基于SincNet的原始波形说话人识别
speaker recognition from raw waveform with SincNet
Mirco Ravanelli, Yoshua Bengio
作为一种可行的替代i-vector的说话人识别方法,深度学习正日益受到欢迎。利用卷积神经网络(CNNs)直接对原始语音样本进行处理,取得了良好的效果。而不是使用标准的手工制作的功能,后一种CNNs从波形中学习低电平的语音表示,潜在地允许网络更好地捕获重要的窄带扬声器特性,如音高和共振峰。合理设计神经网络是实现这一目标的关键。
本文提出了一种新的CNN架构,称为SincNet,它鼓励第一个卷积层发现更有意义的过滤器。SincNet是基于参数化的sinc函数,实现带通滤波器。与标准CNNs不同的是,该方法学习每个滤波器的所有元素,只直接从数据中学习低截止频率和高截止频率。这提供了一种非常紧凑和有效的方法来派生专门针对所需应用程序进行调优的自定义筛选器组。
我们在说话人识别和验证任务上进行的实验表明,该结构比标准的CNN在原始波形上收敛更快,性能更好。
介绍
说话人识别是一个非常活跃的研究领域,在生物认证、取证、安全、语音识别、说话人二值化等各个领域都有显著的应用,这使得人们对这门学科[1]产生了浓厚的兴趣。目前最先进的解决方案都是基于语音段[2]的i-vector表示,这对之前的高斯混合模型-通用背景模型(GMMUBMs)[3]有显著的改进。深度学习已经在许多语音任务中显示出显著的成功[4 8],包括最近在说话人识别方面的研究[9,10]。深度神经网络(DNNs)已在i-vector框架内用于计算Baum-Welch统计[11],或用于帧级特征提取[12]。DNNs也被提议用于直接区别主格说话人的分类,最近关于这一主题的文献[13 16]就证明了这一点。然而,过去的大多数尝试使用手工制作的特性,如FBANK和MFCC系数[13,17,18]。这些经过设计的特性最初是根据感知的证据设计的,并且不能保证这些表示对于所有与语音相关的任务都是最优的。例如,标准特征使语音频谱平滑,这可能会妨碍提取关键的窄带扬声器特征,如音高和共振峰。为了缓解这一缺陷,最近的一些工作提出直接用光谱图箱[19 21]或甚至用原始波形[22 34]来馈电网络。CNNs是处理原始语音样本的最流行的架构,因为权重共享、local filters和pooling有助于发现健壮和不变的表示。
我们认为当前基于波形的CNNs最关键的部分之一是第一卷积层。这一层不仅处理高维输入,而且更容易受到消失的梯度问题的影响,特别是在使用非常深的架构时。美国有线电视新闻网(CNN)学习的滤波器通常采用嘈杂且不协调的多频带形状,特别是在可用的训练样本很少的情况下。这些滤波器对神经网络当然有一定的意义,但对人类的直觉没有吸引力,似乎也不能有效地表示语音信号。
为了帮助CNNs在输入层中发现更有意义的滤波器,本文提出在滤波器形状上增加一些约束。与标准CNNs相比,SincNet将波形与实现带通滤波器的一组参数化sinc函数进行卷积,而标准CNNs的滤波器组特征依赖于几个参数(滤波器向量的每个元素都是直接学习的)。低截止频率和高截止频率是滤波器从数据中得到的唯一参数。这个解决方案仍然提供了相当大的灵活性,但是迫使网络将重点放在对最终滤波器的形状和带宽有广泛影响的高级可调参数上。
我们的实验是在具有挑战性和现实性的条件下进行的。和简短的测试句(持续2- 6秒)。在各种数据集上取得的结果表明,本文提出的SincNet算法比更标准的CNN算法收敛速度更快,具有更好的末端任务性能。在考虑的实验设置下,我们的体系结构也优于一个更传统的基于i-vector的说话人识别系统。
论文的其余部分组织如下。SincNet体系结构在第2节中进行了描述。第3节讨论了与先前工作的关系。实验设置和结果分别在第4节和第5节中概述。最后,第6节讨论了我们的结论。
2 SincNet结构
标准CNN的第一层在输入波形和一些有限脉冲响应(FIR)滤波器[35]之间执行一组时域卷积。每个卷积定义如下(大多数深度学习工具包实际上计算的是相关性而不是卷积。得到的翻转(镜像)过滤器不会影响结果)
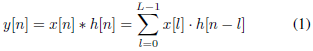
