1、Spark 2.1 源码编译支持CDH
一、准备工作
1、安装Java, 配置环境变量, 版本为JDK1.7或者以上
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH2、安装Maven, 版本为3.3.9或者以上
export MAVEN_HOME=/usr/local/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH二、编译Spark的源码包
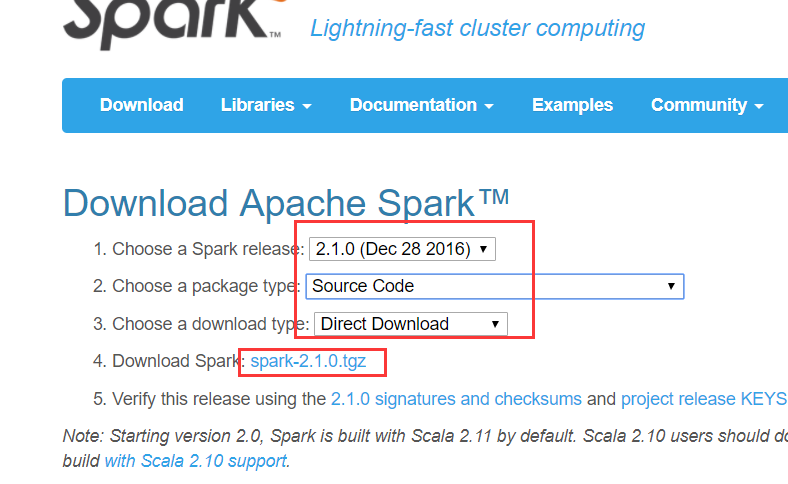
1、下载spark 2.1.0的源码包
2、增加cdh的repository
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>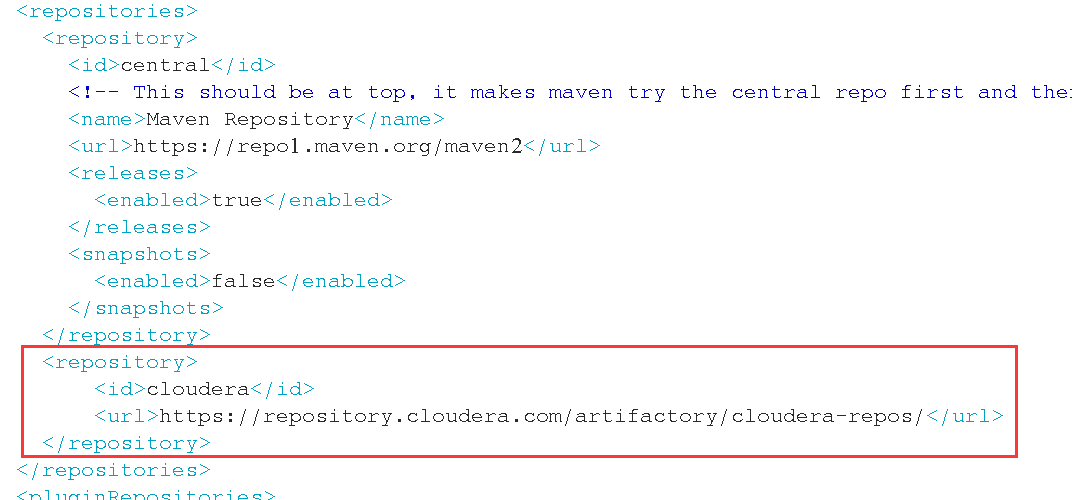
3、开始编译
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0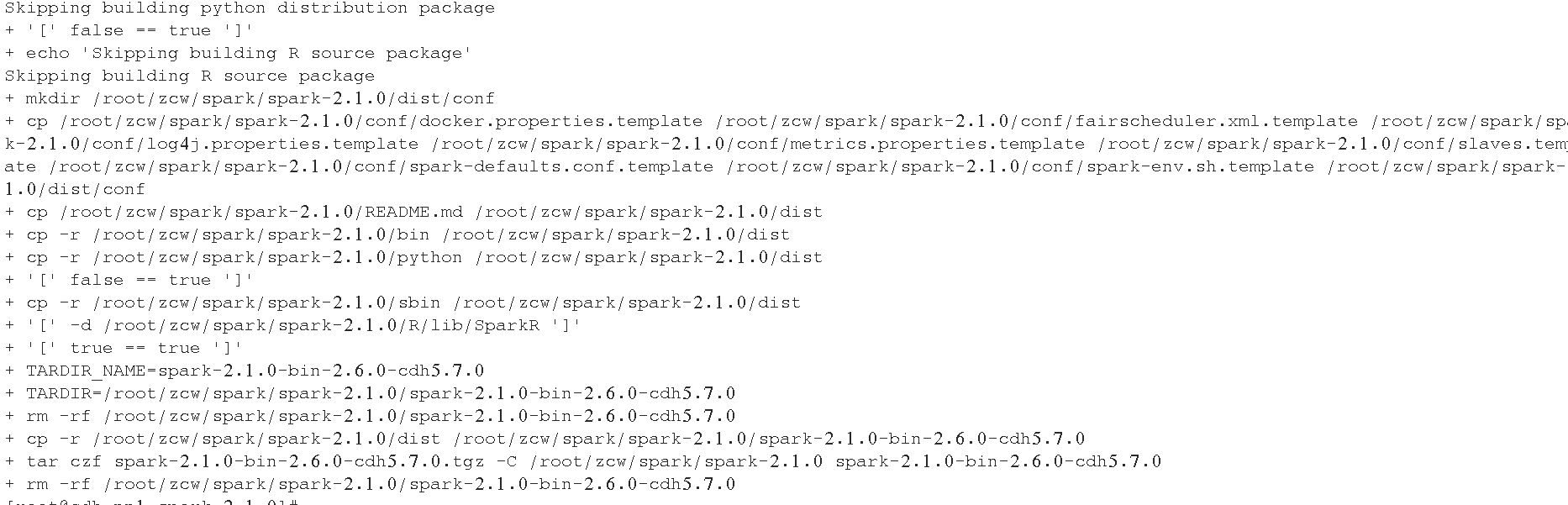
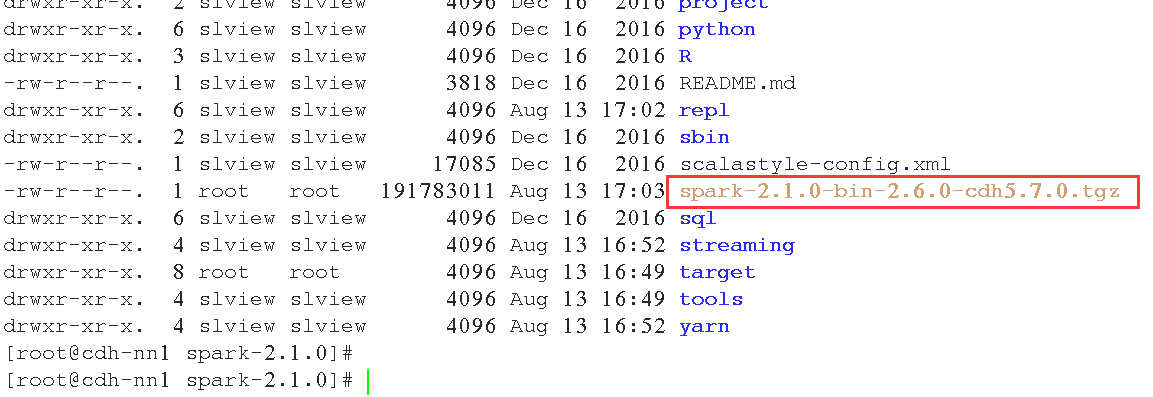
三、测试
1、提交到yarn上面

# export HADOOP_CONF_DIR=/etc/hadoop/conf
val file=spark.sparkContext.textFile("/tmp/appveyor.yml")
