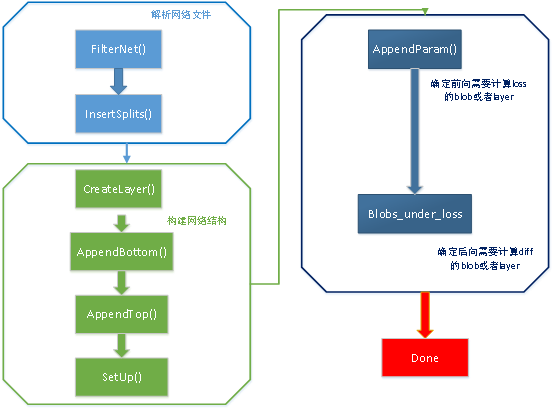
从图中可以看出网络层的构建分为三个主要部分:解析网络文件、开始建立网络层、网络层需要参与计算的位置。
解析网络文件
该部分主要有两个函数FilterNet()、InsertSplits()。
void Net<Dtype>::Init(const NetParameter& in_param) {
CHECK(Caffe::root_solver() || root_net_)
<< "root_net_ needs to be set for all non-root solvers";
// Set phase from the state.
phase_ = in_param.state().phase();
// Filter layers based on their include/exclude rules and
// the current NetState.
NetParameter filtered_param;
FilterNet(in_param, &filtered_param);
FilterNet()的作用是模型参数文件(*.prototxt)中的不符合规则的层去掉。例如:在caffe的examples/mnist中的lenet网络中,如果只是用于网络的前向,则需要将包含train的数据层去掉。
/*
*调用InsertSplits()函数,对于底层的一个输出blob对应多个上层的情况,
*则要在加入分裂层,形成新的网络。
*函数从filtered_param读入新网络到param
**/
InsertSplits(filtered_param, ¶m);
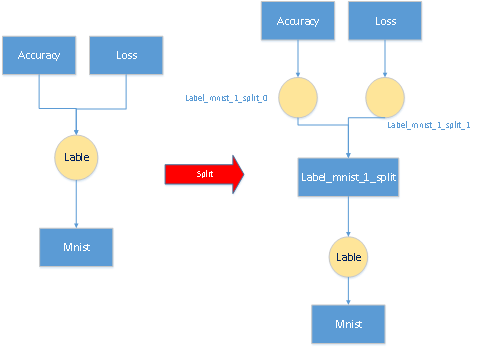
InsertSplits()函数的作用是对于底层的一个输出blob对应多个上层的情况,则要在加入分裂层,形成新的网络。这么做的主要原因是多个层反传给该blob的梯度需要累加。例如:LeNet网络中的数据层的top label blob对应两个输入层,分别是accuracy层和loss层,那么需要在数据层在插入一层。如下图:
建立网络层
该部分重要的函数有CreateLayer()、AppendBottom()、AppendTop()、SetUp()。
...............
//(很大的一个for循环)对每一层处理
for (int layer_id = ; layer_id < param.layer_size(); ++layer_id) {//开始遍历所有层
............
// Setup layer.
//param.layers(i)返回的是关于第当前层的参数:
const LayerParameter& layer_param = param.layer(layer_id);
if (share_from_root) {
............
} else {
/*
*把当前层的参数转换为shared_ptr<Layer<Dtype>>,
*创建一个具体的层,并压入到layers_中
*/
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));
}
对于CreateLayer()函数,把解析的当前层调用CreatorRegistry类进行注册,从而获取到当前层。然后会调用AppendBottom()和AppendTop()函数具体创建层结构。
//下面开始产生当前层:分别处理bottom的blob和top的blob两个步骤
for (int bottom_id = ; bottom_id < layer_param.bottom_size(); ++bottom_id) {
const int blob_id = AppendBottom(param, layer_id, bottom_id,
&available_blobs, &blob_name_to_idx);
need_backward |= blob_need_backward_[blob_id];
}
对于AppendBottom()函数,其作用是为该层创建bottom blob,由于网络是堆叠而成,即:当前层的输出 bottom是前一层的输出top blob,因此此函数并没没有真正的创建blob,只是在将前一层的指针压入到了bottom_vecs_中。
int num_top = layer_param.top_size();
for (int top_id = ; top_id < num_top; ++top_id) {
AppendTop(param, layer_id, top_id, &available_blobs, &blob_name_to_idx);
...............