其中x[n]是语音信号的块,h[n]是长度l的滤波器,y[n]是滤波输出。在标准cnns中,每个滤波器的所有l元素(taps)都是从数据中学习的。相反,所提出的sincnet(如图1所示)使用预定义的函数g执行卷积,该函数g仅依赖于几个可学习的参数g,如下式中所示:

受数字信号处理中标准滤波的启发,一个合理的选择是定义一个由矩形带通滤波器组成的滤波器组g。在频域中,一般带通滤波器的幅值可以写成两个低通滤波器的差值
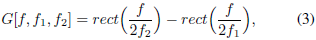
其中f1和f2是学习的低和高截止频率,rect(·)是幅度频率域中的矩形函数(rect(·)函数的相位被认为是线性的)。在返回到时域(使用逆傅里叶变换[35])之后,参考函数g变为:
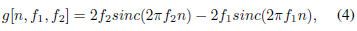
其中sinc函数定义为sinc(x) = sinx =x。
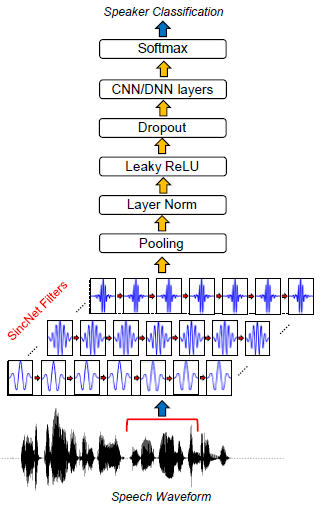
图1 SincNet的结构框图
关于说话人的身份被定位。为了确保$f1\geq 0$和$f2\geq f1$,前面的方程实际上由以下参数提供
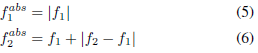
请注意,我们并没有强制f2小于奈奎斯特频率,因为我们观察到这个约束在训练期间自然地得到了满足。此外,每个滤波器的增益不是在这个层次上学习的。此参数由后续层管理,它们可以轻松地为每个过滤器输出赋予或多或少的重要性。
一个理想的带通滤波器。,当通带完全平坦且阻带衰减无限大时,需要无限个元素l。g的任何截断都不可避免地导致理想滤波器的近似,其特征是通带波纹,阻带衰减有限。缓解这个问题的一个流行的解决方案是[35]窗口。窗口化是通过将截断的函数g与窗口函数w相乘来实现的,其目的是消除g末端的突变不连续
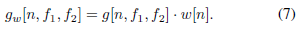
本文采用流行的汉明窗口[36],定义如下:
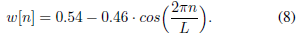
汉明窗特别适合实现高频率选择性[36]。但是,这里没有报告的结果显示,在采用其他功能(如Hann、Blackman和Kaiser windows)时,没有显著的性能差异。还请注意,滤波器g是对称的,因此不会引入任何相位畸变。由于对称性,可以通过考虑滤波器的一边并继承另一半的结果来有效地计算滤波器。
SincNet中涉及的所有操作都是完全可微的,滤波器的截止频率可以通过随机梯度下降(SGD)或其他基于梯度的优化例程与其他CNN参数联合优化。如图1所示,第一次基于sincs的卷积后,可以使用标准的CNN管道(池化、归一化、激活、退出)。多个标准的convolutional、fully-connected或layers[3740]可以叠加在一起,最后使用softmax分类器对speaker进行分类。
2.1 模型属性
提出的SincNet具有一些显著的性质
快速收敛:SincNet迫使网络只关注对性能有重大影响的滤波器参数。所提出的方法实际上实现了一种自然的归纳偏差,它利用了有关滤波器形状的知识(类似于这项任务中通常使用的特征提取方法),同时保留了适应数据的灵活性。这种先验知识使得学习滤波器特性变得更加容易,帮助SincNet更快地收敛到一个更好的解决方案。
参数少:sincnet极大地减少了第一卷积层的参数个数,例如,如果我们考虑一个由长度为l的f滤波器组成的层,标准cnn使用f·l参数,而sincnet考虑的是2f。如果f=80和l=100,我们对cnn使用8k参数,而对sincnet使用160参数。此外,如果我们将滤波器长度l加倍,标准cnn将其参数计数加倍(例如,我们从8k变为16k),而sincnet的参数计数不变(每个滤波器只使用两个参数,而不管其长度l如何)。这就提供了一种可能性,可以在不实际添加
参数少:SincNet大大减少了第一个卷积层的参数数量。例如,如果我们考虑一个长度为L的F过滤器组成的层,一个标准的CNN使用F·L参数,而SincNet考虑的是2F。如果F = 80, L = 100,我们对CNN使用8k参数,而对SincNet仅使用160。此外,如果我们滤波器长度的两倍,一个标准的CNN双打其参数计算(例如,从8 k到16 k),尽管SincNet不变参数计数(只有两个参数是用于每个过滤器,不管它的长度L)。这提供了可能性获得非常挑剔和许多水龙头过滤器,不添加参数优化问题。此外,SincNet体系结构的紧凑性使其适合于少数样本的情况。
