MySQL使用explain时各字段解释

1、id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
三种情况:
(1)id相同,执行顺序由上至下

id相同,执行顺序由上至下
此例中 先执行where 后的第一条语句 t1.id = t2.id 通过 t1.id 关联 t2.id 。 而 t2.id 的结果建立在 t2.id=t3.id 的基础之上。
(2)id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行

id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
(3)id相同不同,同时存在

id如果相同,可以认为是一组,从上往下顺序执行;
在所有组中,id值越大,优先级越高,越先执行
衍生表 = derived2 --> derived + 2 (2 表示由 id =2 的查询衍生出来的表。type 肯定是 all ,因为衍生的表没有建立索引)
2、select_type
有哪些
查询的类型,主要是用于区别
普通查询、联合查询、子查询等的复杂查询
(1)SIMPLE
简单的 select 查询,查询中不包含子查询或者UNION

(2)PRIMARY
查询中若包含任何复杂的子部分,最外层查询则被标记为Primary

(3)DERIVED
在FROM列表中包含的子查询被标记为DERIVED(衍生) MySQL会递归执行这些子查询, 把结果放在临时表里。

DERIVED 既查询通过子查询查出来的 临时表
(4)SUBQUERY
在SELECT或WHERE列表中包含了子查询

(5)DEPENDENT SUBQUERY
在SELECT或WHERE列表中包含了子查询,子查询基于外层

dependent subquery 与 subquery 的区别
依赖子查询 : 子查询结果为 多值
子查询:查询结果为 单值
(6)UNCACHEABLE SUBQUREY
无法被缓存的子查询


图1 中的 @@ 表示查的环境参数 。没办法缓存
(7)UNION
若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED

UNION RESULT 两个语句执行完后的结果
(8)UNION RESULT
从UNION表获取结果的SELECT

3、table
显示这一行的数据是关于哪张表的
4、type

(1)访问类型排列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range(尽量保证) > index > ALL system>const>eq_ref>ref>range>index>ALL 一般来说,得保证查询至少达到range级别,最好能达到ref。
(2)显示查询使用了何种类型,从最好到最差依次是:system>const>eq_ref>ref>range>index>ALL(常用)
① system
表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
② const
表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快
如将主键置于where列表中,MySQL就能将该查询转换为一个常量

③ eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描

④ ref
非唯一性索引扫描,返回匹配某个单独值的所有行。
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,
它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体

⑤ range
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询
这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。


⑥ index
Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。
(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
⑦ all
Full Table Scan,将遍历全表以找到匹配的行


⑧ index_merge
在查询过程中需要多个索引组合使用,通常出现在有 or 的关键字的sql中

⑨ ref_or_null
对于某个字段既需要关联条件,也需要null值得情况下。查询优化器会选择用ref_or_null连接查询。

⑩ index_subquery
利用索引来关联子查询,不再全表扫描。



⑪ unique_subquery
该联接类型类似于index_subquery。 子查询中的唯一索引

备注:一般来说,得保证查询至少达到range级别,最好能达到ref。
5、possible_keys
显示可能应用在这张表中的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
6、key
实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
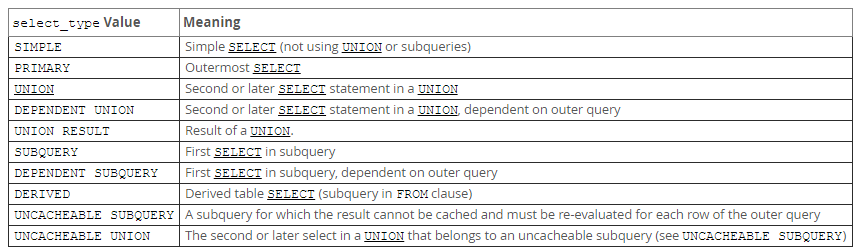
对比下图两个 sql 语句。和 key 的值:当查询具体某一字段时,且那个字段有索引时,key 值会显示为索引。

