机器学习-LDA主题模型笔记
LDA常见的应用方向:
信息提取和搜索(语义分析);文档分类/聚类、文章摘要、社区挖掘;基于内容的图像聚类、目标识别(以及其他计算机视觉应用);生物信息数据的应用;
对于朴素贝叶斯模型来说,可以胜任许多文本分类问题,但无法解决语料中一词多义和多词一义的问题--它更像是词法分析,而非语义分析。如果使用词向量作为文档的特征,一词多义和多词一义会造成计算文档间相似度的不准确性。LDA模型通过增加“主题”的方式,一定程度的解决上述问题:
一个词可能被映射到多个主题中,即,一词多义。多个词可能被映射到某个主题的概率很高,即,多词一义。
LDA涉及的主要问题
1)共轭先验分布
2)Dirichlet分布
3)LDA模型
Gibbs采样算法学习参数
共轭先验分布
由于x为给定样本,P(x)有时被称为“证据”,仅仅是归一化因子,如果不关心P(θ|x)的具体值,只考察θ取何值时后验概率P(θ|x)最大,则可将分母省去。
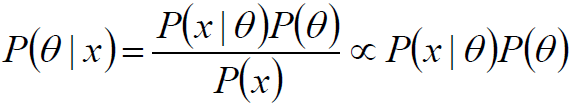
在贝叶斯概率理论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
Dirichlet分布
在学习Dirichlet分布之前先复习以下二项分布的最大似然估计:
投硬币试验中,进行N次独立试验,n次朝上,N-n次朝下。假定朝上的概率为p,使用对数似然函数作为目标函数:
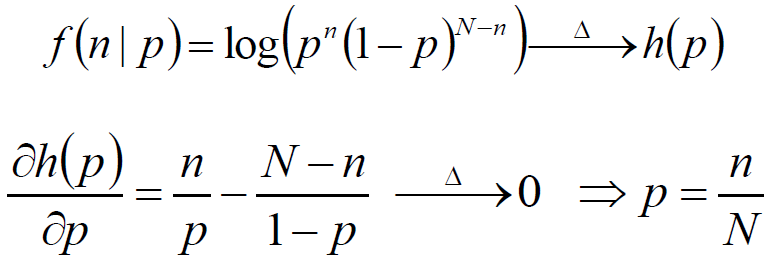
上述过程的理论解释
投掷一个非均匀硬币,可以使用参数为θ的伯努利模型,θ为硬币为正面的概率,那么结果x的分布形式为:
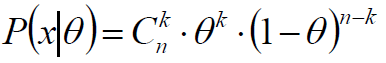
两点分布/二项分布的共轭先验是Beta分布,它具有两个参数α和β,Beta分布形式为
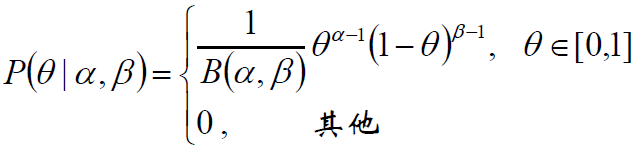
先验概率和后验概率的关系
根据似然和先验:
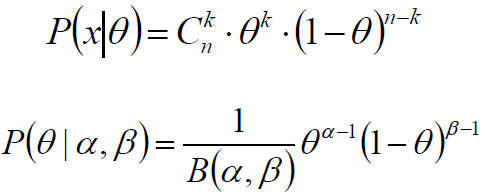