可解释性:与其他方法相比,在第一个卷积层中获得的SincNet feature map具有更好的解释性和可读性。事实上,滤波器组只依赖于具有明确物理意义的参数。
3 相关工作
最近有几项研究探索了使用CNNs来处理音频和语音的低水平语音表示。之前的大多数尝试都利用了星等谱图特征[1921,41 43]。虽然光谱图比标准手工制作的特征保留了更多的信息,但它们的设计仍然需要仔细调整一些关键的超参数,比如帧窗口的持续时间、重叠和类型学,以及频率箱的数量。因此,最近的趋势是直接学习原始波形,从而完全避免任何特征提取步骤。该方法在语音[22,26]中显示了良好的前景,包括情绪任务[27]、说话人识别[32]、欺骗检测[31]和语音合成[28,29]。与SincNet类似,之前的一些工作也提出了对CNN过滤器添加约束,例如强制它们在特定波段上工作[41,42]。与提出的方法不同的是,后者的工作是根据谱图特征进行操作,同时仍然学习CNN滤波器的所有L元素。在[43]中,使用了一组参数化高斯滤波器,探索了与所提方法相关的思想。该方法对谱图域进行处理,而SincNet直接考虑原始时域波形。
据我们所知,这项研究是第一次显示了使用卷积神经网络对原始波形进行时域音频处理的sinc滤波器的有效性。过去的研究主要针对语音识别,而我们的研究主要针对语音识别的应用。SincNet学习的紧凑过滤器特别适合于说话人识别任务,特别是在每个说话人的训练数据只有几秒钟和用于测试的短句的现实场景中。
4 实验设置
建议的SincNet已经在不同的语料库上进行了评估,并与许多说话人识别基线进行了比较。本着可重复研究的精神,我们利用Librispeech等公共数据进行了大部分实验,并在GitHub上发布了SincNet的代码。在下面的部分中,将提供实验设置的概述。
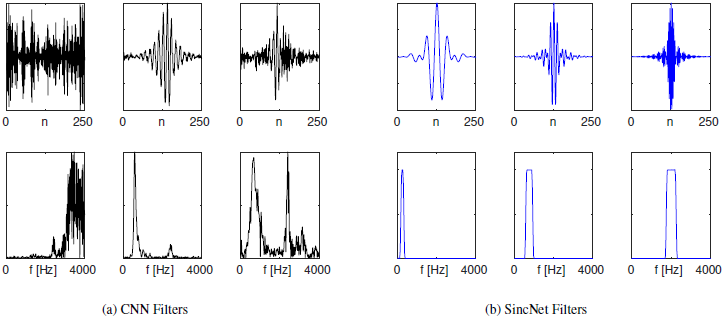
图2:使用标准CNN和建议的SincNet(使用Librispeech语料库)学习过滤器的示例。第一行显示了滤波器的时域,第二行显示它们的幅频响应。
4.1 语料库
为了对不同数量的说话者数据集提供实验证据,本文考虑了TIMIT (462 spks, train chunk)[44]和Librispeech (2484 spks)[45]语料库。去掉每个句子开头和结尾的非语音间隔。内部沉默超过125毫秒的Librispeech语句被分成多个块。为了解决文本无关的说话人识别,TIMIT的校准语句(即,所有说话者的文本相同)已被删除。对于后一个数据集,每个说话者使用5个句子进行训练,其余3个句子用于测试。在Librispeech语料库中,培训和测试材料被随机选择,每个演讲者使用12-15秒的训练数据,测试2-6秒的句子。
4.2 SincNet 设置
每个语音句子的波形被分割成200 ms的块(有10 ms的重叠),并输入到Sinc- Net体系结构中。第一层使用长度为L=251个样本的80个过滤器,执行第2节中描述的基于sincs的卷积。该架构随后使用了两个标准的卷积层,都使用60个长度为5的过滤器。层归一化[46]用于输入样本和所有卷积层(包括SincNet输入层)。接下来,我们使用三个由2048个神经元组成的全连接层,并使用批量归一化[47]进行归一化。所有的隐层使用漏- relu[48]非线性。使用mel-scale截止频率初始化sincs层的参数,而使用众所周知的Glorot初始化方案[49]初始化网络的其余部分。通过使用softmax分类器获得帧级扬声器分类,提供了一组目标扬声器的后验概率。一个句子级别的分类是简单地通过平均帧预测和投票给说话者而得到的,这样可以最大化平均后验。
训练使用RMSprop优化器,学习率lr=0:001,a=0:95,e=10-7,小批量128。架构的所有超参数都是在timit上调整的,然后也被librispeech继承。