7、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
EXPLAIN SELECT * FROM emp WHERE emp.deptno=109 AND emp.`ename`='AvDEjl'
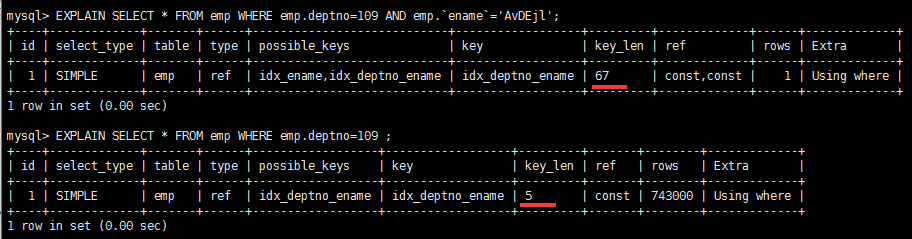
如何计算
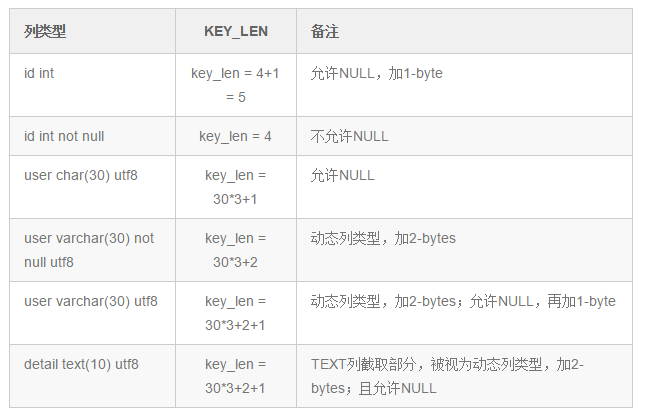
总结一下:char(30) utf8 --> key_len = 30*3 +1 表示 utf8 格式需要 *3 (跟数据类型有关)
允许为 NULL +1 ,不允许 +0
动态类型 +2 (动态类型包括 : varchar , detail text() 截取字符窜)

第一组:key_len=deptno(int)+null + ename(varchar(20)*3+动态 =4+1+20*3+2= 67
第二组:key_len=deptno(int)+null=4+1=5
key_len字段能够帮你检查是否充分的利用上了索引
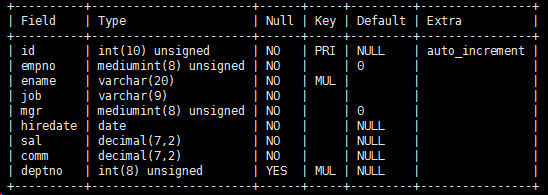
RESET QUERY CACHE ;
EXPLAIN SELECT emp.deptno,COUNT(*) c FROM emp
WHERE emp.ename LIKE 'a%' AND emp.deptno=109
GROUP BY emp.deptno
HAVING c >2
ORDER BY c DESC
同样的使用了索引但是索引的涉及的字段却不同。

下图可知,充分的利用了索引的查询效率会更高。
8、ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值

9、rows
rows列显示MySQL认为它执行查询时必须检查的行数。(越少越好)


10、Extra
包含不适合在其他列中显示但十分重要的额外信息
(1)Using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为“文件排序”
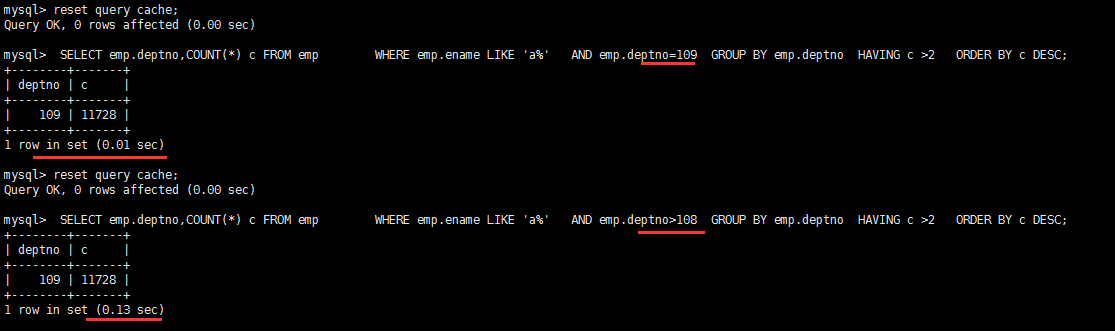
出现filesort的情况:

