Task4.文本表示:从one-hot到word2vec
参考:https://blog.csdn.net/wxyangid/article/details/80209156
1.one-hot编码
中文名叫独热编码、一位有效编码。方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有其独立的寄存器位,并且任意时刻,有且仅有一个状态位是有效的。比如,手写数字识别,数字为0-9共10个,那么每个数字的one-hot编码为10位,数字i的第i位为1,其余为0,如数字2的one-hot表示为:[0,0,1,0,0,0,0,0,0,0]。
1.2one-hot在提取文本特征上的应用
one-hot在特征提取上属于词袋模型(bags of words)
假设语料库有这么三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
对语料库分词并进行编号
1我;2爱;3爸爸;4妈妈;5中国
对每段话用onehot提取特征向量
则三段话由onehot表示为:
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 ->1,1,1,1,0
爸爸妈妈爱中国 ->0,1,1,1,1
优点:可以将数据用onehot进行离散化,在一定程度上起到了扩充特征的作用
缺点:没有考虑词与词之间的顺序,并且假设词与词之间相互独立,得到的特征是离散稀疏的(如果365天用onehot,就是365维,会很稀疏)
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
有如下三个特征属性:
性别:["male","female"] # 所有可能取值,0,1 两种情况
地区:["Europe","US","Asia"] #0,1,2 三种情况