扬声器验证系统是由扬声器识别神经网络考虑两种可能的设置。首先,我们考虑d-vector framework[13, 21],它依赖于最后一个隐含层的输出,计算测试和声明的speaker dvectors之间的余弦距离。作为另一种解决方案(下称DNN-class),说话人验证系统可以直接取与声明身份对应的softmax后验分数。这两种方法将在第5节中进行比较。
从冒名顶替者中随机选出10个话语,每个句子都来自一个真正的演讲者。请注意,为了评估我们在标准的开放集扬声器id任务中的方法,所有的冒名顶替者都来自一个与用于培训扬声器id DNN不同的扬声器池。
4.3 基线设置
我们比较了SincNet与几个备选系统。首先,我们考虑由原始波形提供的标准CNN。这个网络基于与SincNet相同的架构,但是用一个标准的来代替基于SincNet的卷积。
还与流行的手工制作功能进行了比较。To end, 我们 计算 39 MFCCs (13 static++) 40 FBANKs 使用 Kaldi 工具包 [50].这些特征每25毫秒计算一次,有10毫秒的重叠,收集起来形成一个约200毫秒的上下文窗口(即,与考虑的基于波形的神经网络的上下文相似)。FBANK使用CNN, MFCCs4使用多层感知器(MLP)。FBANK网络采用层归一化,MFCC网络采用批量归一化。这些网络的超参数也使用上述方法进行了调整。
对于说话人验证实验,我们也考虑了i-vector基线。i-vector系统是用SIDEKIT工具包[51]实现的。在Librispeech数据(避免测试和登记语句)上训练GMM-UBM模型、总变率(TV)矩阵和概率线性判别分析(PLDA)。GMM-UBM由2048个高斯分量组成,TV和PLDA特征语音矩阵的秩为400。注册和测试阶段在Librispeech上进行,使用与DNN实验相同的语音片段集。
5 结果
本节报告所提出的SincNet的实验验证。首先,我们将使用SincNet学习的过滤器与使用标准CNN学习的过滤器进行比较。然后,我们将我们的体系结构与其他竞争系统在说话人识别和验证任务方面进行比较
5.1 滤波器的分析
检查学习过的过滤器是一种有价值的实践,可以洞察网络实际上正在学习什么。图2展示了使用Librispeech数据集(频率响应绘制在0到4khz之间)通过标准CNN(图2a)和建议的SincNet(图2b)学习滤波器的一些示例。从图中可以看出,标准的CNN并不总是学习具有明确频率响应的滤波器。在某些情况下,频响看起来有噪声(见图2a的第一个滤波器),而在另一些情况下,假设有多频带形状(见CNN图的第三个滤波器)。相反,SincNet是专门设计来实现矩形带通滤波器,导致更有意义的CNN滤波器。
除了定性的检查外,重要的是要强调哪些频带被所学习的滤波器覆盖。图3为SincNet和CNN学习的滤波器的累积频响。有趣的是,在SincNet图中有三个明显突出的主要峰值(参见图中的红线)。第一个对应于音高区域(男性的平均音高为133赫兹,女性为234赫兹)。第二个峰值(大约位于500hz)主要捕捉第一个共振峰,其在各种英语元音上的平均值确实是500hz。最后,第三个峰(从900到1400赫兹)捕捉到一些重要的第二共振峰,如元音/a/的第二共振峰,平均位于1100赫兹。此筛选器组配置表明,SincNet已经成功地调整了其特性来处理说话人标识。相反,标准的CNN没有表现出这样一种有意义的模式:CNN过滤器倾向于正确地聚焦在频谱的较低部分,但是调谐到第一和第二共振峰的峰值并没有清晰地出现。从图3可以看出,CNN曲线位于SincNet曲线之上。实际上,SincNet学习的过滤器,平均来说,比CNN的更有效,可能更好地捕捉窄带扬声器的线索。
5.2 说话人辨别
与标准CNN相比,SincNet的学习曲线如图4所示。在TIMIT数据集上得到的这些结果突出了使用SincNet时帧错误率(FER%)的更快降低。此外,SincNet收敛到更好的性能,导致一个33.0%的FER与一个37.7%的FER实现与CNN的基线。
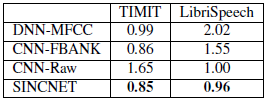
表1:在TIMIT (462 spks)和Librispeech (2484 spks)数据集上训练的说话人识别系统的分类错误率(CER%)。我们的产品比竞争对手的性能好。