优化后,不再出现filesort的情况:(给 ename 加上了索引)

查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
分情况:当通过前面的查询语句 筛选大部分条件后,只剩下很少的数据。using filesort 性能影响不大。需要综合考虑
(2)Using temporary
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
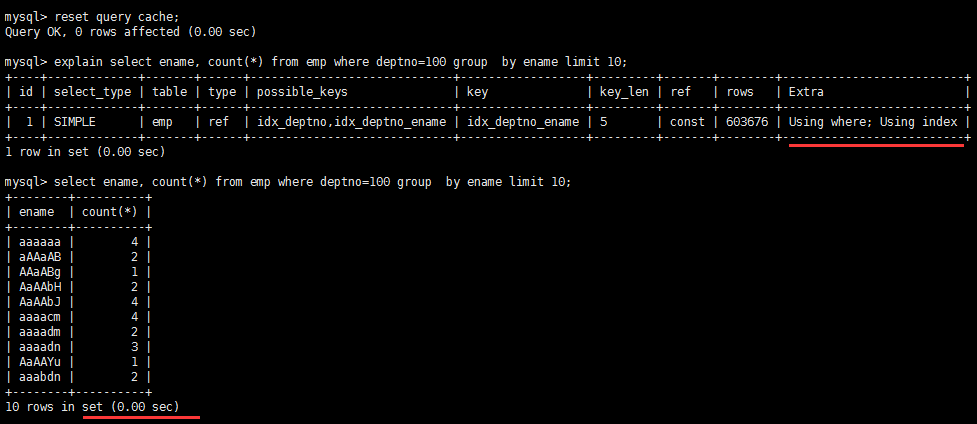
优化前存在 using temporary 和 using filesort

create index idx_deptno_ename on emp(deptno,ename) 后解决
优化前存在的 using temporary 和 using filesort 不在,性能发生明显变化:
(3)USING index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;
如果没有同时出现using where,表明索引只是用来读取数据而非利用索引执行查找。
覆盖索引(Covering Index)
索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。①一个索引 ②包含了(或覆盖了)[select子句]与查询条件[Where子句]中 ③所有需要的字段就叫做覆盖索引。
上句红字理解:
select id , name from t_xxx where age=18;
有一个组合索引 idx_id_name_age_xxx 包含了(覆盖了),id,name,age三个字段。查询时直接将建立了索引的列读取出来了,而不需要去查找所在行的其他数据。所以很高效。
(个人认为:在数据量较大,固定字段查询情况多时可以使用这种方法。)
注意:
如果要使用覆盖索引,一定要注意select列表中只取出需要的列,不可select *,
因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
(4)Using where
表明使用了where过滤
(5)using join buffer
使用了连接缓存:

出现在当两个连接时
驱动表(被连接的表,left join 左边的表。inner join 中数据少的表) 没有索引的情况下。
给驱动表建立索引可解决此问题。且 type 将改变成 ref
(6)impossible where
where子句的值总是false,不能用来获取任何元组

(7)select tables optimized away
在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者
对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,
查询执行计划生成的阶段即完成优化。
在innodb中:

在Myisam中:

myisam 中会维护 总行数 (还有其他参数)这个参数,所以在执行查询时不会进行全表扫描。而是直接读取这个数。
但会对增删产生一定的影响。根据业务情况决定谁好谁坏
innodb 中没有这个机制。
(补充:\G竖版排列,使用时sql语句后面不要加“;”)
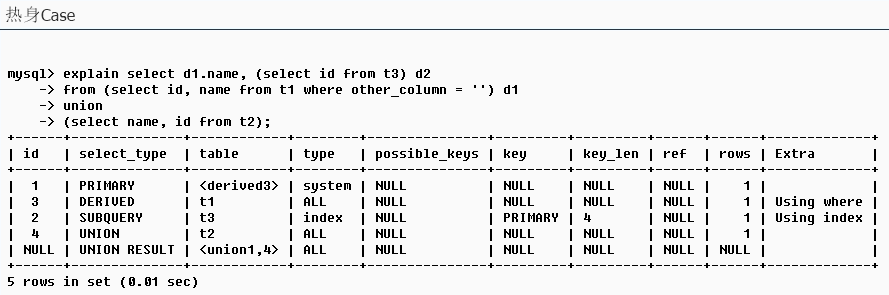
示例:写出执行顺序

