Python Flask后端异步处理(二)
在实际的应用场景中,如用户注册,用户输入了注册信息后,后端保存信息到数据库中,然后跳转至登录界面,这些操作用户需要等待的时间非常短,但是如果是有耗时任务,比如对输入的网址进行漏洞扫描,在后端处理就会花费几分钟的时间,不可能让用户等待页面刷新几分钟,所以需要进行后端异步处理。之前使用的后端异步处理时Python的原生线程/进程实现,简洁暴力,自己用的话还行,但是如果是给用户用,就还存在一些不足,现考虑使用Celery替换掉原生线程/进程异步处理。
Celery
Celery是个Python语言实现的异步分布式任务队列服务,除了支持即时任务,还支持定时任务,Celery有五个核心角色。
Task 任务
任务(Task)就是你要做的事情,例如一个注册流程里面有很多任务,给用户发验证邮件就是一个任务,这种耗时的任务就可以交给Celery去处理,还有一种任务是定时任务,比如每天定时统计网站的注册人数,这个也可以交给Celery周期性的处理。
Broker 经纪人,队列,消息传递者
Broker 的中文意思是经纪人,指为市场上买卖双方提供中介服务的人。在Celery中这个角色相当于数据结构中的队列,介于生产者和消费者之间经纪人。例如一个Web系统中,生产者是主程序,它生产任务,将任务发送给 Broker,消费者是 Worker,是专门用于执行任务的后台服务。Celery本身不提供队列服务,一般用Redis或者RabbitMQ来实现队列服务。
Worker 执行者,消费者
Worker 就是那个一直在后台执行任务的人,也成为任务的消费者,它会实时地监控队列中有没有任务,如果有就立即取出来执行。
Beat 定时任务调度器
Beat 是一个定时任务调度器,它会根据配置定时将任务发送给 Broker,等待 Worker 来消费。
Backend 执行结果
Backend 用于保存任务的执行结果,每个任务都有返回值,比如发送邮件的服务会告诉我们有没有发送成功,这个结果就是存在Backend中,当然我们并不总是要关心任务的执行结果。
接下来编写一个简单的python程序来学习使用Celery
首先是安装Celery,因为我的开发平台是Windows,Celery新版是不支持Windows操作系统的,需要下载老版本的,这里参考github上Celery开发者的回答: https://github.com/celery/celery/issues/4178
下载3.1.24版本的Celery
pip3 install celery==3.1.24
此外还要下载Reids,并且启动Redis的服务,此处百度
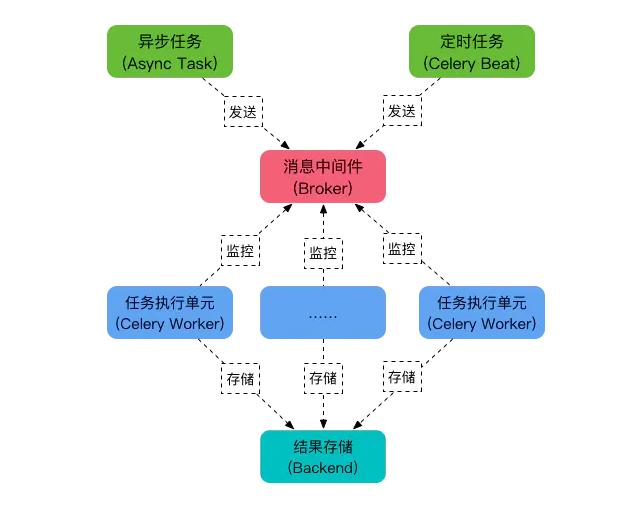
创建Celery实例
# task.py
from celery import Celery
app = Celery('task', broker='redis://localhost:6379/0')
创建任务
#task.py
@app.task
def send_mail(email):
print("send mail to ", email)
import time
time.sleep(5)
return "success"
默认读者有flask基础,另外这里使用app.task 包装 send_email , 使其成为后台运行的任务
函数使用app.task装饰器修饰之后,就会成为Celery中的一个Task。
启动Worker
启动Worker,监听Broker中是否有任务
celery worker
可以带参数如
celery -A task worker --loglevel=info
-A: 指定 celery 实例所在哪个模块中,--loglevel:显示日志等级
运行后如下
调用任务
在主程序中调用任务,调任务发送给Broker,跟开一个多线程和多进程类似,相当于是把任务丢给了Broker,主程序继续向下执行。
from task import send_mail
def register():
import time
start = time.time()
print("1. 插入记录到数据库")