计算后验概率:
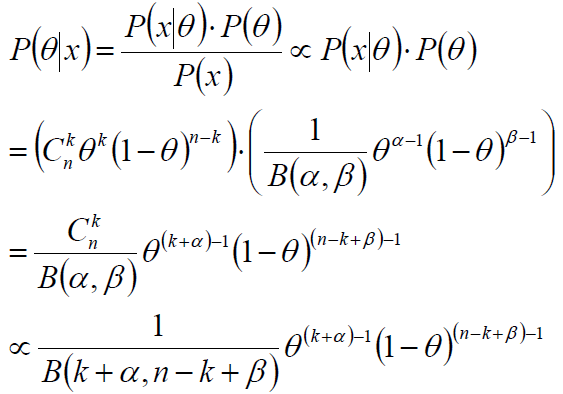
后验概率是参数为(k+α,n-k+β)的Beta分布,即:伯努利分布/二项分布的共轭先验是Beta分布。
参数α、β是决定参数θ的参数,即超参数。
在后验概率的最终表达式中,参数α、β和k、n-k一起作为参数θ的指数——后验概率的参数为(k+α,n-k+β)。
根据这个指数的实践意义:投币过程中,正面朝上的次数,α和β先验性的给出了在没有任何实验的前提下,硬币朝上的概率分配;因此,α和β可被称作“伪计数”。
共轭先验的直接推广
从2到K:二项分布→多项分布,Beta分布→Dirichlet分布
Dirichlet分布
复习—Beta分布中的B(α,β)的表示:
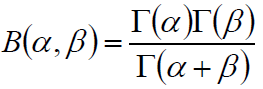
Dirichlet分布:
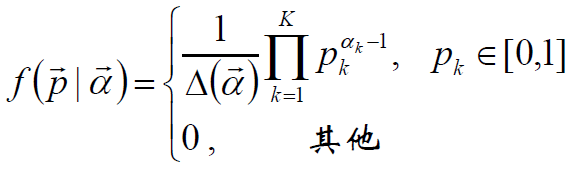
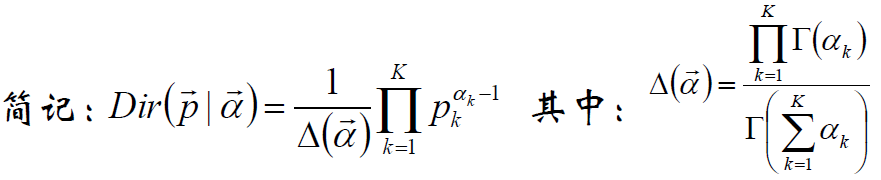
Dirichlet分布的期望
根据Beta分布的期望公式:
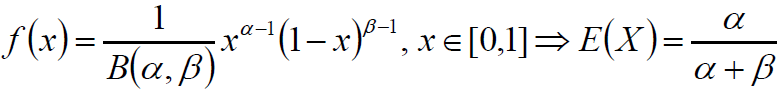
推广得到:

Dirichlet分布分析
α是参数向量,共K个,定义在x1,x2…xK-1维上:
x1+x2+…+xK-1+xK=1
x1,x2…xK-1>0
定义在(K-1)维的单纯形上,其他区域的概率密度为0
对称Dirichlet分布
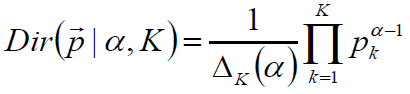
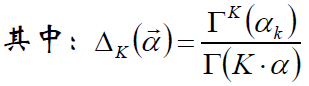
α=1时,退化为均匀分布
α>1时,p1=p2=...=pk的概率增大
α<1时,pi=1,p¬i=0的概率增大
多项分布的共轭分布是Dirichlet分布
调参经验传授:做LDA的时候,在条件允许的情况下,α值尽量不要设置太大,这样做的好处是充分考虑样本的因素,而不要过分考虑先验参数的影响。
