jmeter_分布式测试
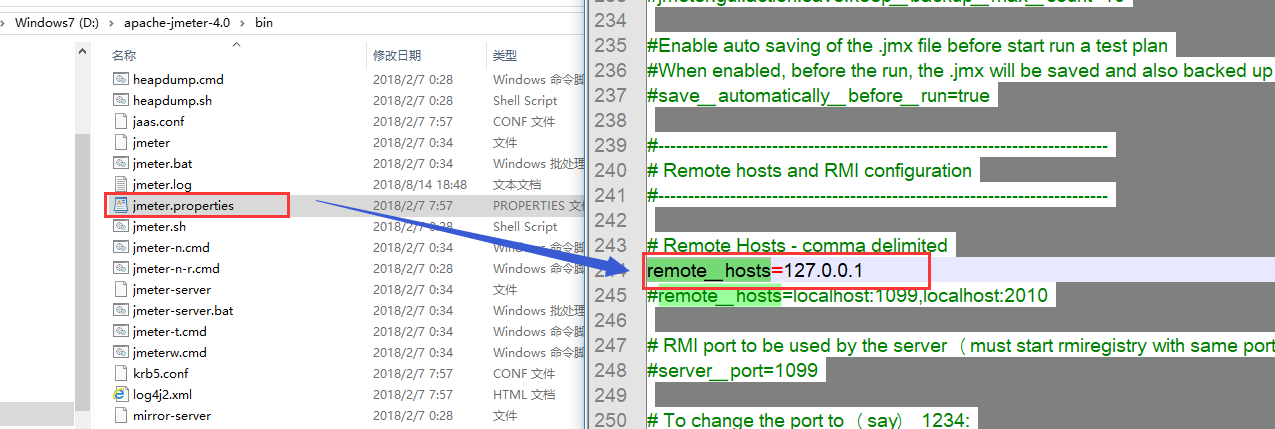
3、启动 controller 机器上的jmeter.bat , 选择菜单Run中 "Remote Start" 中的 192.168.0.11:10099, 192.168.0.12:10099

4、如果要让某个电脑执行,可以点击该电脑的IP地址就可以, 如果两个都要执行,可以点击Run菜单下的"远程运行全部" 菜单
jmeter_分布式测试的更多相关文章
- 关于Jmeter分布式测试在公司内的使用
首先非常感谢虫师的文章受益匪浅 http://www.cnblogs.com/fnng/category/345478.html 今天,花了半天时间进行分布式的测试,真是纠结啊!! RT 1.在公司用 ...
- JMeter学习-022-JMeter 分布式测试(性能测试大并发、远程启动解决方案)
在使用 JMeter 进行性能测试时,难免遇到要求并发请求数比较的场景,此时单台测试机的配置(CPU.内存.带宽等)可能无法支持此性能测试场景.因而,此时 JMeter 提供的分布式测试功能就有了用武 ...
- 【Fine原创】JMeter分布式测试中踩过的那些坑
最近因为项目需要,研究了性能测试的相关内容,并且最终选用了jmeter这一轻量级开源工具.因为一直使用jmeter的GUI模式进行脚本设计,到测试执行阶段工具本身对资源的过量消耗给性能测试带来了瓶颈, ...
- jenkin系列_调度jmeter实现分布式测试
假设现在有 192.168.1.100(jmeter 控制器 C ).192.168.1.101(jmeter负载机 B)两台机器进行分布式测试,各个步骤如下 1. C 和B 安装jmeter,并运行 ...
- selenium之多线程启动grid分布式测试框架封装(四)
九.工具类,启动所有远程服务的浏览器 在utils包中创建java类:LaunchAllRemoteBrowsers package com.lingfeng.utils; import java.n ...
- selenium之多线程启动grid分布式测试框架封装(一)
一.设计思路 在国内市场上,IE内核的浏览器占据了绝大部分的市场份额,那么此次框架封装将进行IE系列的浏览器进行多线程并发执行分布式测试的封装. 运行时主进程与多线程关系如下:
- jmeter命令行运行-分布式测试
上一篇文章我们说到了jmeter命令行运行但是是单节点下的, jmeter底层用java开发,耗内存.cpu,如果项目要求大并发去压测服务端的话,jmeter单节点难以完成大并发的请求,这时就需要对j ...
- 转:Jmeter以non-gui模式进行分布式测试
由于Jmeter是一个纯JAVA的应用,用GUI模式运行压力测试时,对客户端的资源消耗是相当惊人的,所以在进行正式的压测时一定要使用non-gui模式运行,如果并发数很高或者客户端的硬件资源比较一般的 ...
- selenium结合docker构建分布式测试环境
selenium是目前web和app自动化测试的主要框架.对于web自动化测试而言,由于selenium2.0以后socker服务器由本地浏览器自己启动且直接通过浏览器原生API操作页面,故越来越多的 ...
随机推荐
- js constructor typeOf 区别
constructor 属性返回对创建此对象的数组函数的引用. 例如:const obj = {a: 1} console.log(obj.constructor) // funct ...
- hive集成kerberos
1.票据的生成 kdc服务器操作,生成用于hive身份验证的principal 1.1.创建principal # kadmin.local -q “addprinc -randkey hive/yj ...
- Win10系统下安装ubuntu16.04双系统-常见问题解答
Win10系统下安装ubuntu16.04双系统-常见问题解答 1. 安装ubuntu16.04.2系统 磁盘分区形式有两种:GPT和MBR,关系到设置引导项.在win10下压缩出500GB空间给ub ...
- 微信小程序之如何定义页面标题
效果图: 这个标题是在哪里定义的呢?type.js核心代码如下(通常这段代码放在onLoad函数体内): wx.setNavigationBarTitle({ title: "支出类型列表& ...
- java web开发及Servlet常用的代码
日志 1.使用门面模式的slfj,并结合log4j,logback. 2.info.debug.error,要写清楚. 3.使用占位符,如下: log.info("用户id为: {} &qu ...
- #C++初学记录(STL容器以及迭代器)
STL初步 提交ACM会TLE /仅以学习STL与迭代器使用 C. Cards Sorting time limit per test1 second memory limit per test256 ...
- shell中$(( ))、$( )、``与${ }的区别
转 :shell $(( )).$( ).``与${ }的区别 $( )与` `(反引号)命令替换 在bash中,$( )与` `(反引号)都是用来作命令替换的.命令替换与变量替换差不多,都是用来重组 ...
- 将lol人物模型导入到Unity3d
接下来我打算将提取出来的lol人物模型导入到Unity3D中,这样会更加好玩!(不知道如何提取lol人物模型的话请看该链接) 首先我们已经把dae文件导入到c4d中了,可以看到这是一只吹笛子的 ...
- 【转】谈谈servlet、spring、struts
今年我一直在思考web开发里的前后端分离的问题,到了现在也颇有点心得了,随着这个问题的深入,再加以现在公司很多web项目的控制层的技术框架由struts2迁移到springMVC,我突然有了一个新的疑 ...
- TICK/TIGK运维栈安装运行 docker【中】
InfluxDB docker search influxdb docker pull influxdb docker run -d -p 8086:8086 -v /var/lib/influxdb ...