val wc = file.flatMap(line => line.split(",")).map(word=>(word,1)).reduceByKey(_ + _)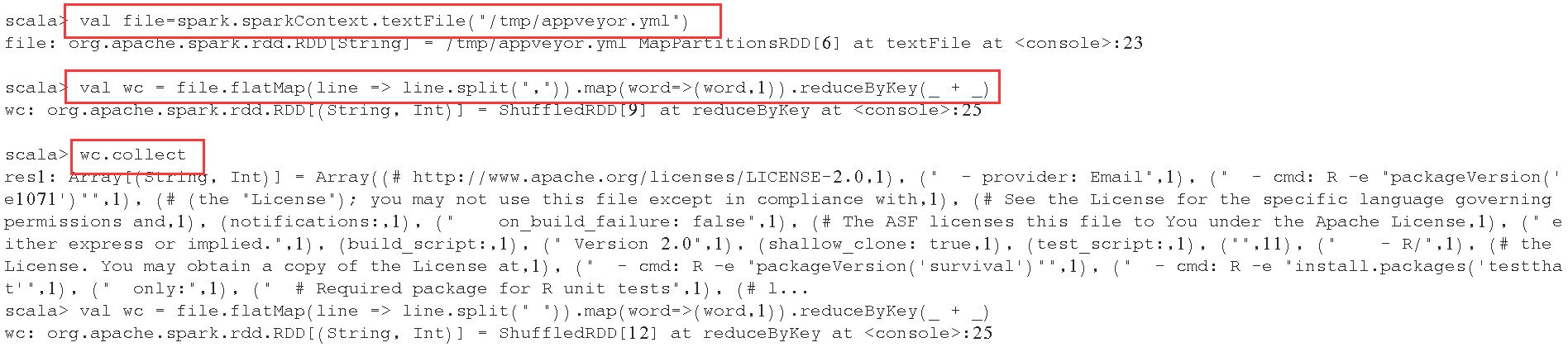
2、访问hive的表

1、Spark 2.1 源码编译支持CDH的更多相关文章
- dhcp源码编译支持4G上网卡
1. tar xvzf dhcp-4.2.5-P1.tar.gz 2. ./configure --host=arm-linux ac_cv_file__dev_random=yes 3. vi bi ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- Spark 2.1.1 源码编译
Spark 2.1.1 源码编译 标签(空格分隔): Spark Spark 源码编译 环境准备与起因 由于线上Spark On Yarn Spark Streaming程序在消费kafka 写入HD ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Spark源码编译
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3822995.html spark源码编译步骤如下: cd /home/hdpusr/workspace ...