当然,如果先验给的大,就是更多考虑先验,而不是样本。这需要充分根据实际情况决定,如果说我们认为样本的情况是重要的,就不要加入太大的先验。
LDA的解释
1)共有m篇文章,一共涉及了K个主题;
2)每篇文章(长度为Nm)都有各自的主题分布,主题分布是多项分布,该多项分布的参数服从Dirichlet分布,该Dirichlet分布的参数为α;
3)每个主题都有各自的词分布,词分布为多项分布,该多项分布的参数服从Dirichlet分布,该Dirichlet分布的参数为β;
4)对于某篇文章中的第n个词,首先从该文章的主题分布中采样一个主题,然后在这个主题对应的词分布中采样一个词。不断重复这个随机生成过程,直到m篇文章全部完成上述过程。

详细解释:此段非常有利于理解LDA主题模型
1)字典中共有V个term(不可重复),这些term出现在具体的文章中,就是word——在具体某文章中的word当然是有可能重复的。
2)语料库中共有m篇文档d1,d2…dm;
3)对于文档di,由Ni个word组成,可重复;
4)语料库中共有K个主题T1,T2…Tk;
5)α和β为先验分布的参数,一般事先给定:如取0.1的对称Dirichlet分布——表示在参数学习结束后,期望每个文档的主题不会十分集中。
6)θ是每篇文档的主题分布
对于第i篇文档di的主题分布是θi=(θi1, θi2…,θiK),是长度为K的向量;
7)对于第i篇文档di,在主题分布θi下,可以确定一个具体的主题zij=k,k∈[1,K]
8)φk表示第k个主题的词分布,k∈[1,K]
对于第k个主题Tk的词分布φk=(φk1, φk2… φkv),是长度为v的向量
9)由zij选择φzij,表示由词分布φzij确定term,即得到观测值wij。
10)图中K为主题个数,M为文档总数,Nm是第m个文档的单词总数。β是每个Topic下词的多项分布的Dirichlet先验参数,α是每个文档下Topic的多项分布的Dirichlet先验参数。zmn是第m个文档中第n个词的主题,wmn是m个文档中的第n个词。两个隐含变量θ和φ分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)
