Spark笔记之使用UDAF(User Defined Aggregate Function)
一、UDAF简介
先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。
关于UDAF的一个误区
我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以:
select max(foo) from foobar group by bar;
表示根据bar字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以:
select max(foo) from foobar;
这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。
二、UDAF使用
2.1 继承UserDefinedAggregateFunction
使用UserDefinedAggregateFunction的套路:
1. 自定义类继承UserDefinedAggregateFunction,对每个阶段方法做实现
2. 在spark中注册UDAF,为其绑定一个名字
3. 然后就可以在sql语句中使用上面绑定的名字调用
下面写一个计算平均值的UDAF例子,首先定义一个类继承UserDefinedAggregateFunction:
package cc11001100.spark.sql.udaf import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._ object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction { // 聚合函数的输入数据结构
override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil) // 缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil) // 聚合函数返回值数据结构
override def dataType: DataType = DoubleType // 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true // 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
} // 给聚合函数传入一条新数据进行处理
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (input.isNullAt(0)) return
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
} // 合并聚合函数缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
} // 计算最终结果
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1) }
然后注册并使用它:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.SparkSession
object SparkSqlUDAFDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
spark.read.json("data/user").createOrReplaceTempView("v_user")
spark.udf.register("u_avg", AverageUserDefinedAggregateFunction)
// 将整张表看做是一个分组对求所有人的平均年龄
spark.sql("select count(1) as count, u_avg(age) as avg_age from v_user").show()
// 按照性别分组求平均年龄
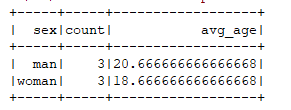
spark.sql("select sex, count(1) as count, u_avg(age) as avg_age from v_user group by sex").show()
}
}
使用到的数据集:
{"id": 1001, "name": "foo", "sex": "man", "age": 20}
{"id": 1002, "name": "bar", "sex": "man", "age": 24}
{"id": 1003, "name": "baz", "sex": "man", "age": 18}
{"id": 1004, "name": "foo1", "sex": "woman", "age": 17}
{"id": 1005, "name": "bar2", "sex": "woman", "age": 19}
{"id": 1006, "name": "baz3", "sex": "woman", "age": 20}
运行结果:

2.2 继承Aggregator
还有另一种方式就是继承Aggregator这个类,优点是可以带类型:
package cc11001100.spark.sql.udaf import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders} /**
* 计算平均值
*
*/
object AverageAggregator extends Aggregator[User, Average, Double] { // 初始化buffer
override def zero: Average = Average(0L, 0L) // 处理一条新的记录
override def reduce(b: Average, a: User): Average = {
b.sum += a.age
b.count += 1L
b
} // 合并聚合buffer
override def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
} // 减少中间数据传输
override def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count override def bufferEncoder: Encoder[Average] = Encoders.product // 最终输出结果的类型
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble } /**
* 计算平均值过程中使用的Buffer
*
* @param sum
* @param count
*/
case class Average(var sum: Long, var count: Long) {
} case class User(id: Long, name: String, sex: String, age: Long) {
}
调用:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.SparkSession
object AverageAggregatorDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
import spark.implicits._
val user = spark.read.json("data/user").as[User]
user.select(AverageAggregator.toColumn.name("avg")).show()
}
}
运行结果:
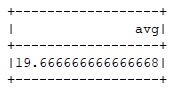
.
Spark笔记之使用UDAF(User Defined Aggregate Function)的更多相关文章
- 转:Spark User Defined Aggregate Function (UDAF) using Java
Sometimes the aggregate functions provided by Spark are not adequate, so Spark has a provision of ac ...
- Spark笔记之使用UDF(User Define Function)
一.UDF介绍 UDF(User Define Function),即用户自定义函数,Spark的官方文档中没有对UDF做过多介绍,猜想可能是认为比较简单吧. 几乎所有sql数据库的实现都为用户提供了 ...
- spark自定义函数之——UDAF使用详解及代码示例
UDAF简介 UDAF(User Defined Aggregate Function)即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组( ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 【理解】column must appear in the GROUP BY clause or be used in an aggregate function
column "ms.xxx_time" must appear in the GROUP BY clause or be used in an aggregate functio ...
- invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause
Column 'dbo.tbm_vie_View.ViewID' is invalid in the select list because it is not contained in either ...
- must appear in the GROUP BY clause or be used in an aggregate function
今天在分组统计的时候pgsql报错 must appear in the GROUP BY clause or be used in an aggregate function,在mysql里面是可以 ...
随机推荐
- js中文汉字按拼音排序
JavaScript 提供本地化文字排序,比如对中文按照拼音排序,不需要程序显示比较字符串拼音. String.prototype.localeCompare 在不考虑多音字的前提下,基本可以完美实现 ...
- Ubuntu环境如何上传项目到GitHub网站?
http://blog.csdn.net/ajianyingxiaoqinghan/article/details/70544159
- 【Alpha】第五次Scrum meeting
今日重大事件一览: 姓名 今日完成任务 所耗时间 刘乾 今日没有完成那个Issue..TuT第一次这么努力工作的我没有完成任务...真的是任务太坑啦. 任务完成了 60% Issue链接:https: ...
- 团队作业(五)——旅游行业的手机App
首先是作业要求: 在PM 带领下, 每个团队深入分析下面行业的App, 找到行业的Top 5 (从下面的三个备选中,任选一个行业即可) 英语学习/词典App 笔记App 旅游行业的手机App 我们选择 ...
- Installing OpenSSH from the Settings UI on Windows Server 2019 or Windows 10 1809
Installing OpenSSH from the Settings UI on Windows Server 2019 or Windows 10 1809 OpenSSH client and ...
- 在delphi中我用DBGrid选择多条记录,如何一次把选择的多条记录删掉
procedure TForm1.btnDoSumClick(Sender: TObject);var i: Integer;begin if DBGrid1.SelectedRows.Count ...
- Jenkins之自动构建
修改job的配置: Build periodically:不管版本是否修改,都会执行: Poll SCM:只有当版本有修改才会执行.
- spring注入 属性注入 构造器注入 set方法注入
spring注入 属性注入 构造器注入 set方法注入(外部bean注入)
- BZOJ 3876 支线剧情 | 有下界费用流
BZOJ 3876 支线剧情 | 有下界费用流 题意 这题题面搞得我看了半天没看懂--是这样的,原题中的"剧情"指的是边,"剧情点"指的才是点. 题面翻译过来大 ...
- POJ 1797 Heavy Transportation / SCU 1819 Heavy Transportation (图论,最短路径)
POJ 1797 Heavy Transportation / SCU 1819 Heavy Transportation (图论,最短路径) Description Background Hugo ...