Spark基本原理
仅作《Spark快速大数据分析》学习笔记
定义:Spark是一个用来实现 快速 而 通用 的集群计算平台;(通用的大数据处理引擎;)
改进了原Hadoop MapReduce处理模型,体现在三方面:
a. 速度;(内存计算)
b. 不仅支持批处理,还支持交互式查询(速度快的成果)、流式计算、机器学习、图计算等;(迭代算法)
c. 丰富的API和易用性;
Spark组件主要组成:
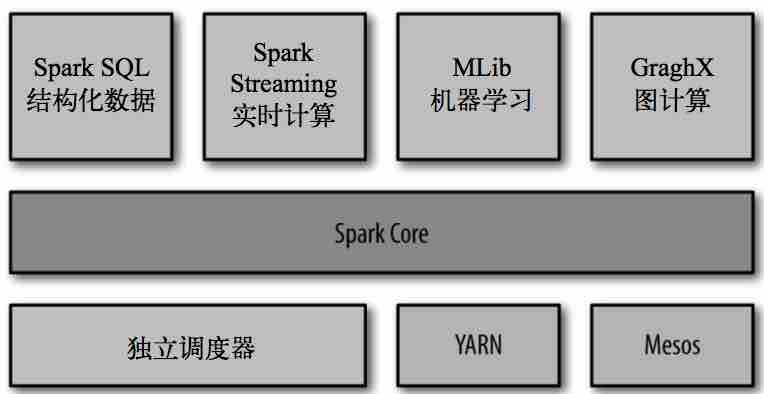
Spark Core:实现了Spark的核心功能,包含任务调度、内存管理、与存储系统交互、错误恢复等;定义了RDD API;
RDD:(resilient distributed dataset)弹性分布式数据集,表示分布在多个计算节点上可以平行操作的元素集合;
通过创建RDD来操作完成 统计计算,这些计算会自动地 在集群上并行进行。
Spark主要的编程抽象;
Spark SQL:Spark操作结构化数据的程序包;
Spark Streaming: Spark 提供的对实时数据进行流式计算的组件 ;
MLlib: 提供常见的机器学习(ML)功能的程序库 ;
GraphX: 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算;
Spark shell:和其他 shell 工具不一样的是,在其他 shell 工具中你只能使用单机的硬盘和内存来操作数据;
可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由 Spark 自动控制完成;
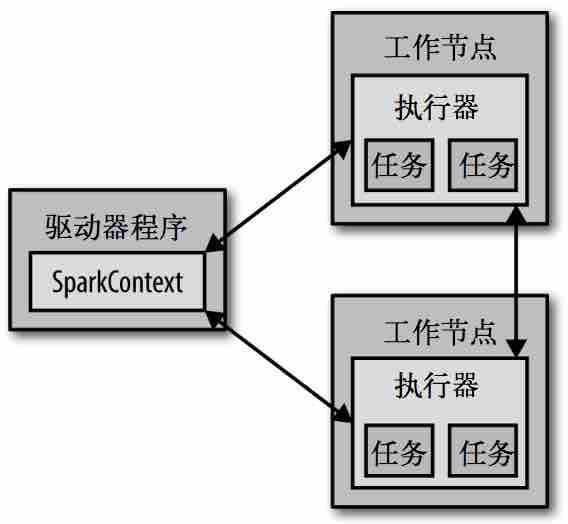
动作原理:
driver program
executor
每个 Spark 应用都由一个 驱动器程序(driver program) 来管理。
a. 驱动器程序包含应用的 main函数;
b. 并且定义了集群上的 分布式数据集;
c. 还对这些 分布式数据集应用了相关操作。
Shell环境下 驱动器程序就是 Spark shell 本身,可利用它输入想要运行的操作。
驱动器程序通过一个 SparkContext对象 来访问Spark,这个对象代表对计算集群的一个连接;slell启动时会自动创建一个SparkContext对象,变量名为sc;
//查看变量 sc
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
一旦有了SparkContext对象,就可以利用它创建RDD,如sc.textFile("/filename"),然后即可进行各种操作;
通常操作RDD的相关操作,驱动器程序一般要管理多个执行器(executor)节点;如count()操作,多个节点会统计文件不同的部分;
Spark基本原理的更多相关文章
- 重温spark基本原理
(一)spark特点: 1.高效,采用内存存储中间计算结果,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间. 2.易用,采用函数式编程风格,提供了超过80种不同的Trans ...
