CDH集群spark-shell执行过程分析
目的
刚入门spark,安装的是CDH的版本,版本号spark-core_2.11-2.4.0-cdh6.2.1,部署了cdh客户端(非集群节点),本文主要以spark-shell为例子,对在cdh客户端上提交spark作业原理进行简单分析,加深理解
spark-shell执行
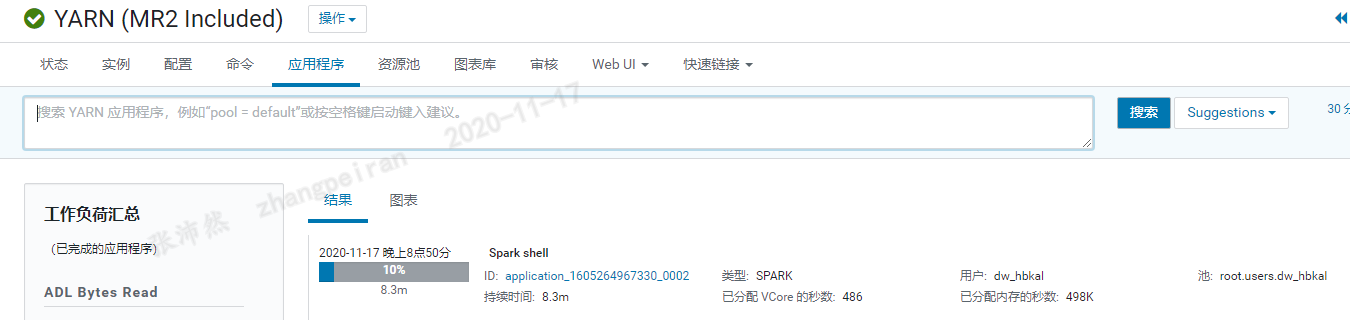
启动spark-shell后,可以发下yarn集群上启动了一个作业,实际上,cdh-spark默认提交作业模式为yarn-client模式,即在本地运行Driver,作业在yarn集群上执行
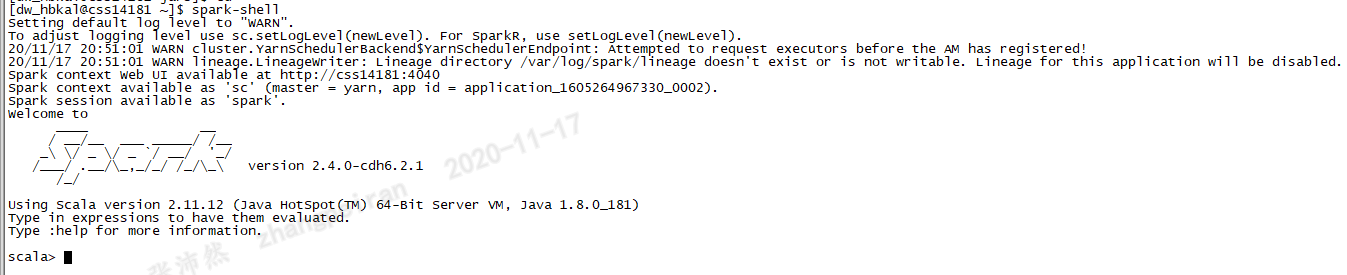
spark-shell启动过程分析
查看spark-shell路径及内容,$LIB_DIR值为/opt/cloudera/parcels/CDH/lib,所以执行的是/opt/cloudera/parcels/CDH/lib/spark/bin/spark-shell
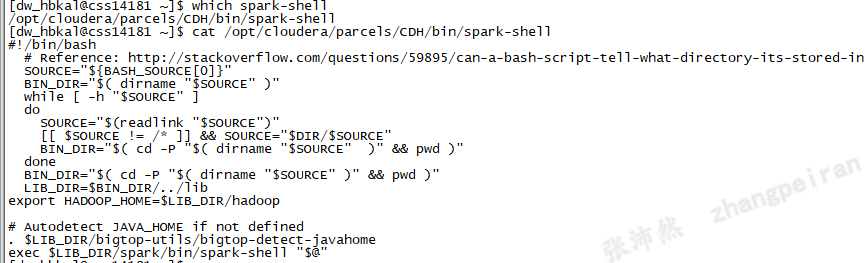
继续查看/opt/cloudera/parcels/CDH/lib/spark/bin/spark-shell,脚本关键的内容如下:
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/spark-shell [options]"
SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true"
function main() {
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
fi
}
main "$@"
上述脚本中首先判断是否存在SPARK_HOME变量,如果不存在的话就执行同一目录下的find-spark-home脚本,改脚本中如果存在SPARK_HOME存在,则直接返回。如果不返回,则查看当前目录下,是否有find_spark_home.py文件。如果存在find_spark_home.py文件,则调用python执行获取结果。如果不存在,则使用当前bin目录的上一级为SPARK_HOME,在本环境中SPARK_HOME被设置为/opt/cloudera/parcels/CDH/lib/spark,设置好SPARK_HOME之后,调用了spark-submit脚本。
查看spark-submit脚本,发现其调用的是${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit,继续查看spark-class脚本,主要内容如下:
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
spark-class中,首先设置了spark-home,然后执行load-spark-env.sh,并添加${SPARK_HOME}/jars目录下的spark依赖,最后执行的是org.apache.spark.launcher.Main类,继续查看load-spark-env.sh
,改脚本主要是设置一些环境变量,关键内容如下:首先是设置spark_home,然后设置${SPARK_CONF_DIR},并执行该目录下的spark-env.sh,SPARK_CONF_DIR默认为spark-home下的的conf目录,本环境为/opt/cloudera/parcels/CDH/lib/spark/conf
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# Save SPARK_HOME in case the user's spark-env.sh overwrites it.