参数的学习
给定一个文档集合,wmn是可以观察到的已知变量,α和β是根据经验给定的先验参数,其他的变量zmn、θ、φ都是未知的隐含变量,需要根据观察到的变量来学习估计的。根据LDA的图模型,可以写出所有变量的联合分布:
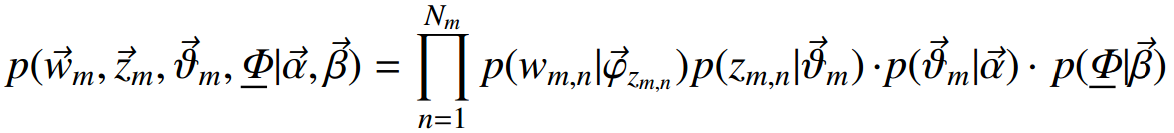
似然概率:
一个词wmn初始化为一个词t的概率是:
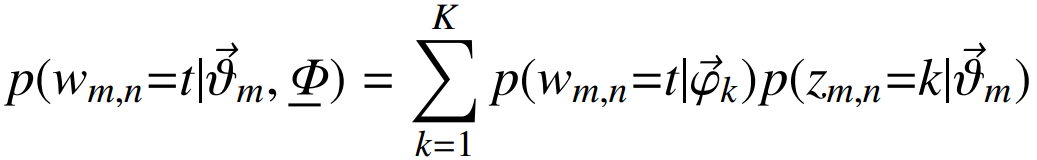
每个文档中出现主题k的概率乘以主题k下出现词t的概率,然后枚举所有主题求和得到。整个文档集合的似然函数为:
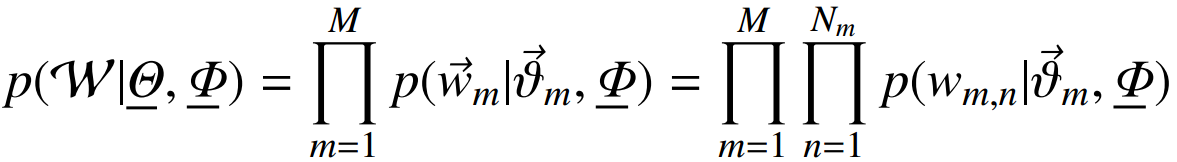
Gibbs Sampling吉布斯采样
1)Gibbs Sampling算法的运行方式是每次选取概率向量的一个维度,给定其他维度的变量值采样当前维度的值。不断迭代直到收敛输出待估计的参数。
2)初始时随机给文本中的每个词分配主题z(0),然后统计每个主题z下出现词t的数量以及每个文档m下出现主题z的数量,每一轮计算p(zi|z-i,d,w),即排除当前词的主题分布:
根据其他所有词的主题分布估计当前词分配各个主题的概率。
3)当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词采样一个新的主题。
4)用同样的方法更新下一个词的主题,直到发现每个文档的主题分布θi和每个主题的词分布φj收敛,算法停止,输出待估计的参数θ和φ,同时每个单词的主题zmn也可同时得出。
5)实际应用中会设置最大迭代次数。每一次计算p(zi|z-i,d,w)的公式称为Gibbs updating rule。
联合分布:
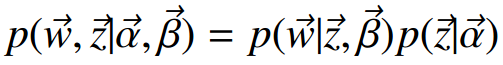
第一项因子是给定主题采样词的过程
后面的因子计算,nz(t)表示词t被观察到分配给主题z的次数, nm(k) 表示主题k分配给文档m的次数。
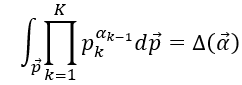
