关于大数据T+1执行流程
关于大数据T+1执行流程
前提: 搭建好大数据环境(hadoop hive hbase sqoop zookeeper oozie hue)
1.将所有数据库的数据汇总到hive (这里有三种数据源 ORACLE MYSQL SEQSERVER)
全量数据抽取示例:
ORACLE(注意表名必须大写!!!)
sqoop import --connect jdbc:oracle:thin:@//10.11.22.33:1521/LPDR.china.com.hh --username root --password 1234 \
--table DATABASENAME.TABLENAME --hive-overwrite --hive-import --hive-database bgda_hw --hive-table lp_tablename \
--target-dir /user/hadouser_hw/tmp/lp_tablename --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
MYSQL:
sqoop import --connect jdbc:mysql://10.33.44.55:3306/DATABASEBANE --username ROOT --password 1234 \
--query 'select * from DEMO t where t.DATE1 < current_date and $CONDITIONS' \
--hive-overwrite --hive-import --hive-database bgda_hw --hive-table DEMO \
--target-dir /user/hadouser_hw/tmp/DEMO --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
SQLSERVER:
sqoop import --connect 'jdbc:sqlserver://10.55.66.15:1433;username=ROOT;password=ROOT;database=db_DD' \
--query 'select * from TABLE t where t.tasktime < convert(varchar(10),getdate(),120) and $CONDITIONS' \
--hive-overwrite --hive-import --hive-database bgda_hw --hive-table TABLENAME \
--target-dir /user/hadouser_hw/tmp/TABLENAME --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
2. 编写hive脚本,对数据进行处理
说明:
data 存储T+1跑出来的数据信息,只存一天的数据量
data_bak : 存储所有的数据信息
(初始化脚本)
use bgda_hw;
set hive.auto.convert.join=false; drop table data_bak;
create table data_bak(
scanopt string
,scanoptname string
,statisdate string
) row format delimited fields terminated by '\001'; insert overwrite table data_bak
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid = a.scanopt
where 1=1
and datediff(a.scandate,'2019-01-01' )>=0
and datediff(a.scandate,'2019-09-20' )<0
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
;
(t+1脚本)
use bgda_hw;
set hive.auto.convert.join=false; drop table data;
create table data(
scanopt string
,scanoptname string
,statisdate string
) row format delimited fields terminated by '\001'; insert overwrite table data
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid = a.scanopt
where 1=1
and a.scandate<date_add(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),0)
and a.scandate>=date_add(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),-1)
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
; insert into table data_bak
select * from data
;
3.将结果数据抽取到结果库里
sqoop export \
--connect jdbc:mysql://10.6.11.11:3306/report \
--username root \
--password 1234 \
--table data \
--export-dir /user/hive/warehouse/bgda_hw.db/data \
--columns scanopt,scanoptname,statisdate \
--fields-terminated-by '\001' \
--lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N'
抽數腳本示例 (腳本中的insert.hql 則是上方定義的hive腳本信息)
#!/bin/bash export CDH_PARCEL=/var/opt/cloudera/parcels/CDH/bin/
export PATH=${PATH}:${CDH_PARCEL}
export PYTHON_EGG_CACHE=~/.python-eggs #kinit to user hadouser_hw
kinit -kt hadouser_hw.keytab hadouser@HADOOP-AD-ROOT.DC echo "$CDH_PARCEL: {CDH_PARCEL} "
echo "$PATH: {PATH} "
echo "$PYTHON_EGG_CACHE: {PYTHON_EGG_CACHE} " #sqoop import full data from mssql database to hdfs
set -x beeline -u "jdbc:hive2://10.20.33.44:10000/default;principal=hive/sssssss012@HADOOP-AD-ROOT.DC" -f insert.hql # 将数据抽取到mysql 结果数据 原数据
sqoop export \
--connect jdbc:mysql://10.6.11.15:3306/report \
--username root \
--password 1234 \
--table rs_kpitime_psdata \
--export-dir /user/hive/warehouse/bgda_hw_stg.db/rs_kpitime_psdata_bak \
--columns aplcustno,isapprv,statisdate,statisyear,statisquarter,statismonth,countdate \
--fields-terminated-by '\001' \
--lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N' ret=$?
set +x if [[ $ret -eq 0 ]];then
echo "insert table OK"
else
echo "insert table failed!!!Please check!!!"