}
对于AppendBottom()函数,其作用是为该层创建top blob,该函数真正的new的一个blob的对象。并将top blob 的指针压入到top_vecs_中。经过这两个函数网络层创建出该层所有的输入、输出blob,接下来就是调用SetUp()函数,正式建立层结构,并为blob分配内存空间。
//层已经连接完成,开始建立关系
if (share_from_root) {
// Set up size of top blobs using root_net_
const vector<Blob<Dtype>*>& base_top = root_net_->top_vecs_[layer_id];
const vector<Blob<Dtype>*>& this_top = this->top_vecs_[layer_id];
for (int top_id = ; top_id < base_top.size(); ++top_id) {
this_top[top_id]->ReshapeLike(*base_top[top_id]);
}
} else {
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
} //SetUp()函数的具体内容
void SetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
InitMutex();
CheckBlobCounts(bottom, top);
LayerSetUp(bottom, top);
Reshape(bottom, top);
SetLossWeights(top);
}
对于SetUp()函数,包含了CheckBlobCounts()、LayerSetUp()、SetLossWeights()、Reshape()等子函数,CheckBlobCounts()函数式读取Blob的数量,LayerSetUp()和Reshape()是虚函数,会在相应的层中实现这两个函数,SetLossWeights(top)函数会把top(输出blob)的loss weight进行初始化,loss weight是用来表示不同Layer产生的loss的重要性,Layer名称中以Loss结尾表示这是一个会产生loss的Layer,其他的Layer只是单纯的用于中间计算,同时每一层的loss值就是所有输出top blob的loss值的和。到此当前层的结构建立完成。经过多次循环,就可以构建整个网络。
确定网络层需要计算的blob
该部分的作用是确定哪些层或哪些层的blob需要参与计算,比如前向时需要确定哪些层的blob需要计算loss,后向时确定哪些层的blob需要计算diff。一个layer是否需要backward computation,主要依据两个方面:
(1)该layer的top blob 是否参与loss的计算;
(2)该layer的bottom blob 是否需要backward computation,比如Data层一般就不需要backward computation
对于前向的过程,部分源码如下:
..............
for (int param_id = ; param_id < num_param_blobs; ++param_id) {
const ParamSpec* param_spec = (param_id < param_size) ?
&layer_param.param(param_id) : &default_param_spec;
const bool param_need_backward = param_spec->lr_mult() != ;
need_backward |= param_need_backward;
layers_[layer_id]->set_param_propagate_down(param_id, param_need_backward);
}
for (int param_id = ; param_id < num_param_blobs; ++param_id) {
...........
AppendParam(param, layer_id, param_id);
}
AppendParam()函数的作用是记录带有参数的层或者blob,对于某些有参数的层,例如:卷基层、全连接层有weight和bias。该函数主要是修改和参数有关的变量,实际的层参数的blob在上面提到的setup()函数中已经创建。对于后向的过程和前向类似,部分源码如下:
if (param.force_backward()) {
for (int layer_id = ; layer_id < layers_.size(); ++layer_id) {//迭代所有层
layer_need_backward_[layer_id] = true;//需要参与backward
for (int bottom_id = ;
bottom_id < bottom_need_backward_[layer_id].size(); ++bottom_id) {//每一层下的需要计算diff的所有blob
bottom_need_backward_[layer_id][bottom_id] =
bottom_need_backward_[layer_id][bottom_id] ||
layers_[layer_id]->AllowForceBackward(bottom_id);
blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] =
blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] ||
bottom_need_backward_[layer_id][bottom_id];
}
for (int param_id = ; param_id < layers_[layer_id]->blobs().size();
++param_id) {//设置不需要计算参数的层
layers_[layer_id]->set_param_propagate_down(param_id, true);
}
}
}
Net的网络层的构建(源码分析)的更多相关文章
- MyBatis源码分析(4)—— Cache构建以及应用
@(MyBatis)[Cache] MyBatis源码分析--Cache构建以及应用 SqlSession使用缓存流程 如果开启了二级缓存,而Executor会使用CachingExecutor来装饰 ...