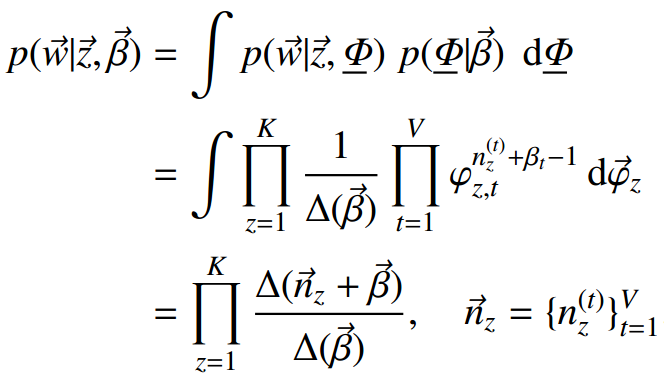
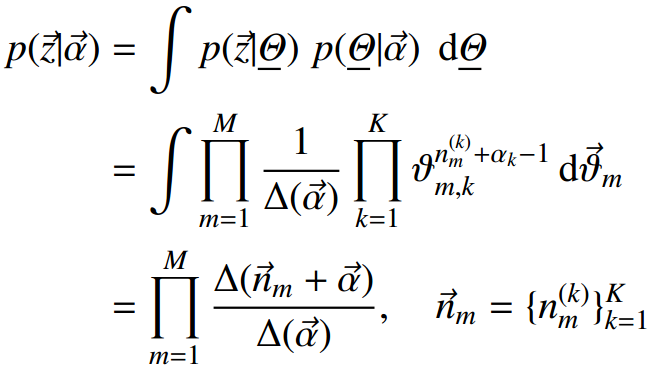
Gibbs updating rule:
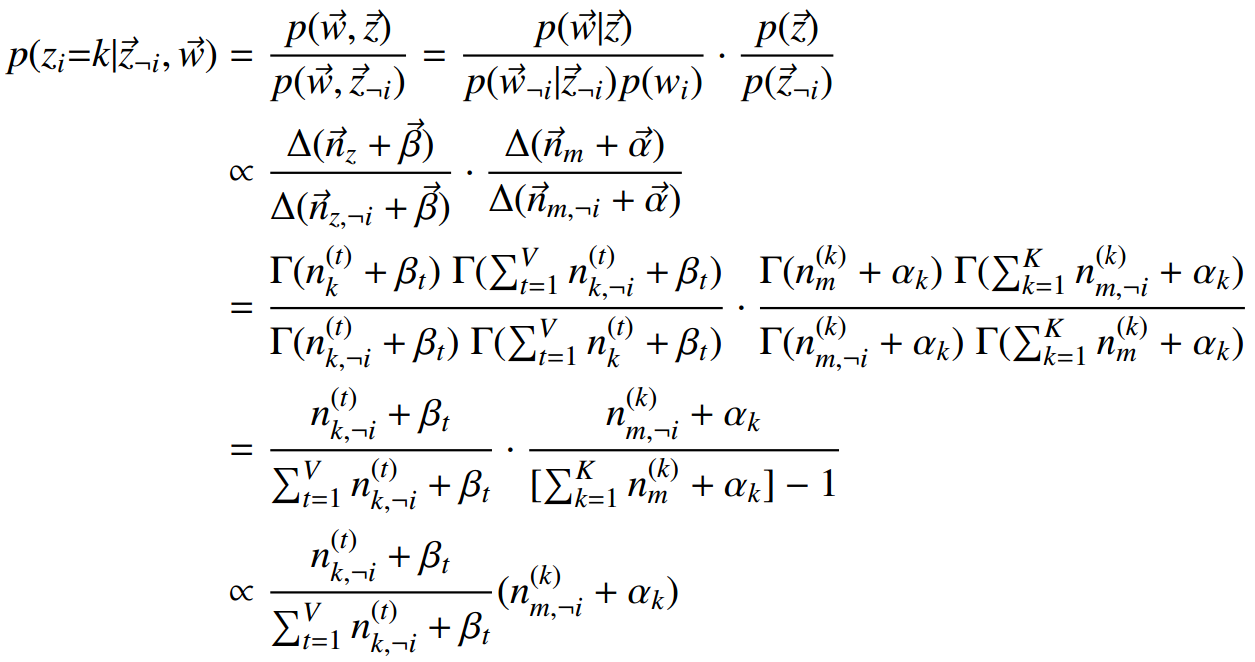
词分布和主题分布:
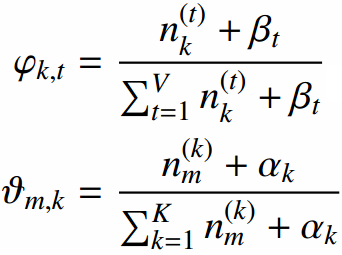
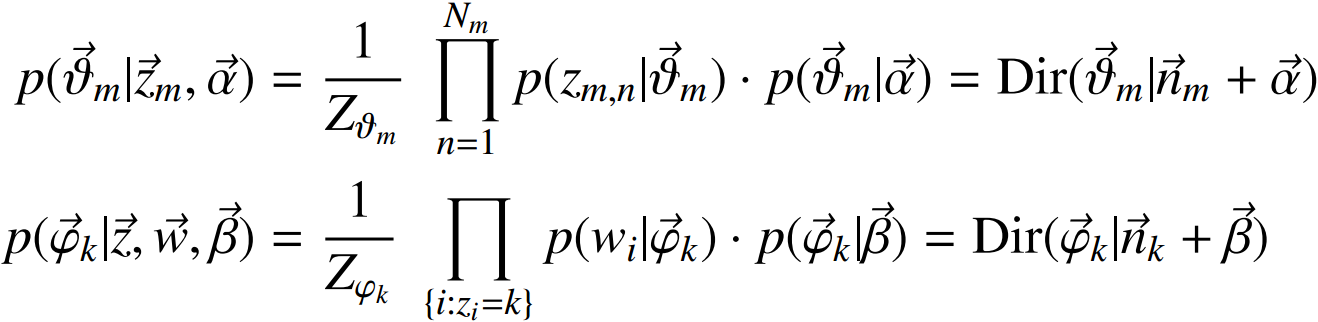
超参数的确定
1)交叉验证
2)α表达了不同文档间主题是否鲜明,β度量了有多少近义词能够属于同一个类别。
3)主题数目K,词项数目为W,可以使用:
α=50/K
β=200/W
注:不一定普遍适用
一种迭代求超参数的方法:
Digamma函数:
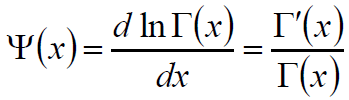
迭代公式:(T. Minka)
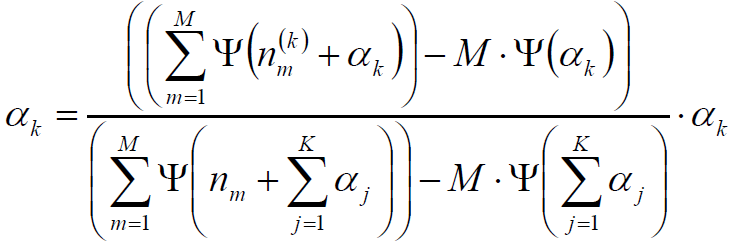
主题个数的确定
1)相似度最小
2)选取初始的主题个数K,训练LDA模型,计算各主题之间的相似度
3)增加或减少K的值,重新训练LDA模型,再次计算topic之间的相似度
4)选择相似度最小的模型所对应的K作为主题个数。
概率分布的困惑度/复杂度Perplexity
某离散概率分布p的困惑度为:
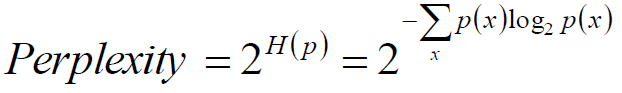
样本集x1,x2…xn的估计模型q的困惑度为:
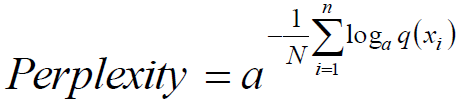
a为任意整数。
交叉熵为:
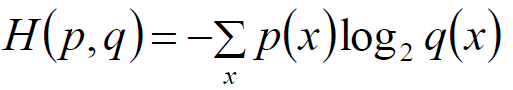
困惑度Perplexity与主题模型
使用训练数据得到无监督模型,在测试数据集中计算所有token似然值几何平均数的倒数。
测试数据集中词典大小的期望
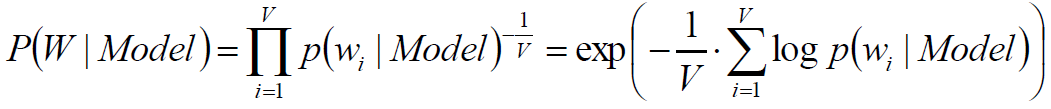
其中,LDA中词的似然概率为:
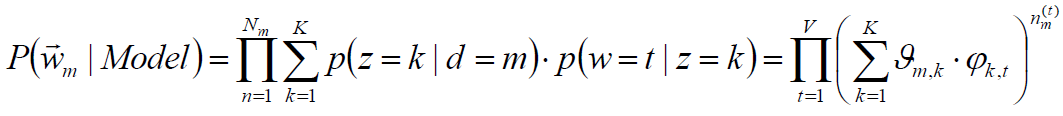