ORIGINAL_SPARK_HOME="$SPARK_HOME"
if [ -z "$SPARK_ENV_LOADED" ]; then
export SPARK_ENV_LOADED=1
export SPARK_CONF_DIR="${SPARK_CONF_DIR:-"${SPARK_HOME}"/conf}"
if [ -f "${SPARK_CONF_DIR}/spark-env.sh" ]; then
# Promote all variable declarations to environment (exported) variables
set -a
. "${SPARK_CONF_DIR}/spark-env.sh"
set +a
fi
fi
继续查看spark-env.sh内容,改脚本中直接设置了spark_home和hadoop_home目录,另外比较重要的是HADOOP_CONF_DIR和HIVE_CONF_DIR,如果没有设置的话,默认为cdh中提供配置文件,否则为用户设置的值,我们的环境bashrc中都设置了这两个变量,因此运行spark-shell时,会知道yarn集群的信息,建议使用spark-sql以及yarn模式运行作业是设置这两个变量
#!/usr/bin/env bash
SELF="$(cd $(dirname $BASH_SOURCE) && pwd)"
if [ -z "$SPARK_CONF_DIR" ]; then
export SPARK_CONF_DIR="$SELF"
fi
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/spark
SPARK_PYTHON_PATH=""
if [ -n "$SPARK_PYTHON_PATH" ]; then
export PYTHONPATH="$PYTHONPATH:$SPARK_PYTHON_PATH"
fi
export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop
export HADOOP_COMMON_HOME="$HADOOP_HOME"
if [ -n "$HADOOP_HOME" ]; then
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
SPARK_EXTRA_LIB_PATH=""
if [ -n "$SPARK_EXTRA_LIB_PATH" ]; then
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SPARK_EXTRA_LIB_PATH
fi
export LD_LIBRARY_PATH
HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-$SPARK_CONF_DIR/yarn-conf}
HIVE_CONF_DIR=${HIVE_CONF_DIR:-/etc/hive/conf}
if [ -d "$HIVE_CONF_DIR" ]; then
HADOOP_CONF_DIR="$HADOOP_CONF_DIR:$HIVE_CONF_DIR"
fi
export HADOOP_CONF_DIR
PYLIB="$SPARK_HOME/python/lib"
if [ -f "$PYLIB/pyspark.zip" ]; then
PYSPARK_ARCHIVES_PATH=
for lib in "$PYLIB"/*.zip; do
if [ -n "$PYSPARK_ARCHIVES_PATH" ]; then
PYSPARK_ARCHIVES_PATH="$PYSPARK_ARCHIVES_PATH,local:$lib"
else
PYSPARK_ARCHIVES_PATH="local:$lib"
fi
done
export PYSPARK_ARCHIVES_PATH
fi
if [ -f "$SELF/classpath.txt" ]; then
export SPARK_DIST_CLASSPATH=$(paste -sd: "$SELF/classpath.txt")
fi
CDH集群spark-shell执行过程分析的更多相关文章
- 关于CDH集群spark的三种安装方式简述
一.spark的命令行模式 1.第一种进入方式:执行 pyspark进入,执行exit()退出 注意报错信息:java.lang.IllegalArgumentException: Required ...