MySQL使用explain时各字段解释的更多相关文章
- mysql中explain的type的解释
type -- 连接类型 type意味着类型,这里的type官方全称是“join type”,意思是“连接类型”,这样很容易给人一种错觉觉得必须需要俩个表以上才有连接类型.事实上这里的连接类型并非字面 ...
- MySQL新建数据库时utf8_general_ci编码解释
utf8_unicode_ci和utf8_general_ci对中英文来说没有实质的差别.utf8_general_ci: 校对速度快,但准确度稍差.utf8_unicode_ci: 准确度高,但校对 ...
- 详解MySQL中EXPLAIN解释命令
Explain 结果解读与实践 基于 MySQL 5.0.67 ,存储引擎 MyISAM . 注:单独一行的"%%"及"`"表示分隔内容,就象分开“第一 ...
- MySQL中EXPLAIN解释命令 查看索引是否生效
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: 如: expla ...
- MySQL之explain命令解释
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了.如: explai ...
- 详解MySQL中EXPLAIN解释命令(转)
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: 如: expla ...
- MySQL中EXPLAIN解释命令详解
MySQL中的explain命令显示了mysql如何使用索引来处理select语句以及连接表.explain显示的信息可以帮助选择更好的索引和写出更优化的查询语句. 1.EXPLAIN的使用方法:在s ...
- MySQL中EXPLAIN解释命令(转载)
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: 如: expla ...
- MySQL 创建表时,设置时间字段自己主动插入当前时间
MySQL 创建表时,设置时间字段自己主动插入当前时间 DROP TABLE IF EXISTS `CONTENT`; CREATE TABLE `CONTENT` ( `ID` char(20) N ...
随机推荐
- 【Python】学习笔记十四:循环进阶
range() 在Python中,for循环后的in跟随一个序列的话,循环每次使用的序列元素,而不是序列的下标. 我们继续开发range的功能,以实现下标对循环的控制: s = 'abcdefghj' ...
- mysql 数据增删改的总结
一.在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括 1.使用INSERT实现数据的插入2.UPDATE实现数据的更新3.使用DELETE实现数据的删除4.使用SELEC ...
- mysql中查看ef或efcore生成的sql语句
http://www.solves.com.cn/it/sjk/MYSQL/2019-07-01/1336.html 涉及命令 1.开启general log模式 MySQL>set globa ...
- linux C 加载so文件 指定路径
在Linux C中动态加载.so文件用dlopen("libdemo.so", RTLD_NOW); 但是默认的so搜索目录不包括当前程序目录,所以必须复制到系统的so目录 才能运 ...
- DAY 7 上午
一些图论的题目 BZOJ 3445 Roadblock 求出最短路,枚举每条边再跑一遍即可(科技为了我 代码: #include<bits/stdc++.h> using namespac ...
- 如何使用Jetbrains Clion 在一个工程里 编译单个C++源文件 (实现一键编译且运行)
这篇文章主要在下面这篇文章的基础上,先是实现了一键编译和一键运行两个单个功能,最后又进一步使用Clion自带的Custom Build Application实现编译且运行一键实现. https:// ...
- jquery版本轮播图(es5版本,兼容高)
优势:基于es5,兼容高.切换动画css配置,轻量,不包含多余代码,可扩展性很高,多个轮播图不会冲突,可配置独有namespace 注: 1.项目需要所写,所以只写了页码的切换,未写上一页下一页按钮, ...
- ubuntu用mentohust连接ruijie
32位 http://download.csdn.net/detail/yan456jie/8720395 64位 http://download.csdn.net/detail/yan456jie ...
- yarn.lock 是干什么的
概述 今天本地运行尤大的vue-hackernews-2.0,使用 yarn 命令安装,报错提示 node 版本必须大于7小于9,如下所示: error upath@1.0.4: The engine ...
- 阶段3 1.Mybatis_04.自定义Mybatis框架基于注解开发_3 基于注解的自定义再分析
这里只需要 一是连接数据库的 二是映射的 注解是class的方式 dom4j技术获取xml的数据,这是xml的方式获取的下面几个关键的点 注解的方式回去dao类里面的几个主要的信息 User黄色的部 ...