浏览器:["Firefox","Chrome","Safari","Internet Explorer"] #0,1,2,3四种情况
所以样本的第一维只能是0或者1,第二维是0,1,2三种情况中的一种,第三维,是0,1,2,3四种情况中的一种。
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对上述问题,我们发现性别2维,地区3维,浏览器4维则我们进行onehot编码需要9维。对["male","US","Internet Explorer"]进行onehot编码为:[1,0,0,1,0,0,0,0,1]
下面看如何用代码实现:
from sklearn import preprocessing
oh = preprocessing.OneHotEncoder()
oh.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])#四个样本
oh.transform([[0,1,3]]).toarray()
结果:[[ 1. 0. 0. 1. 0. 0. 0. 0. 1.]]
[0,0,3] #表示是该样本是,male Europe Internet Explorer
[1,1,0] #表示是 female,us Firefox
[0,2,1]#表示是 male Asia Chrome
[1,0,2] #表示是 female Europe Safari
word2vec
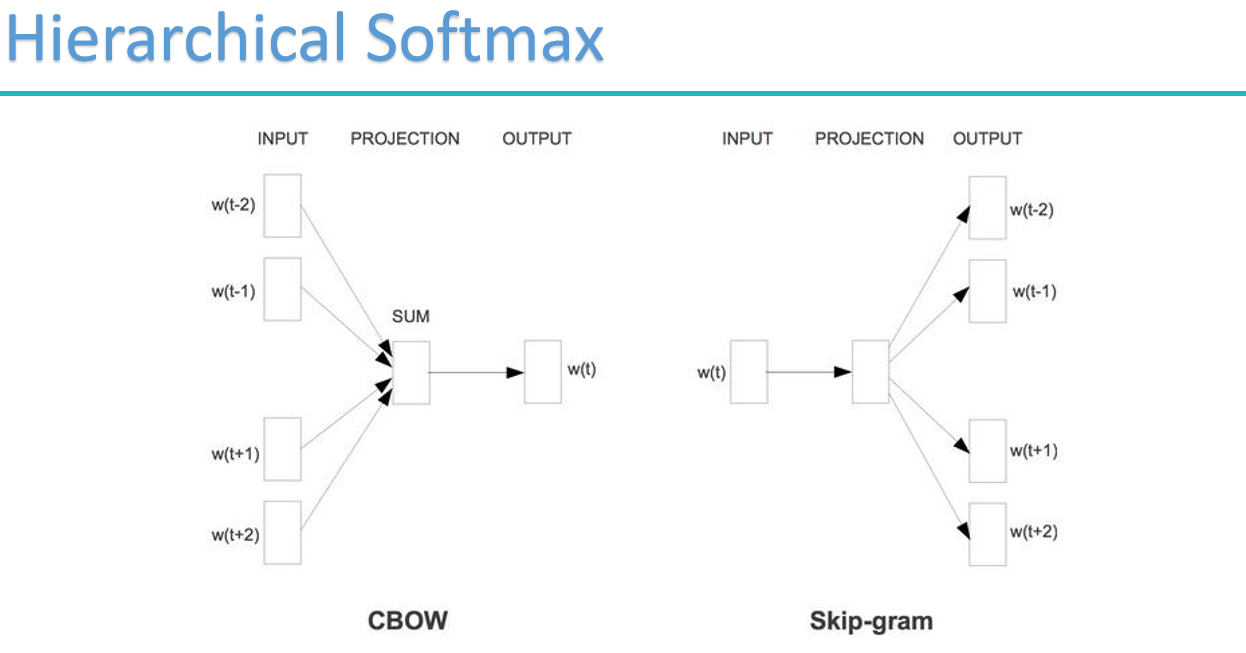
word2vec的两种重要模型:






梯度计算



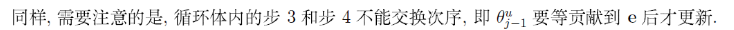

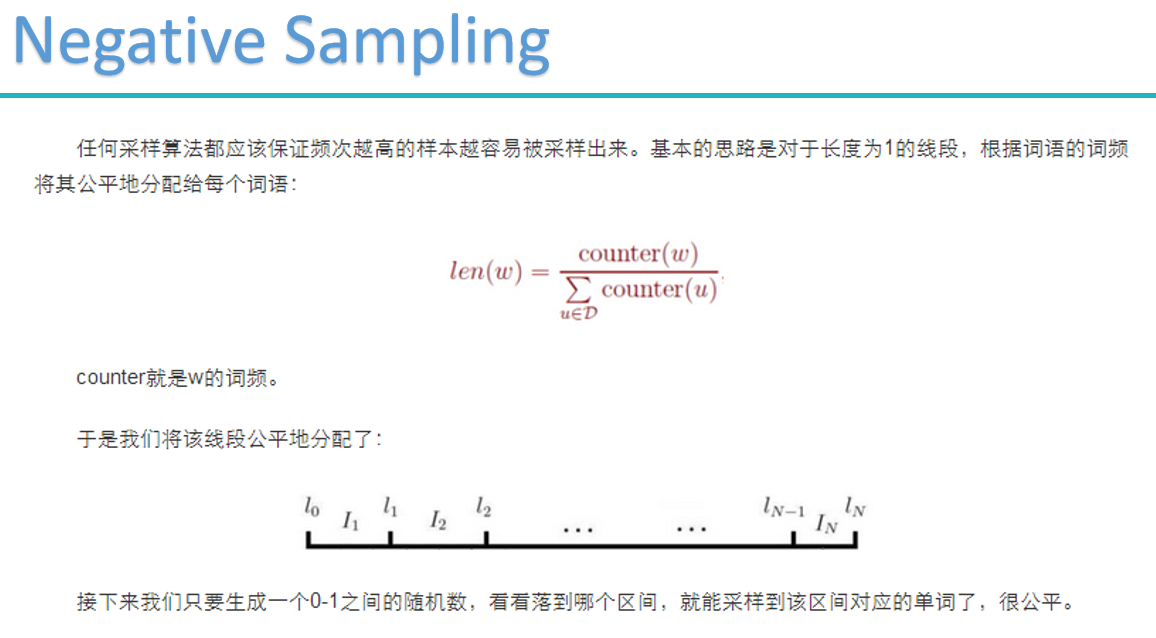