PageRank
一个网页i的重要度可以使用指向网页i的其他网页j的重要度加权得到。
权值不妨取网页j包含的链接数目。
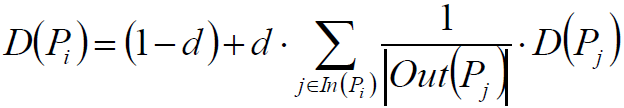
参数的意义为:
1)网页i的中重要性D(Pi)
2)阻尼系数d,如设置为常系数0.85
3)指向网页i的网页集合ln(Pi)
4)网页j指向的网页集合Out(Pj)
TextRank
将PageRank中的“网页”换成“词”,结论仍成立。
选择合适的窗口大小,认为窗口内的词相互指向。
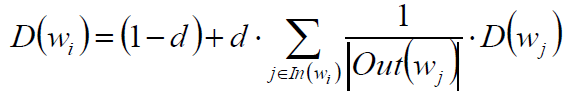
句子Si和Sj的相似度:
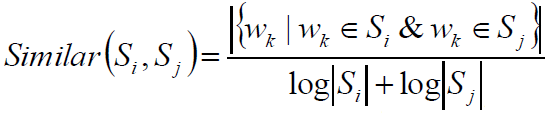
将PageRank中“网页”换成“句子”,结论仍然基本成立,只需考虑将“链接”加权:
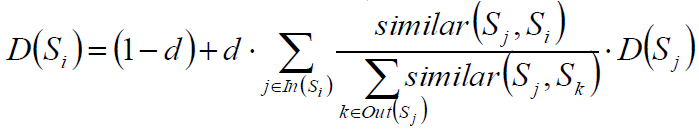
LDA总结
1)由于在词和文档之间加入的主题的概念,可以较好的解决一词多义和多词一义的问题。
2)在实践中发现,LDA用于短文档往往效果不明显——这是可以解释的:因为一个词被分配给某个主题的次数和一个主题包括的词数目尚未敛。往往需要通过其他方案“连接”成长文档。
3)LDA可以和其他算法相结合。首先使用LDA将长度为Ni的文档降维到K维(主题的数目),同时给出每个主题的概率(主题分布),从而可以使用if-idf继续分析或者直接作为文档的特征进入聚类或者标签传播算法——用于社区发现等问题。
机器学习-LDA主题模型笔记的更多相关文章
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 机器学习入门-贝叶斯构造LDA主题模型,构造word2vec 1.gensim.corpora.Dictionary(构造映射字典) 2.dictionary.doc2vec(做映射) 3.gensim.model.ldamodel.LdaModel(构建主题模型)4lda.print_topics(打印主题).