exit $ret
fi
4.定义调度信息(oozie),每天定时跑出结果数据,自动抽取到结果库中
HUE的基本使用
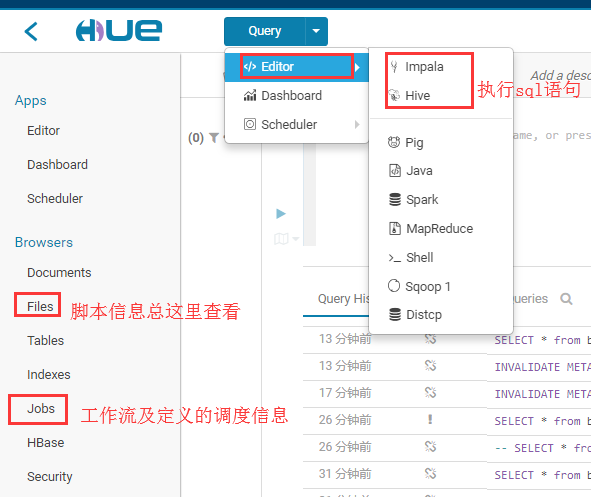
定义工作流信息
先进入workflow
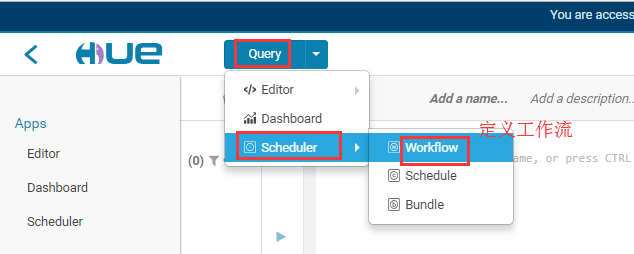
开始定义

选定要执行的脚本 (图片中提到的keytab 是一个认证文件)

定义定时任务
先进入定时任务页面
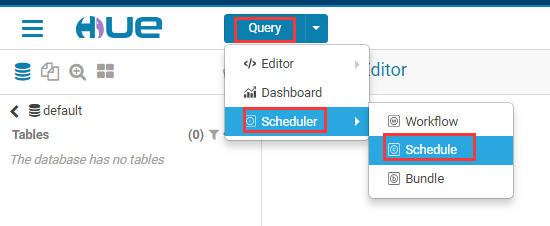
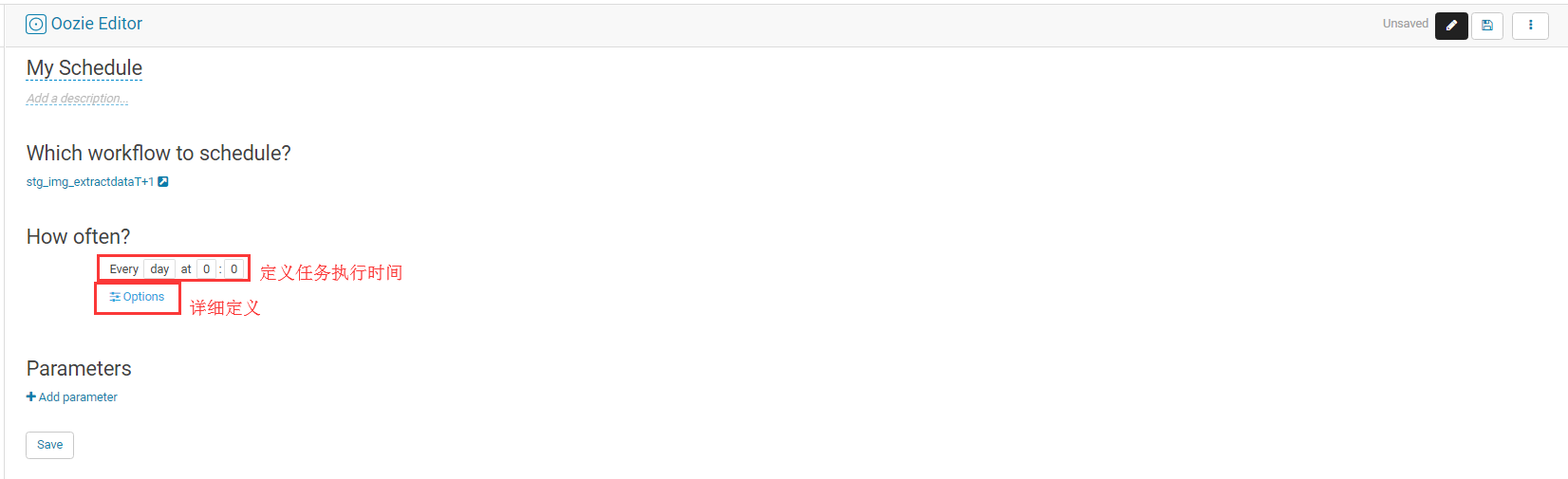
新建定时任务
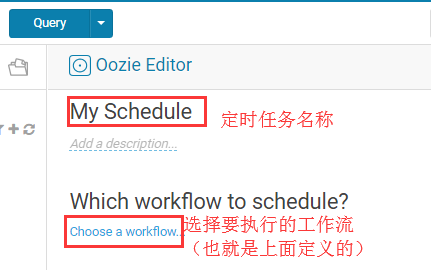
定时任务详细定义(点击Options ,选择ShangHai时区,然后定义任务执行时长(例如 从2019年到2099年,最后保存,保存好后记得点击执行!!!))
