Python爬虫-Scrapy-CrawlSpider与ItemLoader
一、CrawlSpider

根据官方文档可以了解到, 虽然对于特定的网页来说不一定是最好的选择, 但是 CrwalSpider 是爬取规整的网页时最常用的 spider, 而且有很好的可塑性.
除了继承自 Spider 的属性, 它还拓展了一些其他的属性. 对我来说, 最常用的就是 rules 了.
爬虫一般来说分为垂直爬取和水平爬取, 这里拿 猫眼电影TOP100 举例. 垂直爬取就是从目录进入到内容详情后爬取, 即从当前页进入某一影片的详情页面; 水平爬取就是从这一页目录翻到下一页目录后爬取, 即从当前页到排名第十一至二十的页面. 不论是哪一种爬取, 都离不开 url, 即你想要去到的页面的链接, 而 rules 就为我们提供了一套提取链接的规则, 以及得到链接后应该怎么做.
来看一下 rules 中 Rule 的定义, class scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None), 这里也只说我自己经常用到的.
1. link_extractor:
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(), tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True,
process_value=None, deny_extensions=None, restrict_css=(), strip=True)
提取链接的规则在这里定义, 并且提取出链接后会生成一个 scrapy.Request 对象. allow里是正则表达式, 过滤掉不符合要求的链接; restrict_xpath 和 restrict_css定义获取链接的区域.
2. callback:
回调函数, 请求得到相应后用什么方法处理, 和 Request 中的 callback 一样, 但是此处以字符串形式表示而不是方法引用.
3. follow:
请求得到响应后是否继续用本套rules规则来提取链接. 布尔值类型, 如果callback为None, 则默认为True, 否则为False.
这里的 rules 功能类似于 Spider类里的 parse() 方法, 请求 start_urls 中的链接, 并且返回新的 Request.
二、ItemLoader

Items 为抓取的数据提供了容器, 而 Item Loaders 提供填充容器的机制, 并且其API更加便捷好用.
之前用 Spider 类的时候, 一般都是直接使用 scrapy.item 的, 当网页高度规整的时候我们改用了 CrawlSpider 类. 当获取到高度规整的数据时, 我们想要进行处理, 这时候 Item Loader 就发挥其作用了.
定义: class scrapy.loader.ItemLoader(item=None, selector=None, response=None, parent=None, **context)
item: 自己定义的容器.
selector: Selector 对象, 提取填充数据的选择器.
response: Response 对象, 可以构造选择器的响应, 因为 scrapy 里的响应可以直接使用 xpath 或 css, 这里把它当成选择器也差不多.
ItemLoader 的使用:
from scrapy.loader import ItemLoader
from qoutes.items import QuoteItem
import time def parse_item(self, response):
quotes = response.css('.quote')
for quote in quotes:
loader = ItemLoader(item=QuoteItem(), selector=quote)
loader.add_css('author', '.author::text')
loader.add_css('tags', '.tag::text')
loader.add_xpath('text', './/*[@class="tag"]/text()')
loader.add_value('addtime', time.ctime())
yield loader.load_item()
相较于 Item 的字典类使用方法, ItemLoader 显得更简单明了, 这样的代码有着更好的可维护性以及自描述性.
这里有两个小问题特别说一下, 是我自己刚开始使用 ItemLoader 时犯的错.
第一个就是, 使用 ItemLoader 后不需要调用 extract() 了, item里的值类型为 list.
第二个就是, 当页面中有多个 item, 循环遍历时是使用 selector='你的选择器'. 如果使用 response='你的响应' 的话, 你会发现返回的 item 内容要么出错要么重复.
处理器: 结合数据以及对数据进行格式化和清洗的函数
例:
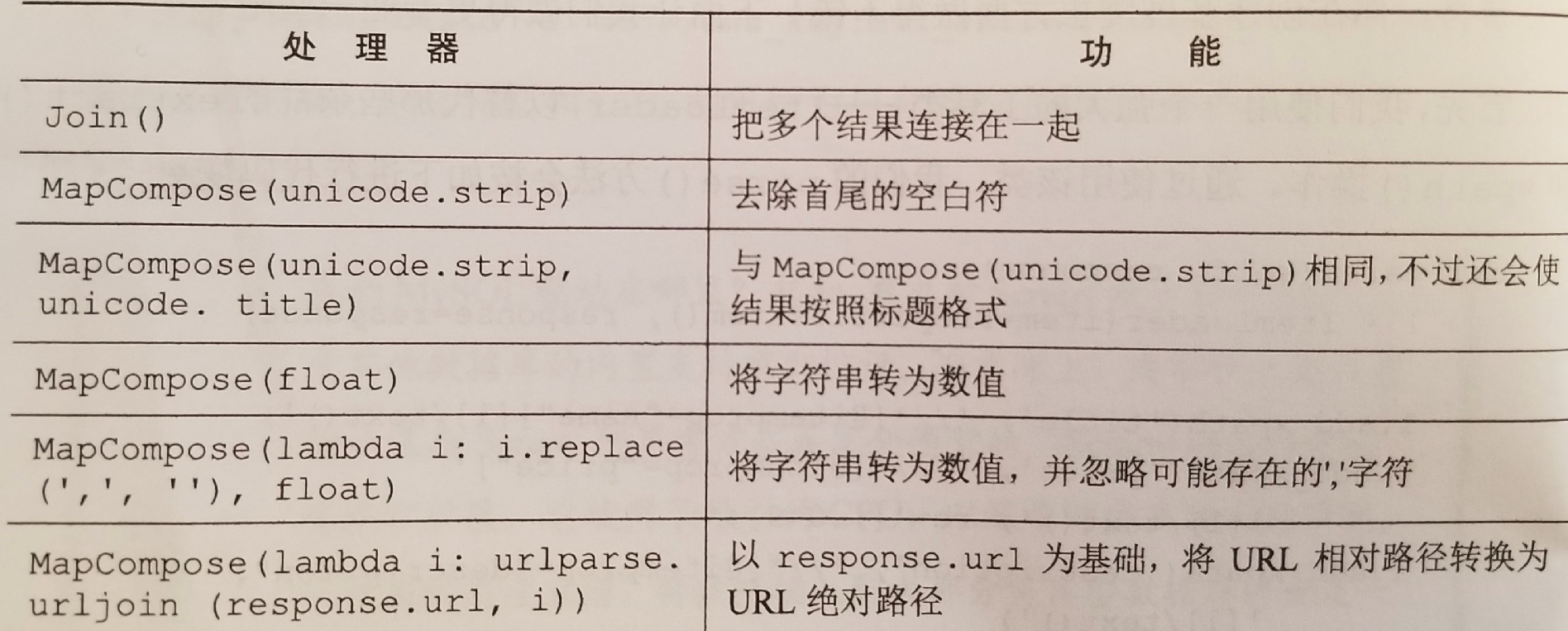
上图中的 "unicode" 应替换为 "str".