表1报告了实现的分类错误率(CER%)。该表显示,SincNet在TIMIT和Librispeech数据集上都优于其他系统。在TIMIT上,原始波形与标准CNN的差距特别大,这证实了SincNet在训练数据较少的情况下的有效性。虽然LibriSpeech的使用减少了这一差距,我们仍然观察到4%的相对改善,也获得了更快的收敛(1200对1800年代)。标准FBANKs只在TIMIT上提供了与SincNet相当的结果,但在使用Librispech时比我们的架构差得多。在训练数据很少的情况下,网络不能比fbank更好地发现过滤器,但是在数据较多的情况下,可以学习和利用定制的过滤器库来提高性能。
5.3。说话人验证
作为最后一个实验,我们将验证扩展到说话人验证。表2报告了使用Librispeech语料库获得的相同错误率(EER%)。所有DNN模型都显示出良好的性能,导致所有病例的EER均低于1%。该表还强调了SincNet的表现优于其他模型,显示了相对于标准CNN模型约11%的性能改进。dnn类模型的性能明显优于d-vector。尽管后一种方法很有效,但是必须为每一个添加到[32]池中的新扬声器训练(或调整)一个新的DNN模型。这使得该方法的性能更好,但与d-vector相比灵活性更差。
为了完整起见,还对标准i-vector进行了实验。虽然与此技术的详细比较超出了本文的范围,但值得注意的是,我们最好的i-vector系统实现了EER=1.1%,远远低于DNN系统。众所周知,在文献中,当每个说话者使用更多的训练材料和使用更长的测试语句时,i-vector能够提供竞争性的表现[52 54]。在这项工作所面临的挑战条件下,神经网络可以实现更好的泛化。
6 结论和未来的工作
提出了一种直接处理波形音频的神经网络结构SincNet。我们的模型受到数字信号处理中滤波方式的启发,通过有效的参数化对滤波形状施加约束。SincNet已经广泛地评估了挑战性的说话人识别和验证任务,显示性能效益为所有考虑的语料库。
除了性能的提高,SincNet也大大提高了收敛速度超过一个标准的CNN,并由于利用滤波器的对称性计算效率更高。对SincNet滤波器的分析表明,所学习的滤波器组被调优,以精确地提取一些已知的重要扬声器特性,如音高和共振峰。在未来的工作中,我们将评估SincNet在其他流行的扬声器识别任务,如VoxCeleb。虽然本研究仅针对说话人识别,但我们认为所提出的方法定义了处理时间序列的一般范式,可以应用于许多其他领域。因此,我们未来的努力将致力于扩展到其他任务,如语音识别、情感识别、语音分离和音乐处理。
感谢
我们要感谢高塔姆·巴塔查里亚、凯尔·卡斯特纳、蒂图安·帕科利特、德米特里·谢尔约克、莫里齐奥·奥莫洛戈和雷纳托·德·莫里。这项研究在一定程度上得到了Calcul Qu ebec和Compute Canada的支持。
参考文献
[1] H. Beigi, Fundamentals of Speaker Recognition, Springer, 2011.
[2] N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, Front-end factor analysis for speaker verification, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788 798, 2011.
[3] D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, Speaker verification using adapted Gaussian mixture models, Digital Signal Processing, vol. 10, no. 1 3, pp. 19 41, 2000. [4] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning, MIT Press, 2016.
[5] D. Yu and L. Deng, Automatic Speech Recognition - A Deep Learning Approach, Springer, 2015.