print("2. celery 帮我发邮件")
send_mail.delay("xx@gmail.com")
print("3. 告诉用户注册成功")
print("耗时:%s 秒 " % (time.time() - start))
if __name__ == '__main__':
register()
因为send_mail被app.task装饰器修饰了,所以我们想要把任务丢给它,使用函数的 .delay方法即可
目录结构为:
── Celery测试
├── task.py
└── user.py
运行user.py,查看运行结果为:
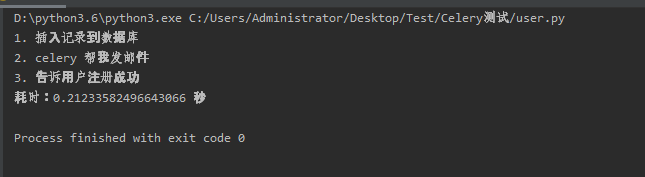
可知
time.sleep(5)
被丢到后台去执行了,所以花费时间这么短。如果按照正常的同步逻辑去实现,至少需要5秒钟的时间,因为存在time.sleep(5)来模拟发送邮件。
在worker服务窗口查看日志信息

跟着大佬们的博客学习了Celery的基本操作,大部分时间去安装环境了,淦
将Celery添加进碎遮项目会在下一篇博客中说到。
请听下回分解 咕咕咕
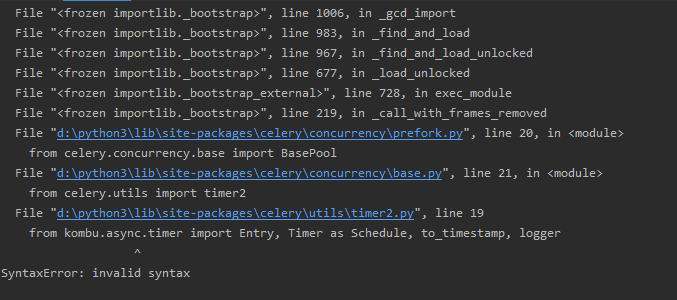
安装出现的错误
File "d:\python3\lib\site-packages\celery\concurrency\prefork.py", line 20, in <module> from celery.concurrency.base import BasePool File "d:\python3\lib\site-packages\celery\concurrency\base.py", line 21, in <module> from celery.utils import timer2 File "d:\python3\lib\site-packages\celery\utils\timer2.py", line 19 from kombu.async.timer import Entry, Timer as Schedule, to_timestamp, logger ^ SyntaxError: invalid syntax
参考自:https://www.cnblogs.com/zivli/p/11517797.html
这个是python3.7目前不支持kombu,降低python版本至3.6即可,(又得重新装一波python,没装conda呜呜呜,卸载之前先把python的类库输出到requirements.txt文件
关于卸载python,可以参考这篇博客:https://blog.csdn.net/ke_yi_/article/details/88183474
如果电脑上是python2和python3共存,请看:https://blog.csdn.net/autista/article/details/73650943
弄好了之后再把之前python3.7的库文件恢复到python3.6里面来
pip3 install -r requirements.txt
弄好了之后重新打开python的集成开发环境
celery -A task worker --loglevel=info
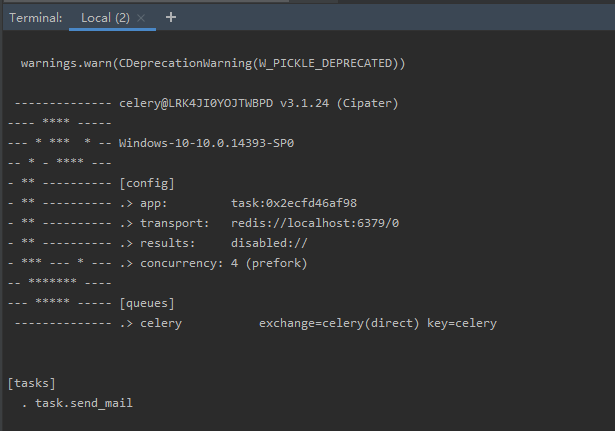
可算能运行Celery了
接着运行程序的时候又遇到了
AttributeError: 'str' object has no attribute 'items'
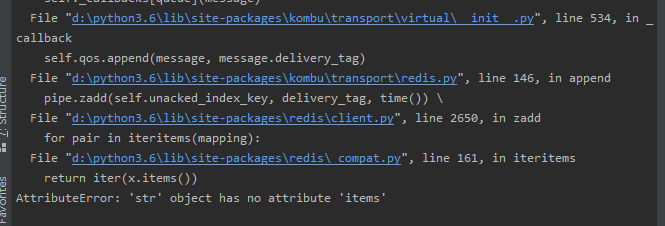
出现该问题的原因是redis版本过高,降低redis版本即可
pip3 install redis==2.10.6
然后就没有遇到其他的坑了,遇到再补:D
参考链接
Python Flask后端异步处理(二)的更多相关文章
- Python Flask后端异步处理(一)
Flask是Python中有名的轻量级同步Web框架,但是在实际的开发中,可能会遇到需要长时间处理的任务,此时就需要使用异步的方式来实现,让长时间任务在后台运行,先将本次请求的相应状态返回给前端,不让 ...