对我来说, 最常用就是 MapCompose 搭配匿名函数, 可以更加灵活的处理数据. MapCompose 和 Python 内置的 map 类似, 根据所给函数来遍历处理可迭代对象中的每个值.
使用方法也挺简单, 只需要在编写填充机制的时候加上处理器即可, 如: loader.add_css('tags', '.tag::text', MapCompose(str.title)).
定义 ItemLoader 的子类:
就我而言, 定义子类最大的意义就是可以对每个已获得的数据使用指定的处理器.
刚刚说过, ItemLoader 会对 xpath 或 css 提取出来的结果做出类似 extract() 的处理, 所以结果都会以列表的形式返回. 有时候列表里就一个以字符串形式表示的值, 我们希望直接得到字符串, 这时可以使用处理器 TakeFirst(), 返回列表第一个非空值, 类似于 extract_first(). 如果所有的结果要做这样的处理, 那在编写填充机制的时候依次添加处理器就显得过于麻烦了. 此时我们就可以定义一个 ItemLoader 的子类.
通过重写 default_input_processor 和 default_input_processor 便可以达到目的.
例:
class NewLoader(ItemLoader):
default_input_processor = TakeFirst()
default_output_processor = str.title()
需要注意的是处理器执行的顺序, 最先执行编写填充机制时加的处理器, 接着是 default_input_processor, 然后是defualt_output_processor.
所有的处理在使用之前都需要导入.
以上便是我目前对 Scrapy 中 CrawlSpider 与 ItemLoader 的了解.
Python爬虫-Scrapy-CrawlSpider与ItemLoader的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- 安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用.但是以前一直用的java和php,对python不熟悉,于是花一天时 ...
- Python 爬虫-Scrapy爬虫框架
2017-07-29 17:50:29 Scrapy是一个快速功能强大的网络爬虫框架. Scrapy不是一个函数功能库,而是一个爬虫框架.爬虫框架是实现爬虫功能的一个软件结构和功能组件集合.爬虫框架是 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
- python爬虫scrapy命令工具学习之篇三
命令行工具(Command line tools) 全局命令 startproject settings runspider shell fetch view version 项目命令 crawl c ...
随机推荐
- Differentiation 导数和变化率
何为导数 1 : 如何求一条直线上一点的切线? what did we learn in high school about what a tangent(切) line is ? :任意一点上的切线 ...
- hdu1875 畅通工程再续 暴力+基础最小生成树
#include<cstdio> #include<cmath> #include<algorithm> using namespace std; ; ; ; in ...
- 递推DP URAL 1031 Railway Tickets
题目传送门 /* 简单递推DP:读题烦!在区间内的都更新一遍,dp[]初始化INF 注意:s1与s2大小不一定,坑! 详细解释:http://blog.csdn.net/kk303/article/d ...
- php 缩略图
<!DOCTYPE html><!-- HTML5表单 --><form method="post" action="" enct ...
- AJPFX浅谈Java 性能优化之垃圾回收(GC)
★JVM 的内存空间 在 Java 虚拟机规范中,提及了如下几种类型的内存空间: ◇栈内存(Stack):每个线程私有的.◇堆内存(Heap):所有线程公用的.◇方法区(Method Area):有点 ...
- LOJ#121. 「离线可过」动态图连通性(线段树分治)
题意 板子题,题意很清楚吧.. Sol 很显然可以直接上LCT.. 但是这题允许离线,于是就有了一个非常巧妙的离线的做法,好像叫什么线段树分治?? 此题中每条边出现的位置都可以看做是一段区间. 我们用 ...
- 谈谈对Android中的消息机制的理解
Android中的消息机制主要由Handler.MessageQueue.Looper三个类组成,他们的主要作用是 Handler负责发送.处理Message MessageQueue负责维护Mess ...
- windows session logoff时进行处理动作
目标:Windows session logoff时得到通知,进行一些记录/清理工作 测试平台: win7 x64 logoff时系统会发送WM_ENDSESSION消息,如果某个应用对这个消息的处理 ...
- C# 获取本机IP(优化项目实际使用版)
好一段时间没来更新博客了,因为密码实在记不住,烦死了,密码干脆直接用那个找回密码链接的一部分. 吐槽完说正事了,关于C# 获取本机IP的,最开始用的是下面的,但是因为获取IP的有点多,而且难判断,忽 ...
- (转)Spring4.2.5+Hibernate4.3.11+Struts2.3.24整合开发
http://blog.csdn.net/yerenyuan_pku/article/details/52902851 前面我们已经学会了Spring4.2.5+Hibernate4.3.11+Str ...