搭建hadoop单机版
一、准备工作
1.申请机器
1)修改配置:
申请虚拟机下来了,通过xshell连接进入,
主机名还是默认的,修改下,不然看着不习惯
>hostname 查看主机名
>vim /etc/sysconfig/network
按i、 I 、a、 A其中一个,进入输入模式
HOSTNAME=master 改成自己想要的名字
按Esc退出输入模式
:wq 保存并退出
要想改的名字生效,执行reboot,这个过程可能需要几分钟,然后再xshell连接
2、准备软件
1)安装java 1.8
java -version 发现有了,不用安装了,此步省略
2)python 也有了,不用安装了
3)上传文件
rz命令上传文件
bash: rz: command not found
发现rz命令不能用,需要安装
>rpm -qa lrzsz 查看安装版本,发现是空的,没安装
>yum -y install lrzsz 安装上传下载命令工具
>mkdir soft 新建存在文件目录
>cd soft
>rz 命令,执行文件上传,选择要上传的文件 hadoop-2.8.4.tar.gz
>tar -xvf hadoop-2.8.4.tar.gz 解压hadoop文件
在根目录创建hadoop目录,
将解压的hadoop文件夹移动到创建的hadoop目录
>mv hadoop-2.8.4 /hadoop
二、安装配置
1.java环境变量配置
>vim /etc/profile
JAVA_HOME=/opt/java/jdk1.8.0_181
JRE_HOME=/opt/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=.:$JAVA_HOME/bin:$PATH
>source /etc/profile 使配置生效
2.hadoop环境变量配置
>vim /etc/profile
export HADOOP_HOME=/hadoop/hadoop-2.8.4
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
>source /etc/profile 使配置生效
3.hadoop配置文件修改
在修改配置文件之前,创建hadoop临时目录
[root@master ~]# mkdir /root/hadoop
[root@master ~]# mkdir /root/hadoop/tmp
[root@master ~]# mkdir /root/hadoop/var
[root@master ~]# mkdir /root/hadoop/dfs
[root@master ~]# mkdir /root/hadoop/dfs/name
[root@master ~]# mkdir /root/hadoop/dfs/data
>cd /hadoop/hadoop-2.8.4/etc/hadoop 切换到hadoop配置文件目录
1)修改core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>hadoop tmp dir</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
2)修改 hadoop-env.sh
>vi hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}中${JAVA_HOME}修改成java具体安装目录
export JAVA_HOME=/opt/java/jdk1.8.0_181
3)修改hdfs-site.xml
>vi hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>
dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true
4)修改mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置文件配置完成。
三、启动hadoop
1.首次启动,需要初始化(格式化)
>cd /hadoop/hadoop-2.8.4/bin 切换到安装bin目录
>./hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
提示方法过时了,但不影响
conf.Configuration: error parsing conf mapred-site.xml
org.xml.sax.SAXParseException; systemId: file:/hadoop/hadoop-2.8.4/etc/hadoop/mapred-site.xml; lineNumber: 5; columnNumber: 2; The markup in the document following the root element must be well-formed.
报错了,看报错信息是mapred-site.xml文件没配置好,去看下发现没配置<configuration></configuration>根标签,加上根标签,去bin目录,重新执行
>./hadoop namenode -format
没报错就是格式化好了。
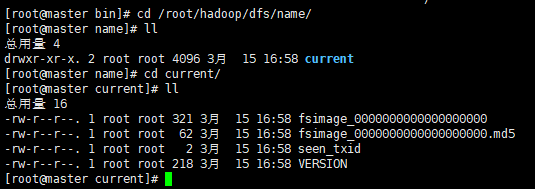
初始化成功后,可以在/root/hadoop/dfs/name 目录下(该路径在hdfs-site.xml文件中进行了相应配置,并新建了该文件夹)新增了一个current 目录以及一些文件。
2.启动hadoop:主要是启动HDFS和YARN
切换到sbin目录
>cd /hadoop/hadoop-2.8.4/sbin/
>start-dfs.sh 启动HDFS
Are you sure you want to continue connecting (yes/no)?