[6] G. Dahl, D. Yu, L. Deng, and A. Acero, Contextdependent pre-trained deep neural networks for large vocabulary speech recognition, IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 30 42, 2012.
[7] M. Ravanelli, Deep learning for Distant Speech Recognition, PhD Thesis, Unitn, 2017.
[8] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, A network of deep neural networks for distant speech recognition, in Proc. of ICASSP, 2017, pp. 4880 4884.
[9] M. McLaren, Y. Lei, and L. Ferrer, Advances in deep neural network approaches to speaker recognition, in Proc. of ICASSP, 2015, pp. 4814 4818.
[10] F. Richardson, D. Reynolds, and N. Dehak, Deep neural network approaches to speaker and language recognition, IEEE Signal Processing Letters, vol. 22, no. 10, pp. 1671 1675, 2015.
[11] P. Kenny, V. Gupta, T. Stafylakis, P. Ouellet, and J. Alam, Deep neural networks for extracting baumwelch statistics for speaker recognition, in Proc. of Speaker Odyssey, 2014.
[12] S. Yaman, J. W. Pelecanos, and R. Sarikaya, Bottleneck features for speaker recognition, in Proc. of Speaker Odyssey, 2012, pp. 105 108.
[13] E. Variani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez-Dominguez, Deep neural networks for small footprint text-dependent speaker verification, in Proc. of ICASSP, 2014, pp. 4052 4056.
[14] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer, End-to-end text-dependent speaker verification, in Proc. of ICASSP, 2016, pp. 5115 5119.
[15] D. Snyder, P. Ghahremani, D. Povey, D. Romero, Y. Carmiel, and S. Khudanpur, Deep neural networkbased speaker embeddings for end-to-end speaker verification, in Proc. of SLT, 2016, pp. 165 170.
[16] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, X-vectors: Robust dnn embeddings for speaker recognition, in Proc. of ICASSP, 2018.
[17] F. Richardson, D. A. Reynolds, and N. Dehak, A unified deep neural network for speaker and language recognition, in Proc. of Interspeech, 2015, pp. 1146 1150.
[18] D. Snyder, D. Garcia-Romero, D. Povey, and S. Khudanpur, Deep neural network embeddings for textindependent speaker verification, in Proc. of Interspeech, 2017, pp. 999 1003.
[19] C. Zhang, K. Koishida, and J. Hansen, Textindependent speaker verification based on triplet convolutional neural network embeddings, IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 26, no. 9, pp. 1633 1644, 2018.
[20] G. Bhattacharya, J. Alam, and P. Kenny, Deep speaker embeddings for short-duration speaker verification, in Proc. of Interspeech, 2017, pp. 1517 1521.
[21] A. Nagrani, J. S. Chung, and A. Zisserman, Voxceleb: a large-scale speaker identification dataset, in Proc. of Interspech, 2017.
[22] D. Palaz, M. Magimai-Doss, and R. Collobert, Analysis of CNN-based speech recognition system using raw speech as input, in Proc. of Interspeech, 2015.
[23] T. N. Sainath, R. J. Weiss, A. W. Senior, K. W. Wilson, and O. Vinyals, Learning the speech front-end with raw waveform CLDNNs, in Proc. of Interspeech, 2015.
[24] Y. Hoshen, R.Weiss, and K.W.Wilson, Speech acoustic modeling from raw multichannel waveforms, in Proc. of ICASSP, 2015.
[25] T. N. Sainath, R. J. Weiss, K. W. Wilson, A. Narayanan, M. Bacchiani, and A. Senior, Speaker localization and microphone spacing invariant acoustic modeling from raw multichannel waveforms, in Proc. of ASRU, 2015.
[26] Z. T uske, P. Golik, R. Schl uter, and H. Ney, Acoustic modeling with deep neural networks using raw time signal for LVCSR, in Proc. of Interspeech, 2014.
[27] G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nicolaou, B. Schuller, and S. Zafeiriou, Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network, in Proc. of ICASSP, 2016, pp. 5200 5204.
[28] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, Wavenet: A generative model for raw audio, in Arxiv, 2016.
[29] S. Mehri, K. Kumar, I. Gulrajani, R. Kumar, S. Jain, J. Sotelo, A. C. Courville, and Y. Bengio, Samplernn: An unconditional end-to-end neural audio generation model, CoRR, vol. abs/1612.07837, 2016.
[30] P. Ghahremani, V. Manohar, D. Povey, and S. Khudanpur, Acoustic modelling from the signal domain using CNNs, in Proc. of Interspeech, 2016.
