HDFS 分布式文件系统
博客出处W3c:https://www.w3cschool.cn/hadoop/xvmi1hd6.html
简介
Hadoop Distributed File System,分布式文件系统
架构
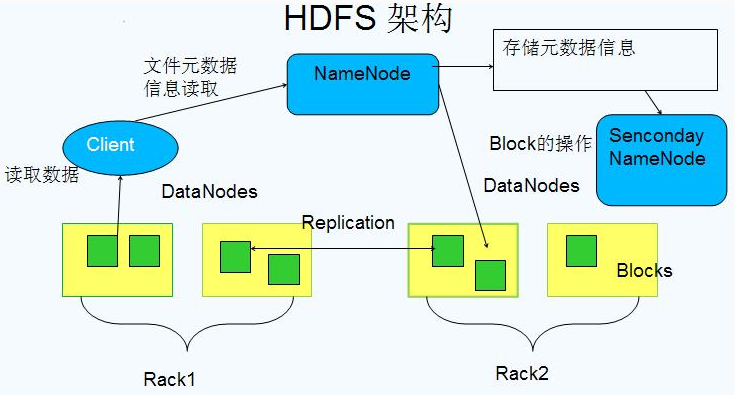
Block数据&##x5757;
基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)
一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
基本的读写S#x5355;位,类似于磁盘的页,每次都是读写一个块
- 每个块都会被复制到多台机器,默认复制3份
NameNode
存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
- NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
Secondary NameNode
- 定时与NameNode进行同步(定期合并文件系统镜像和编辑日&#x#x5FD7;,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机
DataNode
保存具体的block数据
负责数据的读写操作和复制操作
DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性
HDFS 分布式文件系统的更多相关文章
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- hdfs(分布式文件系统)优缺点
hdfs(分布式文件系统) 优点 支持超大文件 支持超大文件.超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件.一般来说hadoop的文件系统会存储TB级别或者PB级别的数据.所以在企业的应 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
随机推荐
- STS(Spring Tool Suite)中.yml文件的语法颜色设置
点击Window --> 最下面点击 YEdit Preferences --> 点击 color Preferences 弹出以下对话框进行修改颜色
- 机器学习之线性回归以及Logistic回归
1.线性回归 回归的目的是预测数值型数据的目标值.目标值的计算是通过一个线性方程得到的,这个方程称为回归方程,各未知量(特征)前的系数为回归系数,求这些系数的过程就是回归. 对于普通线性回归使用的损失 ...
- ORB-SLAM2 地图加载2
补充SystemSetting和InitKeyFrame两个类的代码.实际上,由于是通过SystemSetting来读取的相机内参以及ORB特征参数,所以就可以将Tracking.cc中关于读取内参的 ...
- 全面理解UE4委托
UE4中的delegate(委托)常用于解耦不同对象之间的关联:委托的触发者不与监听者有直接关联,两者通过委托对象间接地建立联系 监听者通过将响应函数绑定到委托上,使得委托触发时立即收到通知,并进行相 ...
- 物联网架构成长之路(39)-Bladex开发框架环境搭建
0.前言 上一篇博客已经介绍了,阶段性小结.目前第一版的物联网平台已经趋于完成.框架基本不变了,剩下就是调整一些UI,还有配合硬件和市场那边,看看怎么推广这个平台.能不能挣点外快.第一版系统虽然简陋, ...
- picture元素的使用
前言 相信前端小伙伴们对img元素已经烂熟于心,但不知是否了解picture元素呢? 简单来说,picture元素通过包含一个或多个<source>元素和一个<img>元素再结 ...
- rpc和webservice的关系简述
RPC(Remote Procedure Call,远程过程调用)是一个很大的概念.它是一种通过网络从远程计算机程序上跨语言跨平台的请求服务.RPC能省略部分接口代码的开发,可以跨机器之间访问对象(J ...
- 图片服务器FastDFS的安装及使用
FastDFS介绍 FastDFS是用c语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并注重高可用.高性能等指标,使用FastDFS ...
- yii2.0的学习之旅(一)
一. 通过composer安装yii2.0项目 *本文是根据您已经安装了composer (1)跳转到项目根目录 cd /xxxx/www (2)下载插件 composer global requir ...
- WPF树形菜单--递归与非递归遍历生成树结构的集合
一.新建了WPF项目作为测试,使用TreeView控件进行界面展示. 第一步创建实体类TreeEntity: public class TreeEntity { private int _mid; p ...