- spark源码编译记录
spark在项目中已经用了一段时间了,趁现在空闲,下个源码编译在IDEA里面阅读下,特此记录过程. 前提已经安装maven和git 1.上官网下载源码的包: 2.然后解压到一个文件夹 3.编译,编译的 ...
- centos7.6环境zabbix3.2源码编译安装版升级到zabbix4.0长期支持版
zabbix3.2源码编译安装版升级到zabbix4.0长期支持版 项目需求: .2版本不再支持,想升级成4.0的长期支持版 环境介绍: zabbix服务端是编译安装的,数据库和web在一台机器上 整 ...
随机推荐
- 【MySql】linux下,设置mysql表名忽略大小写
[障碍再现] 状况描述01: 在LINUX下调一个程序经常报出找不到表,但是我明明是建了表的, 测试的时候,遇到一些问题,从Windows平台访问虚拟机中的Web应用,经常报出找不到表 ...
- 实战jmeter入门压测接口性能
什么是Jmeter? 是Apache组织开发的基于Java的压力测试工具. 准备工作: 一.安装配置好环境及压测工具 Jmeter下载地址:http://mirrors.tuna.tsinghua.e ...
- MySQL数据库之单表查询中关键字的执行顺序
目录 MySQL数据库之单表查询中关键字的执行顺序 1 语法顺序 2 执行顺序 3 关键字使用语法 MySQL数据库之单表查询中关键字的执行顺序 1 语法顺序 select distinct from ...
- CodeForces 1058E
题意略. 思路:本题有两个关键点: 一.满足题设的区间条件 1.区间内1的个数和为偶数 2.区间内含1个数最多的那一项,它所含1的个数不得超过区间内1的个数和的一半. 二.长度超过60的区间必然满足上 ...
- Java多线程之线程的生命周期
Java多线程之线程的生命周期 一.前言 当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态.在线程的生命周期中,它要经过新建(New).就绪(Runnable).运行(R ...
- Spring框架之事务管理
Spring框架之事务管理 一.事务的作用 将若干的数据库操作作为一个整体控制,一起成功或一起失败. 原子性:指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生. 一致性:指事务前后 ...
- SPSS数据分析方法不知道如何选择
一提到数学,高等数学,线性代数,概率论与数理统计,数值分析,空间解析几何这些数学课程,头疼呀.作为文科生,遇见这些课程时,通常都是各种寻求帮助,班上有位宅男数学很厉害,各种被女生‘围观’,这数学为 ...
- 【故障公告】阿里云 RDS 数据库服务器 CPU 100% 造成全站故障
非常非常抱歉,今晚 19:34 ~ 21:16 园子所使用的阿里云 RDS 数据库服务器突然出现 CPU 100% 问题,造成全站无法正常访问,由此您带来了很大的麻烦,请您谅解. 故障经过是这样的.1 ...
- 在Azure云上实现postgres主备切换
以下是工作上实现postgres主备切换功能所用到的代码和步骤,中间走了不少弯路,在此记录下.所用到的操作系统为centos 7.5,安装了两台服务器,hostname为VM7的为Master,VM8 ...
- 2018宁夏邀请赛I题 bubble sort(思维题
https://vjudge.net/problem/Gym-102222I 居然补到个防ak,刚开始不知道啥是循环左移右移(只能移一次),不好想.. 题意:以冒泡排序为背景 给你n,k 问在1~n的 ...