[31] H. Dinkel, N. Chen, Y. Qian, and K. Yu, End-toend spoofing detection with raw waveform CLDNNS, Proc. of ICASSP, pp. 4860 4864, 2017.
[32] H. Muckenhirn, M. Magimai-Doss, and S. Marcel, Towards directly modeling raw speech signal for speaker verification using CNNs, in Proc. of ICASSP, 2018.
[33] J.-W. Jung, H.-S. Heo, I.-H. Yang, H.-J. Shim, , and H.- J. Yu, A complete end-to-end speaker verification system using deep neural networks: From raw signals to verification result, in Proc. of ICASSP, 2018.
[34] J.-W. Jung, H.-S. Heo, I.-H. Yang, H.-J. Shim, and H.-J. Yu, Avoiding Speaker Overfitting in End-to- End DNNs using Raw Waveform for Text-Independent Speaker Verification, in Proc. of Interspeech, 2018.
[35] L. R. Rabiner and R. W. Schafer, Theory and Applications of Digital Speech Processing, Prentice Hall, NJ, 2011.
[36] S. K. Mitra, Digital Signal Processing, McGraw-Hill, 2005.
[37] J. Chung, C . G ulc ehre, K. Cho, and Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, in Proc. of NIPS, 2014.
[38] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, Improving speech recognition by revising gated recurrent units, in Proc. of Interspeech, 2017.
[39] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, Light gated recurrent units for speech recognition, IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 2, no. 2, pp. 92 102, April 2018.
[40] M. Ravanelli, D. Serdyuk, and Y. Bengio, Twin regularization for online speech recognition, in Proc. of Interspeech, 2018.
[41] T. N. Sainath, B. Kingsbury, A. R. Mohamed, and B. Ramabhadran, Learning filter banks within a deep neural network framework, in Proc. of ASRU, 2013, pp. 297 302.
[42] H. Yu, Z. H. Tan, Y. Zhang, Z. Ma, and J. Guo, DNN Filter Bank Cepstral Coefficients for Spoofing Detection, IEEE Access, vol. 5, pp. 4779 4787, 2017.
[43] H. Seki, K. Yamamoto, and S. Nakagawa, A deep neural network integrated with filterbank learning for speech recognition, in Proc. of ICASSP, 2017, pp. 5480 5484.
[44] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, DARPA TIMIT Acoustic Phonetic Continuous Speech Corpus CDROM, 1993.
[45] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, Librispeech: An ASR corpus based on public domain audio books, in Proc. of ICASSP, 2015, pp. 5206 5210.
[46] J. Ba, R. Kiros, and G. E. Hinton, Layer normalization, CoRR, vol. abs/1607.06450, 2016.
[47] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in Proc. of ICML, 2015, pp. 448 456.
[48] A. L. Maas, A. Y. Hannun, and A. Y. Ng, Rectifier nonlinearities improve neural network acoustic models, in Proc. of ICML, 2013.
[49] X. Glorot and Y. Bengio, Understanding the difficulty of training deep feedforward neural networks, in Proc. of AISTATS, 2010, pp. 249 256.
[50] D. Povey et al., The Kaldi Speech Recognition Toolkit, in Proc. of ASRU, 2011.
[51] A. Larcher, K. A. Lee, and S. Meignier, An extensible speaker identification sidekit in python, in Proc. of ICASSP, 2016, pp. 5095 5099.
[52] A. K. Sarkar, D Matrouf, P.M. Bousquet, and J.F. Bonastre, Study of the effect of i-vector modeling on short and mismatch utterance duration for speaker verification, in Proc. of Interspeech, 2012, pp. 2662 2665.
[53] R. Travadi, M. Van Segbroeck, and S. Narayanan, Modified-prior i-Vector Estimation for Language Identification of Short Duration Utterances, in Proc. of Interspeech, 2014, pp. 3037 3041.
[54] A. Kanagasundaram, R. Vogt, D. Dean, S. Sridharan, and M. Mason, i-vector based speaker recognition on short utterances, in Proc. of Interspeech, 2011, pp. 2341 2344.
项目地址:https://github.com/grausof/keras-sincnet
论文:https://arxiv.org/pdf/1808.00158v3.pdf
paperwithcode地址:https://paperswithcode.com/paper/speaker-recognition-from-raw-waveform-with#
基于SincNet的原始波形说话人识别的更多相关文章
- 基于DDS的任意波形发生器
实验原理 DDS的原理 DDS(Direct Digital Frequency Synthesizer)直接数字频率合成器,也可叫DDFS. DDS是从相位的概念直接合成所需波形的一种频率合成技术. ...
