hadoop 与 hbase 添加开机启动,按顺序,先hadoop,后hbase,开机启动脚本,hbase学习
hadoop安装,hbase单机安装,参考链接,https://blog.csdn.net/LiuHuan_study/article/details/84347262
开机启动脚本,参考,
https://github.com/josonle/BigData-Learning
http://kittyandpuppy.coolplayer.net/HBase.pdf
hadoop版本,hadoop-2.7.7
hbase版本,hbase-1.4.10
名称hadoop-service脚本,
#!/bin/bash
# chkconfig:
# description: hadoop service
# It is used to serve HTML files and CGI.
# processname: hadoop
# Source function library.
. /etc/profile
# See how we were called.
case "$1" in
start)
echo "Starting hadoop..."
$HADOOP_HOME/sbin/start-all.sh
;;
stop)
echo "Stopping hadoop..."
$HADOOP_HOME/sbin/stop-all.sh
;;
restart)
echo "Restarting hadoop..."
exit
;;
*)
echo "Usage: $0 {start|stop}"
exit
;;
esac
exit
名称hbase-service启动脚本,
#!/bin/bash
# chkconfig: 91 89
# description: hbase service
# It is used to serve HTML files and CGI.
# processname: hbase
# Source function library.
. /etc/profile
# See how we were called.
case "$1" in
start)
echo "Starting hbase..."
$HBASE_HOME/bin/start-hbase.sh
;;
stop)
echo "Stopping hbase..."
$HBASE_HOME/bin/stop-hbase.sh
;;
restart)
echo "Restarting hbase..."
exit
;;
*)
echo "Usage: $0 {start|stop}"
exit
;;
esac
exit
放到 /etc/init.d目录下,然后
chmod +x hadoop-service
chkconfig hadoop-service on
chmod +x hbase-service
chkconfig hbase-service on
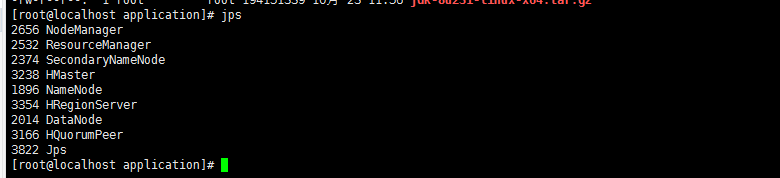
reboot后,jps查看进程,
hadoop 与 hbase 添加开机启动,按顺序,先hadoop,后hbase,开机启动脚本,hbase学习的更多相关文章
- centos修改启动顺序,登录后提示,启动级别,主机名,免密登录
修改启动顺序 # vim /etc/inittab ....... d:3:initdefault: #找到这一行,d:3:initdefault:最小化启动 d:5:initdefault:图形界 ...
- 双系统修改启动项顺序&&&修改开机启动等待时间
1. 双系统修改启动项顺序 更改/etc/grub.d目录 下的文件名是可行的 默认情况下Windows 7对应的文件名是30_os-prober,第一个linux系统对应的是10- ...
- linux中chkconfig 启动程序顺序介绍
1)redhat的启动方式和执行次序是: 加载内核 执行init程序 /etc/rc.d/rc.sysinit # 由init执行的第一个脚本 /etc/rc.d/rc $RUNLE ...
- linux 启动过程以及如何将进程加入开机自启
linux 启动流程 系统启动主要顺序就是: 1. 加载内核 2. 启动初始化进程 3. 确定运行级别 4. 加载开机启动程序 5. 用户登录 启动流程的具体细节可以看看Linux 的启动流程 第4步 ...
- Hadoop记录-Hadoop集群添加节点和删除节点
1.添加节点 A:新节点中添加账户,设置无密码登陆 B:Name节点中设置到新节点的无密码登陆 C:在Name节点slaves文件中添加新节点 D:在所有节点/etc/hosts文件中增加新节点(所有 ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- win7,Ubuntu 12.04 双系统修改启动项顺序三方法
修改启动项顺序的三种方法 本文所涉及的方法都是在Ubuntu的安装时将引导加载程序grub安装在了整个硬盘(即MBR内),即开机以grub引导. 方法1在Ubuntu终端下输入:sudo mv /et ...
- hadoop 2.7 添加或删除datanode节点
1.测试环境 ip 主机名 角色 10.124.147.22 hadoop1 namenode 10.124.147.23 hadoop2 namenode 10.124.147.32 hadoop3 ...
- 使用IDEA操作Hbase API 报错:org.apache.hadoop.hbase.client.RetriesExhaustedException的解决方法:
使用IDEA操作Hbase API 报错:org.apache.hadoop.hbase.client.RetriesExhaustedException的解决方法: 1.错误详情: Excepti ...
- 编写程序向HBase添加日志信息
关注公众号:分享电脑学习回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新) 承接上一篇文档<日志信息和浏览器信息获取及数据过滤> 上一个文档最好做个本地测试 ...
随机推荐
- tab栏切换效果运用案例
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- vlan的三种模式access、trunk、hybrid
untag就是普通的ethernet报文,普通PC机的网卡是可以识别这样的报文进行通讯:tag报文结构的变化是在源mac地址和目的mac地址之后,加上了4bytes的vlan信息,也就是vlan ta ...
- Ubuntu 14.04 下的MAC OS X 主题安装
Ubuntu 14.04 下的MAC OS X 主题安装 安装 MAC OS X 主题会帮助你的 Ubuntu 14.04 看起来更像MAC OS X.在这里我们介绍的Macbuntu安装包包含了GT ...
- 十大基本功之testbench
1. 激励的产生 对于testbench而言,端口应当和被测试的module一一对应.端口分为input,output和inout类型产生激励信号的时候,input对应的端口应当申明为reg, o ...
- 生成对抗网络资源 Adversarial Nets Papers
来源:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Papers ...
- 〇——什么是SHELL
在这段时间里中我们了解一下SHELL编程. 什么是shell shell是Linux的命令解释器,用于解释用户对操作系统的操作. 用shell解释的Linux命令有很多,可以通过cat/etc/she ...
- ESP8266-12F 中断
外部中断: 基于ESP8266的NodeMcu的数字IO的中断功能是通过attachInterrupt,detachInterrupt函数所支持的.除了D0/GPIO16,中断可以绑定到任意GPIO的 ...
- 内联元素的盒子模型与文档流定位padding属性
内联元素的盒子模型 1.内联元素不能设置width宽度和高度height span{width:200px ; height:200px} 与 span{width:100 ...
- 计蒜客 T2237 魔法 分类讨论
Code: #include<bits/stdc++.h> #define setIO(s) freopen(s".in","r",stdin) # ...
- luogu P1217 [USACO1.5]回文质数 Prime Palindromes x
P1217 [USACO1.5]回文质数 Prime Palindromes 题目描述 因为151既是一个质数又是一个回文数(从左到右和从右到左是看一样的),所以 151 是回文质数. 写一个程序来找 ...