- Python Flask后端异步处理(三)
前一篇博文我们已经将基础知识和环境配置进行了介绍:https://www.cnblogs.com/Cl0ud/p/13192925.html,本篇博文在实际应用场景中使用Celery,对Flask后端 ...
- Python+Flask+Gunicorn 项目实战(一) 从零开始,写一个Markdown解析器 —— 初体验
(一)前言 在开始学习之前,你需要确保你对Python, JavaScript, HTML, Markdown语法有非常基础的了解.项目的源码你可以在 https://github.com/zhu-y ...
- 前端和后端的数据交互(jquery ajax+python flask+mysql)
上web课的时候老师布置的一个实验,要求省市连动,基本要求如下: 1.用select选中一个省份. 2.省份数据传送到服务器,服务器从数据库中搜索对应城市信息. 3.将城市信息返回客户,客户用sele ...
- Python Flask高级编程之RESTFul API前后端分离精讲 (网盘免费分享)
Python Flask高级编程之RESTFul API前后端分离精讲 (免费分享) 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/12eKrJK ...
- Flask + vue 前后端分离的 二手书App
一个Flask + vue 前后端分离的 二手书App 效果展示: https://blog.csdn.net/qq_42239520/article/details/88534955 所用技术清单 ...
- python flask框架学习(二)——第一个flask程序
第一个flask程序 学习自:知了课堂Python Flask框架——全栈开发 1.用pycharm新建一个flask项目 2.运行程序 from flask import Flask # 创建一个F ...
- [Python][flask][flask-wtf]关于flask-wtf中API使用实例教程
简介:简单的集成flask,WTForms,包括跨站请求伪造(CSRF),文件上传和验证码. 一.安装(Install) 此文仍然是Windows操作系统下的教程,但是和linux操作系统下的运行环境 ...
- Python+Flask+MysqL的web建设技术过程
一.前言(个人学期总结) 个人总结一下这学期对于Python+Flask+MysqL的web建设技术过程的学习体会,Flask小辣椒框架相对于其他框架而言,更加稳定,不会有莫名其妙的错误,容错性强,运 ...
随机推荐
- Statistical physics approaches to the complex Earth system(相关系统建模理念方法的摘要)
本文翻译自"Statistical physics approaches to the complex Earth system",其虽然是针对复杂地球系统的统计物理方法的综述,但 ...
- python_for_else_return
def login(): # 登录 # 登录 输入用户名密码 # 和self.user_list作比对 while True: username = input('用户名 :') # password ...
- 【JVM第七篇】执行引擎
写在前面的话:本文是在观看尚硅谷JVM教程后,整理的学习笔记.其观看地址如下:尚硅谷2020最新版宋红康JVM教程 执行引擎是Java虚拟机中的核心组成部分. 执行引擎的作用就是解析虚拟机字节码指令, ...
- linux服务器间配置ssh免密连接
先说一下,我用的centos7,root用户.ssh的原理就不说了,网上介绍的文章很多,直接开始说操作步骤吧: 1.首先确认有没有安装ssh,输入 rpm -qa |grep ssh查看 这样就表示安 ...
- 1-03 Java的基本程序设计结构
1-03 Java的基本程序设计结构 3.1 & 3.2 在一个单词中间使用大写字母的方式称为骆驼命名法.以其自身为例,应该写成CamelCase). 与C/C++一样,关键字void表示这个 ...
- rbd的image对象数与能写入文件数的关系
前言 收到一个问题如下: 一个300TB 的RBD,只有7800万的objects,如果存储小文件的话,感觉不够用 对于这个问题,我原来的理解是:对象默认设置的大小是4M一个,存储下去的数据,如果小于 ...
- ceph单机多mon的实现
ceph默认情况下是以主机名来作为mon的识别的,所以这个情况下用部署工具是无法创建多个mon的,这个地方使用手动的方式可以很方便的创建多个mon 1.创建mon的数据存储目录 mkdir /var/ ...
- 学习一下 Spring Security
一.Spring Security 1.什么是 Spring Security? (1)基本认识 Spring Security 是基于 Spring 框架,用于解决 Web 应用安全性的 一种方案, ...
- Spring第二天,你必须知道容器注册组件的几种方式!学废它吊打面试官!
前一篇<不要再说不会Spring了!Spring第一天,学会进大厂!>文章可点击下方链接进行回看. 不要再说不会Spring了!Spring第一天,学会进大厂! 今天将继续讲解Spri ...
- C#设计模式——代理模式(Proxy Pattern)
引言 在我们的生活中,经常会遇到需要什么东西,但是自己又不是很方便或者对方不是很方便,则就需要中间的一个代理人去解决.例如代购.在软件开发中,也会遇到这样的问题.有些对象有时候会由于网络或其他的障碍, ...