- 基于matlab的音频波形实时採集显示 v0.1
robj = audiorecorder(44100,16,1); %设置採样频率.採样位数.通道数 recordblocking(robj,1); %採集初步数据(1s长度) rdata = get ...
- 基于脑波眼电-语音-APP控制的多功能智能轮椅
前言:这个项目是在2016-2017完成的,做的很浅显,贴出来与大家分享,希望能有帮助. 摘要 本项目主要是针对脑电信号控制的智能轮椅的设计,脑电控制是智能医疗领域的重要研究方向,旨在帮助行动不便但智 ...
- CSS3学习笔记--transform基于原始数据(旋转木马实例)
参考链接:好吧,CSS3 3D transform变换,不过如此! transform-style:preserve-3d属性要在图片所在的容器(父元素)中定义,perspective定义在父子元素上 ...
- 基于mindwave脑电波进行疲劳检测算法的设计(3)
这一节我将讲解thinkgear.h 里面的函数和宏定义.这一些都可以在MindSet Development Tools\ThinkGear Communications Driver\docs\h ...
- Android下基于SDL的YUV渲染
实战篇 本文主要参考我之前整理的文章windows下使用SDL进行YUV渲染. 相对于之前写的位图渲染部分(http://www.cnblogs.com/tocy/p/android-sdl-bitm ...
- PyTorch-Kaldi 语音识别工具包
翻译: https://arxiv.org/pdf/1811.07453.pdf ABSTRACT 开源软件的可用性在语音识别和深度学习的普及中发挥了重要作用.例如,Kaldi 现在是用于开发最先进 ...
- Linux音频编程指南
Linux音频编程指南 虽然目前Linux的优势主要体现在网络服务方面,但事实上同样也有着非常丰富的媒体功能,本文就是以多媒体应用中最基本的声音为对象,介绍如何在Linux平台下开发实际的音频应用程序 ...
- 与音频相关的技术知识点总结(Linux方向的开发)
几个术语和概念: 1. 关于PCM的 PCM是Pulse code modulation的缩写,它是对波形最直接的编码方式.它在音频中的地位可能和BMP在图片中的地位有点类似吧. Samp ...
随机推荐
- java编译报错: 找不到或无法加载主类 Demo.class 的解决方法
原因:java 命令后面的文件不能有后缀名. 解决方法:运行java时候,后面的文件去掉后缀名.
- C#后台架构师成长之路-基础体系篇章大纲
如下基础知识点,如果不熟透,以后容易弄笑话..... 1. 常用数据类型:整型:int .浮点型:double.布尔型:bool.... 2. 变量命名规范.赋值基础语法.数据类型的转换.运算符和选择 ...
- 如何计算Data Guard环境中Redo所需的网络带宽传输 (Doc ID 736755.1)
How To Calculate The Required Network Bandwidth Transfer Of Redo In Data Guard Environments (Doc ID ...
- mysql数据库创建用户、赋权、修改用户密码
创建新用户 create user lisi identified by '123456'; 查看创建结果: 授权 命令格式:grant privilegesCode on dbName.tableN ...
- fiddler添加IP列
willow一个规则管理插件 Ctrl+F查找“static function Main()”字符串,然后添加以下代码: FiddlerObject.UI.lvSessions.AddBoundCol ...
- 电位器控制两个 LED 灯交替闪烁
电路图: 布局:
- Linux系统:常用Linux系统管理命令总结
本文源码:GitHub·点这里 || GitEE·点这里 一.目录指令 1.创建目录make directory mkdir 目录名称 //mkdir spring,创建一个spring文件夹 mkd ...
- 双链表算法原理【Java实现】(八)
前言 前面两节内容我们详细介绍了ArrayList,一是手写实现ArrayList数据结构,而是通过分析ArrayList源码看看内置实现,关于集合内容一如既往,本节课我们继续学习集合LinkedLi ...
- (四十三)c#Winform自定义控件-Listview-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- Selenium(十六):unittest单元测试框架(二) 初识unittest(续)
1. 认识unittest(续) 关于unittest单元测试框架,还有一些问题值得进一步探讨.你可能在前一章的学习过程中产生了一些疑问,也许你会在本节中找到答案. 1.1 用例执行的顺序 用例的执行 ...