- CDH集群安装&测试总结
0.绪论 之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的: 当我搭建的过程中,发现这些东西是 ...
- Cloudera Manager安装_搭建CDH集群
2017年2月22日, 星期三 Cloudera Manager安装_搭建CDH集群 cpu 内存16G 内存12G 内存8G 默认单核单线 CDH1_node9 Server || Agent ...
- CDH集群搭建部署
1. 硬件准备 使用了五台机器,其中两台8c16g,三台4c8g.一台4c8g用于搭建cmServer和NFS服务端,另外4台作为cloudera-manager agent部署CDH集群. ...
- CDH集群中YARN的参数配置
CDH集群中YARN的参数配置 前言:Hadoop 2.0之后,原先的MapReduce不在是简单的离线批处理MR任务的框架,升级为MapReduceV2(Yarn)版本,也就是把资源调度和任务分发两 ...
- 部署CDH集群环境准备
一.系统centOS7以上,至少三台主机 添加ip 主机名映射关系:(每台主机都要做) vim /etc/hosts 127.0.0.1 localhost localhost.localdomain ...
- 相同版本的CDH集群间迁移hdfs以及hbase
前言 由于项目数据安全的需要,这段时间看了下hadoop的distcp的命令使用,不断的纠结的问度娘,度娘告诉我的结果也让我很纠结,都是抄来抄去, 还好在牺牲大量的时间的基础上还终于搞出来了,顺便写这 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- docker 快速部署ES集群 spark集群
1) 拉下来 ES集群 spark集群 两套快速部署环境, 并只用docker跑起来,并保存到私库. 2)弄清楚怎么样打包 linux镜像(或者说制作). 3)试着改一下,让它们跑在集群里面. 4) ...
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
随机推荐
- 企业级工作流解决方案(十二)--集成Abp和ng-alain--用户身份认证与权限验证
多租户 如果系统需要支持多租户,那么最好事先定义好多租户的存储部署方式,Abp提供了几种方式,根据需要选择,每一个用户身份认证与权限验证都需要完全的隔离 这里设计的权限数据全部存储在缓存中,每个租户单 ...
- FL Studio钢琴卷轴之工具菜单的Riff命令
鼠标左键点击FL Studio钢琴卷轴窗口中的"工具"命令,我们就可以打开快捷工具菜单.快捷菜单中包含了用于音符编辑的各种工具.按照该菜单的顺序,我们先来看一下什么是Riff器命令 ...
- 分享用MathType编辑字母与数学公式的技巧
利用几何画板在Word文档中画好几何图形后,接着需要编辑字母与数学公式,这时仅依靠Word自带的公式编辑器,会发现有很多公式不能编辑,所以应该采用专业的公式编辑器MathType,下面就一起来学习用M ...
- 在FL Studio中有序地处理人声的混音轨道
关于人声处理的技巧,我们在以前也有讲到很多,当然在以后也会有新的人声处理技巧课程,这是在音乐后期制作中无法避免的一个环节,在制作许多流行音乐时都会用到,今天先为大家讲解一下在FL Studio中更有序 ...
- yii\web\Request::cookieValidationKey must be configured with a secret key.
yii\web\Request::cookieValidationKey must be configured with a secret key. 出现的错误表示没有设置 cookieValida ...
- 红外遥控接收发射原理及ESP8266实现
红外遥控是利用近红外光进行数据传输的一种控制方式.近红外光波长0.76um~1.5um ,红外遥控收发器件波长一般为 0.8um~0.94um ,具有传输效率高,成本低,电路实现简单,抗干扰强等特点, ...
- Leetcode 周赛#202 题解
本周的周赛题目质量不是很高,因此只给出最后两题题解(懒). 1552 两球之间的磁力 #二分答案 题目链接 题意 有n个空篮子,第i个篮子位置为position[i],现希望将m个球放到这些空篮子,使 ...
- Java基础教程——Object类
Object类 Object类是Java所有类类型的父类(或者说祖先类更合适) <Thinking in Java(Java编程思想)>的第一章名字就叫"everything i ...
- dubbo协议之请求头编码器
开局一张图,内容全靠XXXXX.... 如图是dubbo协议的格式 encodeRequest进来会先去channel对象中取url的Parameters的"serialization&qu ...
- 使用wapiti进网站进行安全性测试
1.安装wapiti --在命令终端输入 pip install wapiti3 (因为这个结合python使用,所以安装的版本要跟python兼容,因为我的python是3.6版本,所以安装的是wa ...