- Flink源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483692&idx=1&sn=18cddc1ee ...
- Elasticsearch源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483694&idx=1&sn=bd03afe5a ...
- 构建锁与同步组件的基石AQS:深入AQS的实现原理与源码分析
Java并发包(JUC)中提供了很多并发工具,这其中,很多我们耳熟能详的并发工具,譬如ReentrangLock.Semaphore,它们的实现都用到了一个共同的基类--AbstractQueuedS ...
- 鸿蒙内核源码分析(构建工具篇) | 顺瓜摸藤调试鸿蒙构建过程 | 百篇博客分析OpenHarmony源码 | v59.01
百篇博客系列篇.本篇为: v59.xx 鸿蒙内核源码分析(构建工具篇) | 顺瓜摸藤调试鸿蒙构建过程 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿 ...
- AFNetworking源码分析
来源:zongmumask 链接:http://www.jianshu.com/p/8eac5b1975de 简述 在iOS开发中,与直接使用苹果框架中提供的NSURLConnection或NSURL ...
- Kafka服务端之网络连接源码分析
#### 简介 上次我们通过分析KafkaProducer的源码了解了生产端的主要流程,今天学习下服务端的网络层主要做了什么,先看下 KafkaServer的整体架构图 的形式集成到ABP中.具体的功能都可以设计成一个单独的Module.Abp底层框架提供便捷的方法集成每个Modu ...
随机推荐
- 算法学习之选择排序算法的python实现
——参考自<算法图解> def findSmallest(arr): # 假设第一个元素最小 smallest = arr[0] smallest_index = 0 for i in r ...
- mysql 分页查询及优化
1.分页查询 select * from table limit startNum,pageSize 或者 select * from table limit pageSize offset star ...
- Spring Boot 之Profile
Profile Profile是Spring对不同环境提供不同配置功能的支持,可以通过激活.指定参数等方式快速切换环境. 1)多Profile文件 我们在主配置文件编写的时候,文件名可以是:appli ...
- H5 FormData对象
FormData对象 2018年01月08日 14:31:53 阅读数:2635 FormData对象,可以把所有表单元素的name与value组成一个queryString,提交到后台. 在使用aj ...
- :last-child----represents the last element among a group of sibling elements.
CSS伪类 :last-child 代表在一群兄弟元素中的最后一个元素. 举个例子: 从代码和图可以看出:last-child选择了最后一个li标签. 同时,我们换另外一段代码,看看是否还有这样的效果 ...
- 无法启动链接服务器"XXX DB Link"的 OLE DB 访问接口 "SQLNCLI11" 的嵌套事务。由于 XACT_ABORT 选项已设置为 OFF,因此必须使用嵌套事务。链接服务器"XXX DB Link"的 OLE DB 访问接口 "SQLNCLI11" 返回了消息"无法在此会话中启动更多的事务"。
无法启动链接服务器"XXX DB Link"的 OLE DB 访问接口 "SQLNCLI11" 的嵌套事务.由于 XACT_ABORT 选项已设置为 OFF,因 ...
- POJ 1161 Walls ( Floyd && 建图 )
题意 : 在某国,城市之间建起了长城,每一条长城连接两座城市.每条长城互不相交.因此,从一个区域到另一个区域,需要经过一些城镇或者穿过一些长城.任意两个城市A和B之间最多只有一条长城,一端在A城市, ...
- 2017乌鲁木齐网络赛 J题 Our Journey of Dalian Ends ( 最小费用最大流 )
题目链接 题意 : 给出一副图,大连是起点,终点是西安,要求你求出从起点到终点且经过中转点上海的最小花费是多少? 分析 : 最短路是最小费用最大流的一个特例,所以有些包含中转限制或者经过点次数有限制的 ...
- Java——对象转型
[对象转型]
- 判断img的src为空/点击时候两张图片来回替换
if($('.icon-right img').src==null){ $('.span-gray').addClass('c8'); } <img> ///////////// < ...