- spark第一篇--简介,应用场景和基本原理
摘要: spark的优势:(1)图计算,迭代计算(2)交互式查询计算 spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存 为了满足挖掘分析与交互式实时查询的 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
- Google云平台使用方法 | Hail | GWAS | 分布式回归 | LASSO
参考: Hail Hail - Tutorial windows也可以安装:Spark在Windows下的环境搭建 spark-2.2.0-bin-hadoop2.7 - Hail依赖的平台,并行处 ...
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- spark第二篇--基本原理
==是什么 == 目标Scope(解决什么问题) 在大规模的特定数据集上的迭代运算或重复查询检索 官方定义 aMapReduce-like cluster computing framework de ...
- Spark 准备篇-基本原理
本章内容: 待整理 参考文献: <深入理解SPARK:核心思想与源码分析>(第2章) Spark的作业提交及运行流程的异同
随机推荐
- Classloader中loadClass()方法和Class.forName()区别
Classloader中loadClass()方法和Class.forName()都能得到一个class对象,那这两者得到的class对象有什么区别呢 1.java类装载的过程 Java类装载有三个步 ...
- Wing IDE 6.0 算号器注册机代码
我开发Python时喜欢用Wing IDE, 然后最近发现Wing IDE升级到6.0版本了, 但是之前能在5.1上用的算号器代码不能用在6.0上了, 所以就上网搜搜是否有相关算号器, 果然, 找到了 ...
- CSS选择器与XPath语言
一 在爬取页面信息的过程中,需要到想要的信息进行定位,主要有两种方法.CSS选择器和XPath语言.查找某一个标签,两种方法都可以做到. 二 CSS选择器 http://www.w3school.co ...
- django 和 mongdb 写一个简陋的网址,以及用django内置的分页功能
https://github.com/factsbenchmarks/simple_websit_about_58 一 设置 数据库的设置 在settings文件中加入这样一段代码: from mon ...
- tyvj 1432 楼兰图腾
树状数组 本题数据有误 对于每一个点用权值树状数组维护在这个点之后之前的比他大和比他小的数 #include <iostream> #include <cstdio> #inc ...
- 在 Windows 下用 TDM-GCC(MinGW)开发 DLL 涉及到数据同步锁及 DLL 初始化终止化函数的问题
在 Windows 下用 TDM-GCC(MinGW)开发 DLL 如果要用到数据同步锁,理论上可以采用 Windows API 提供的临界区实现(需要用到的函数有 InitializeCritica ...
- POJ 3694 (tarjan缩点+LCA+并查集)
好久没写过这么长的代码了,题解东哥讲了那么多,并查集优化还是很厉害的,赶快做做前几天碰到的相似的题. #include <iostream> #include <algorithm& ...
- sugar与阿龙的互怼(第一季)
§ 第一季 回家风波 高考了,啦啦啦~ 快要高考了,显然sugar很伤心. 显然不是因为快要考试了sugar才伤心的. 那为什么??? 因为他们都回家了,但是sugar和他的小伙伴们都不回家!!! ...
- centos 安装php缓存 apc或zend-opcode
去官方下载apc:pecl.php.net 搜索apc,安装最新的. #wget http://pecl.php.net/get/APC# tar -xzvf APC-3.1.9.tgz#cd AP ...
- python type
基于2.7 版本 type 是内置函数,有两种用法 class type(object) With one argument, return the type of an object. The re ...