yes
root@master's password: ******

启动过程中,可以看到,先启动namenode服务,再启动datanode服务,最后启动secondarynamenode服务
HDFS启动成功了。
启动YARN
>start-yarn.sh

从打印日志中,可以看到启动yarn实际是启动yarn的daemons守护进程,再启动nodemanager节点管理器
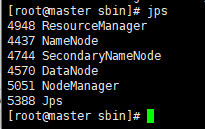
通过 jps命令查看hadoop服务是否启动成功:
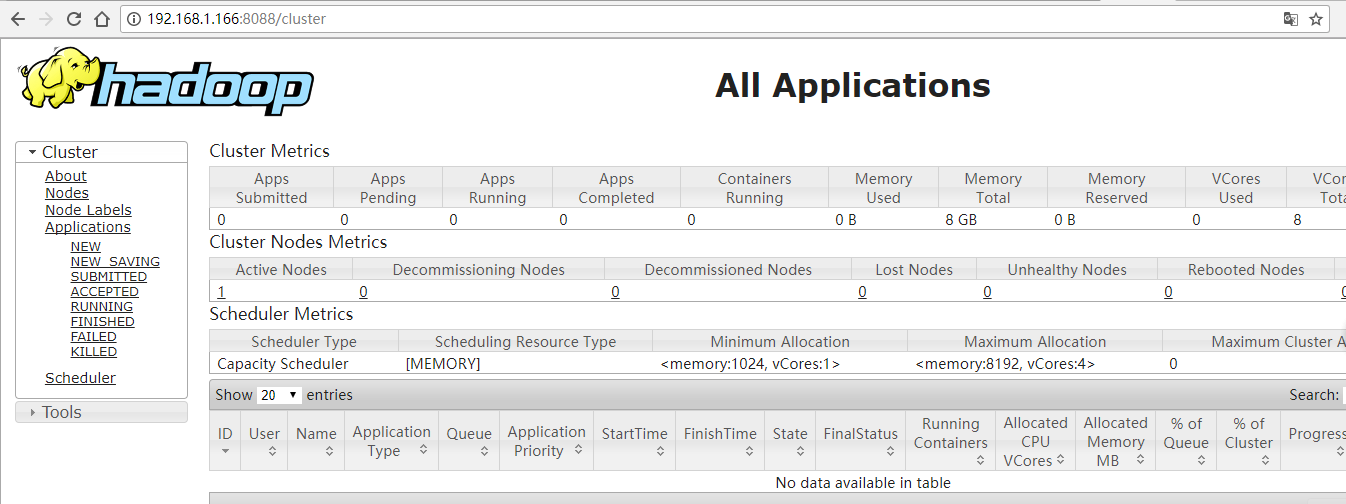
在浏览器中可以访问:
http://192.168.1.1**:8088/cluster
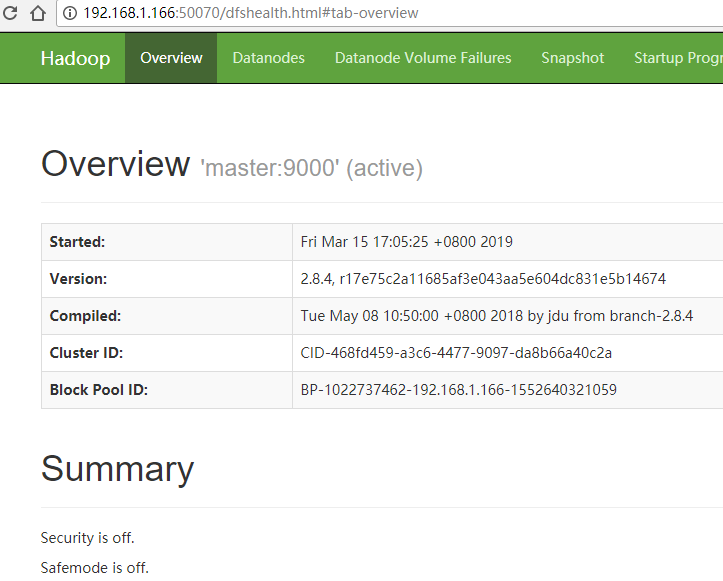
到此部署成功了。
http://192.168.1.1**:50070
搭建hadoop单机版的更多相关文章
- Ubuntu 12.04搭建hadoop单机版环境
前言: 本文章是转载的,自己又加上了一些自己的笔记整理的 详细地址请查看Ubuntu 12.04搭建hadoop单机版环境 Hadoop的三种运行模式 独立模式:无需任何守护进程,所有程序都在单个JV ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- (转)超详细单机版搭建hadoop环境图文解析
超详细单机版搭建hadoop环境图文解析 安装过程: 一.安装Linux操作系统 二.在Ubuntu下创建hadoop用户组和用户 三.在Ubuntu下安装 ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- VM+CentOS+hadoop2.7搭建hadoop完全分布式集群
写在前边的话: 最近找了一个云计算开发的工作,本以为来了会直接做一些敲代码,处理数据的活,没想到师父给了我一个课题“基于质量数据的大数据分析”,那么问题来了首先要做的就是搭建这样一个平台,毫无疑问,底 ...