5.配置可视化组件展示数据 saiku
这部分详细教程请参考 https://www.cnblogs.com/DFX339/tag/saiku/
关于大数据T+1执行流程的更多相关文章
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 一个简单的使用Quartz和Oozie调度作业给大数据计算平台执行
一,介绍 Oozie是一个基于Hadoop的工作流调度器,它可以通过Oozie Client 以编程的形式提交不同类型的作业,如MapReduce作业和Spark作业给底层的计算平台(如 Cloude ...
- 迎战大数据-Oracle篇
来自:http://www.cnblogs.com/wenllsz/archive/2012/11/16/2774205.html 了解大数据带来的机遇: 透视架构与工具: 开源节流,获得竞争优势. ...
- BigData:值得了解的十大数据发展趋势
当今,世界无时无刻不在发生着变化.对于技术领域而言,普遍存在的一个巨大变化就是为大数据(Big data)打开了大门,并应用大数据技相关技术来改善各行业的业务并促进经济的发展.目前,大数据的作用已经上 ...
- AI时代,还不了解大数据?
如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能.大数据和云计算. 这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
- 什么是SQL Server2019大数据群集?
从SQL Server 2019(15.x)开始,SQL Server大数据群集允许您部署在Kubernetes上运行的SQL Server,Spark和HDFS容器的可伸缩群集.这些组件并排运行,使 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
随机推荐
- vue-cli开发项目,调用html5+接口,hbuilder真机运行,打包
开发中使用vue-cli正常开发 将配置文件中的路径改为相对路径--否则在打包之后真机运行时无法找到指定路径 开发完或者开发途中想要查看调用h5+的api效果就需要打包了 npm run build ...
- 2.成产出现 max(vachar2)取值问题
uat 测试结果正确max(9)>max(8),结果生产出现 max(9)>max(12) 原因:字符类型,默认比较第一个字符的ASCII码. 解决方式: max(to_number(va ...
- pcntl_signal(): Error assigning signal
错误原因:SIGSTOP(19)和SIGKILL(6)两个信号不能使用,进程间通信换成其他信号量就好了.
- 在MSSQL中的简单数据类型递归
在某些特定的项目需求中,我们需要实现树状数据结构, 由此,我们需要用递归将数据查询出来. WITH T AS ( SELECT ID,PID FROM TableName WHERE ID=1 UNI ...
- CodeForces - 556C Case of Matryoshkas (水题)
Andrewid the Android is a galaxy-famous detective. He is now investigating the case of vandalism at ...
- JSON在线解析及格式化校验工具 jsonin.com
JSON在线解析及格式化校验工具 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.它是基 ...
- UWP 打开系统设置面板
由于UWP各种权限管理的比较严格,所以在执行某一个特殊的操作之前,最好先申请一下相应的权限,以便告知用户你使用了这个权限,而且可以有效的避免App崩溃. 比如你想让用户手动打开麦克风权限,那么可以执行 ...
- [ASP.NET Core 3框架揭秘] 文件系统[4]:程序集内嵌文件系统
一个物理文件可以直接作为资源内嵌到编译生成的程序集中.借助于EmbeddedFileProvider,我们可以采用统一的编程方式来读取内嵌的资源文件,该类型定义在 "Microsoft.Ex ...
- 现代前端库开发指南系列(二):使用 webpack 构建一个库
前言 在前文中,我说过本系列文章的受众是在现代前端体系下能够熟练编写业务代码的同学,因此本文在介绍 webpack 配置时,仅提及构建一个库所特有的配置,其余配置请参考 webpack 官方文档. 输 ...
- SAP S4HANA TR传输之操作
SAP S4HANA TR传输之操作 事务代码: STMS_IMPORT, 选中请求,点击漏斗按钮, 输入要传输的TR(可以多个),然后回车, 鼠标单击请求号,按F9, 然后传输, 点击按钮'是',系 ...