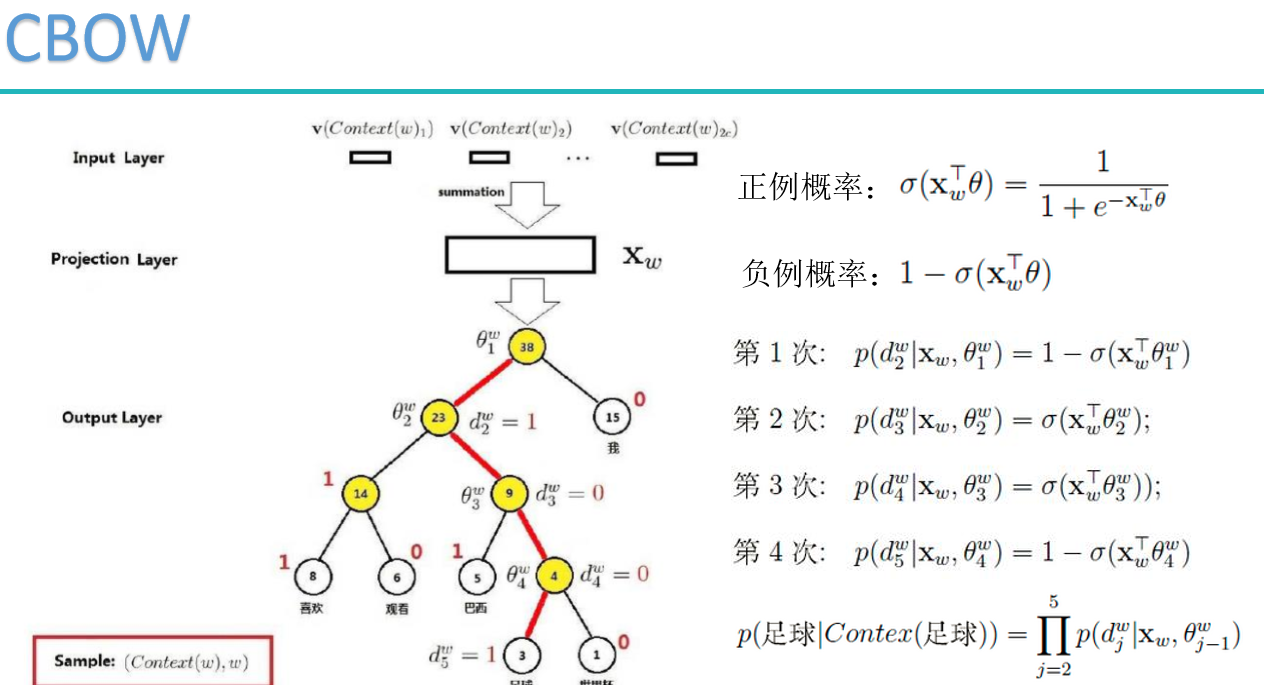
cbow:

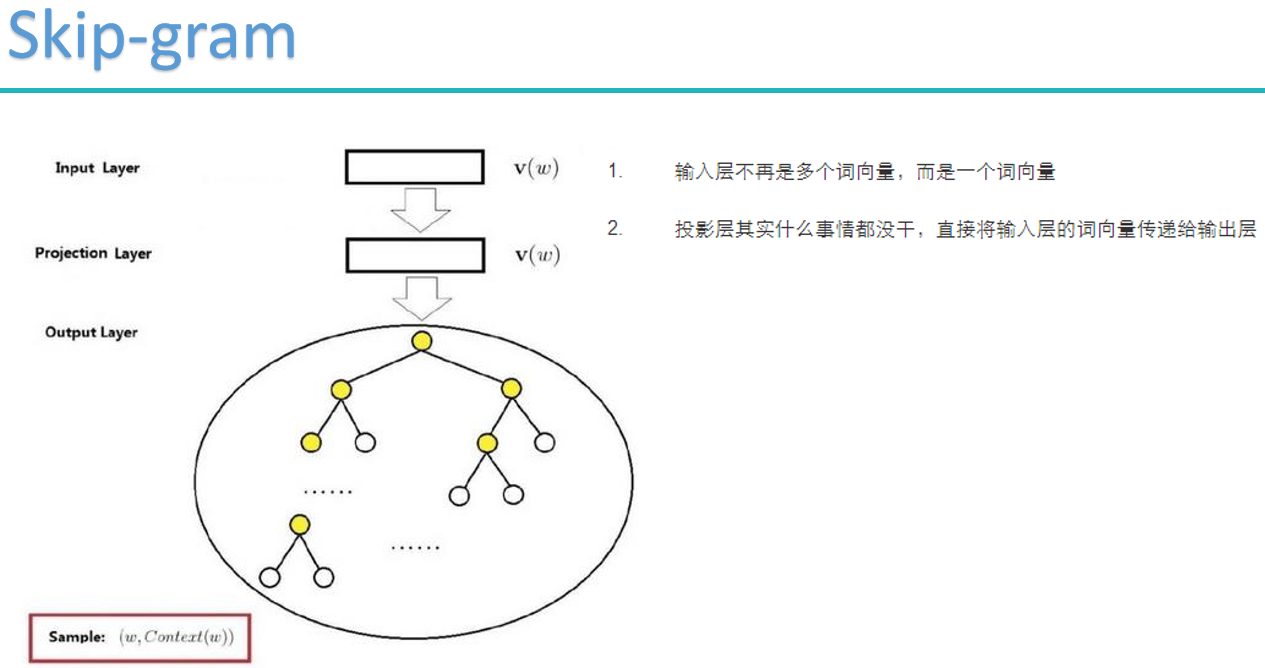
skip-gram




Task4.文本表示:从one-hot到word2vec的更多相关文章
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(九)—— ELMO 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(六)—— RCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- qbzt day6 上午
还是合并石子,但是这次可以任意两个合并,并且求最大异或和 f[s]表示把s所对应的的石子合并为一堆的最小代价 最后求f[2^n-1] 怎么转移? 最后一次也是把两堆合并成一堆,但是会有很多情况,可以枚 ...
- python进行数据库迁移的时候显示(TypeError: __init__() missing 1 required positional argument: 'on_delete')
进行数据库迁移的时候,显示 TypeError: __init__() missing 1 required positional argument: 'on_delete' 图示: 出现原因: 在 ...
- base64编解码的另外几个版本
#include "crypto/encode/base64.h" static const std::string base64_chars = "ABCDEFGHIJ ...
- GMS测试常用命令CTS>S&VTS