- 基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建. 首先下载所需要的包: 1. Hadoop包: hadoop-2.5.2.tar ...
- Windows环境下搭建Hadoop(2.6.0)+Hive(2.2.0)环境并连接Kettle(6.0)
前提:配置JDK1.8环境,并配置相应的环境变量,JAVA_HOME 一.Hadoop的安装 1.1 下载Hadoop (2.6.0) http://hadoop.apache.org/release ...
- [Hadoop] 在Ubuntu系统上一步步搭建Hadoop(单机模式)
1 Hadoop的三种创建模式 单机模式操作是Hadoop的默认操作模式,当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,会保守地选择最小配置,即单机模式.该模式主要用于开发调试M ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
随机推荐
- VS2015服务器资源管理器连接Mysql数据库
下载安装文件mysql-for-visualstudio-1.2.3.msi 下载成功后执行安装,选择change-->选择Custom安装成功后,发现vs中没有效果. 注意这里再次执行安装文件 ...
- 史上最简单的CentOS7破解密码方法,有图有真相
#############破解CentOS7密码详细过程 一.开机重启,按任意键停住,有时没停住,是鼠标键未在服务器中,点一下就好 二.按e键进入单用户模式 三.在UTF-8后面加上i ...
- 使用Zabbix进行IPMI监控
1. 安装IPMItool软件包 # yum -y install OpenIPMI OpenIPMI-devel ipmitoolfreeipmi 2. 配置Zabbix 服务器端配置z ...
- CNN卷积汇总
1,卷积作用:减少参数(卷积核参数共享),卷积过程中不断对上一个输出进行抽象,由局部特征归纳为全局特征(不同卷积层可视化可以观察到这点) 2,卷积核 早期卷积核由人工总结,如图像处理中有: 深度神经网 ...
- ctype.h头文件
定义了一批C语言字符分类函数(C character classification functions),用于测试字符是否属于特定的字符类别,如字母字符.控制字符等等.既支持单字节(Byte)字符,也 ...
- Python操作 RabbitMQ、Redis、Memcache
Python操作 RabbitMQ.Redis.Memcache Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数 ...
- 2017.10.28 C组比赛总结
这次比赛有点坑... [GDKOI2004]石子游戏 方法:判断奇偶性 输入n 如果n是奇数,输出 xiaoshi 如果n是偶数,输出 xiaoyong 比赛得分:30 错因:找错规律了(忘记了两个人 ...
- # vmware异常关机后,虚拟系统无法启动的解决办法
vmware异常关机后,虚拟系统无法启动的解决办法 先使用everything搜索所有后缀为.lck的文件,这些文件全部删除,如果不确定是否可以删除,先把这些文件转移到桌面,等能启动虚拟系统之后再删除 ...
- 打印指针要用%p而不要用%x
注意: 打印指针要用%p而不要用%x 原因: https://boredzo.org/blog/archives/2007-01-23/please-do-not-use-percent-x-for- ...
- php 如何生成path及其日常维护
php 如何生成path及其日常维护 path字段重要性不言而喻,在查询的时候,如果只用pid,查询效率会很低,增加path,查询效率大大提高,最起码不用递归查库了,重点是维护推荐关系的时候要维护pa ...