1.dictionary = gensim.corpora.Dictionary(clean_content) 对输入的列表做一个数字映射字典, 2. corpus = [dictionary,do ...
- 理解 LDA 主题模型
前言 gamma函数 0 整体把握LDA 1 gamma函数 beta分布 1 beta分布 2 Beta-Binomial 共轭 3 共轭先验分布 4 从beta分布推广到Dirichlet 分布 ...
- 通俗理解LDA主题模型
通俗理解LDA主题模型 0 前言 印象中,最開始听说"LDA"这个名词,是缘于rickjin在2013年3月写的一个LDA科普系列,叫LDA数学八卦,我当时一直想看来着,记得还打印 ...
- R语言︱LDA主题模型——最优主题数选取(topicmodels)+LDAvis可视化(lda+LDAvis)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:在自己学LDA主题模型时候,发现该模 ...
- 自然语言处理之LDA主题模型
1.LDA概述 在机器学习领域,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和 隐含狄利克雷分布(Latent Dirichlet Alloca ...
- LDA主题模型(理解篇)
何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章.一段话.一个句子所表达的中心思想.不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章.一段话.一个句子是从 ...
- Gensim LDA主题模型实验
本文利用gensim进行LDA主题模型实验,第一部分是基于前文的wiki语料,第二部分是基于Sogou新闻语料. 1. 基于wiki语料的LDA实验 上一文得到了wiki纯文本已分词语料 wiki.z ...
- [综] Latent Dirichlet Allocation(LDA)主题模型算法
多项分布 http://szjc.math168.com/book/ebookdetail.aspx?cateid=1&§ionid=983 二项分布和多项分布 http:// ...
随机推荐
- PostgreSQL远程连接,发生致命错误:没有用于主机“…”,用户“…”,数据库“…”,SSL关闭的pg_hba.conf记录
PostgreSQL远程连接方法 有时候在远程连接时,会报Error connecting to the server:致命错误:没有用于主机“…”,用户“…”,数据库“…”,SSL关闭的pg_hba ...
- iframe的src指向的内容不刷新
想任何一种办法让iframe的src的值有变化就可以了 $("#h5Content").attr("src","${h5.url}"+&qu ...
- Java Hessian实践
Hessian是基于HTTP的轻量级远程服务解决方案,Hessian向RMI一样,使用二进制进行客户端和服务端的交互.但是与其它二进制远程调用技术(例如RMI)不同的是,它的二进制消息可以移植到其它非 ...
- PCA python 实现
PCA 实现: 参考博客:https://blog.csdn.net/u013719780/article/details/78352262 from __future__ import print_ ...
- JS构造函数中有return
function foo(name) { this.name = name; return name } console.log(new foo('光何')) function bar(name) { ...
- button按钮的状态为disabled禁用状态,click事件无法触发,但是为什么touchstart下却依然可以触发
切换到移动模拟模式,并点击按钮,查看控制台. 发现click没有事件没有触发,而touch事件依然触发. 解决办法: 对于移动端我们使用css来禁止按钮,达到disable的效果: 对,就是这个神奇的 ...
- Mybatis Hibernate MiniDao 共存
Mybatis MiniDao共存问题 - 国内版 Binghttps://cn.bing.com/search?q=Mybatis+MiniDao%E5%85%B1%E5%AD%98%E9%97%A ...
- Jupyter Notebook in a virtual environment (virtualenv)
$ python -m venv projectname $ source projectname/bin/activate (venv) $ pip install ipykernel (venv) ...
- wpf程序,只允许运行一个程序实例问题
https://bbs.csdn.net/topics/390486402 https://codereview.stackexchange.com/questions/20871/single-in ...
- LeetCode_401. Binary Watch
401. Binary Watch Easy A binary watch has 4 LEDs on the top which represent the hours (0-11), and th ...