本文档介绍一下cts,gts,sts,vts,cts-on-gsi等测试的常用命令,基于Android9. [附件]Google官网的命令网页. 常用通用命令参数: 列出历史测试结果:l r 指定设备 ...
- 函数参数python
函数中的默认参数,调用的时候可以给参数 赋值,也可以使用默认值 修改add函数如下 add()函数第一个参数没有默认值,第二个函数b默认值是3,在调用函数的时候,只赋予了函数实际参数为2, 也就是说该 ...
- python函数-基础知识
一.含义函数是程序内的“小程序” 二.示例 #!/usr/bin/env python #coding:utf-8 def hello(): print('Hello world!') print(' ...
- SpringMvc+Mybatis开发调用存储过程
<mapper namespace="com.jkw100.ssm.mapper.CustomerMapperCustom" > <!-- statementTy ...
- ML5238电池管理芯片笔记
根据公司需要开发了以ML5238电池管理芯片+STM8S为核心的电池管理系统.由于前期对BMS系统还是了解甚少,开发起来也遇到了不少困难.再开发管理系统的同时,我也开发了管理系统的上位机, ...
- Django中用 form 实现登录注册
1.forms模块 将Models和Forms结合到一起使用,将Forms中的类和Models中的类关联到一起,实现属性的共享 1.在forms.py中创建class,继承自forms.ModelFo ...
- 1897. tank 坦克游戏
传送门 显然考虑 $dp$,发现时间只和当前位置和攻击次数有关,设 $F[i][j][k]$ 表示当前位置为 $i,j$ ,攻击了 $k$ 次得到的最大分数 初始 $f[1][1][k]$ 为位置 $ ...