SQL server分页的四种方法(算很全面了)
这篇博客讲的是SQL server的分页方法,用的SQL server 2012版本。下面都用pageIndex表示页数,pageSize表示一页包含的记录。并且下面涉及到具体例子的,设定查询第2页,每页含10条记录。
首先说一下SQL server的分页与MySQL的分页的不同,mysql的分页直接是用limit (pageIndex-1),pageSize就可以完成,但是SQL server 并没有limit关键字,只有类似limit的top关键字。所以分页起来比较麻烦。
SQL server分页我所知道的就只有四种:三重循环;利用max(主键);利用row_number关键字,offset/fetch next关键字(是通过搜集网上的其他人的方法总结的,应该目前只有这四种方法的思路,其他方法都是基于此变形的)。
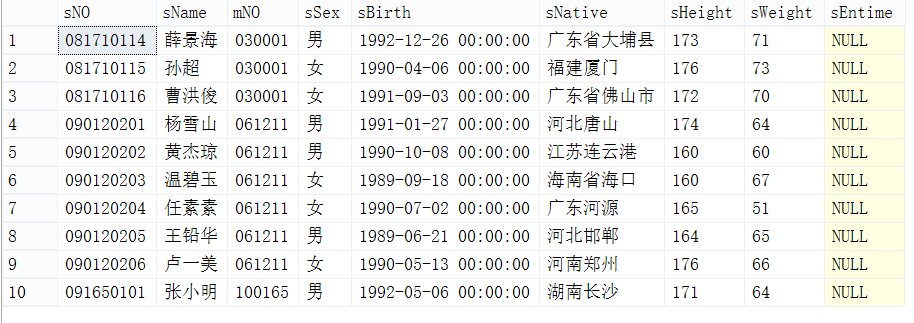
要查询的学生表的部分记录
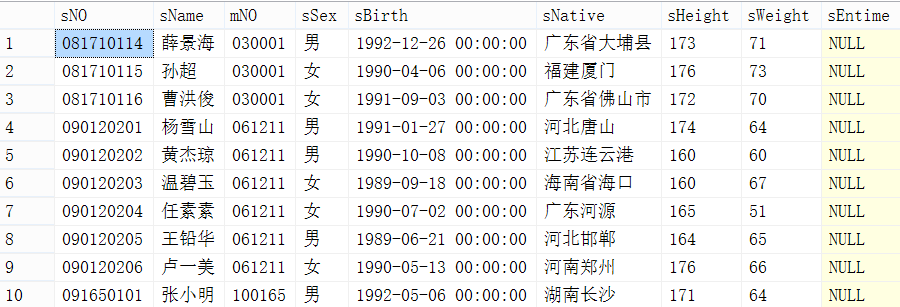
方法一:三重循环
思路
先取前20页,然后倒序,取倒序后前10条记录,这样就能得到分页所需要的数据,不过顺序反了,之后可以将再倒序回来,也可以不再排序了,直接交给前端排序。
还有一种方法也算是属于这种类型的,这里就不放代码出来了,只讲一下思路,就是先查询出前10条记录,然后用not in排除了这10条,再查询。
代码实现
-- 设置执行时间开始,用来查看性能的
set statistics time on ;
-- 分页查询(通用型)
select *
from (select top pageSize *
from (select top (pageIndex*pageSize) *
from student
order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。
as temp_sum_student
order by sNo desc ) temp_order
order by sNo asc
-- 分页查询第2页,每页有10条记录
select *
from (select top 10 *
from (select top 20 *
from student
order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。
as temp_sum_student
order by sNo desc ) temp_order
order by sNo asc
;
查询出的结果及时间

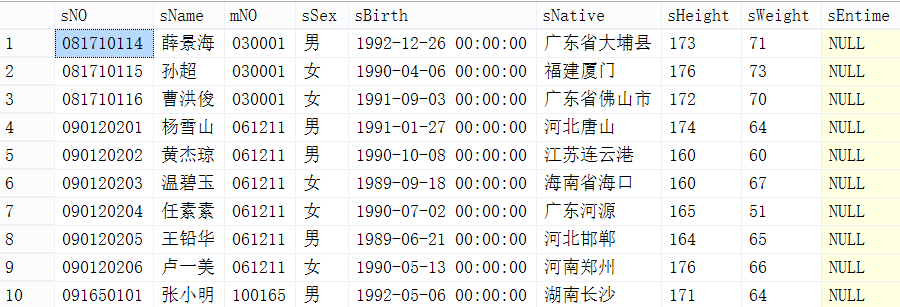
方法二:利用max(主键)
先top前11条行记录,然后利用max(id)得到最大的id,之后再重新再这个表查询前10条,不过要加上条件,where id>max(id)。
代码实现
set statistics time on;
-- 分页查询(通用型)
select top pageSize *
from student
where sNo>=
(select max(sNo)
from (select top ((pageIndex-1)*pageSize+1) sNo
from student
order by sNo asc) temp_max_ids)
order by sNo;
-- 分页查询第2页,每页有10条记录
select top 10 *
from student
where sNo>=
(select max(sNo)
from (select top 11 sNo
from student
order by sNo asc) temp_max_ids)
order by sNo;
查询出的结果及时间

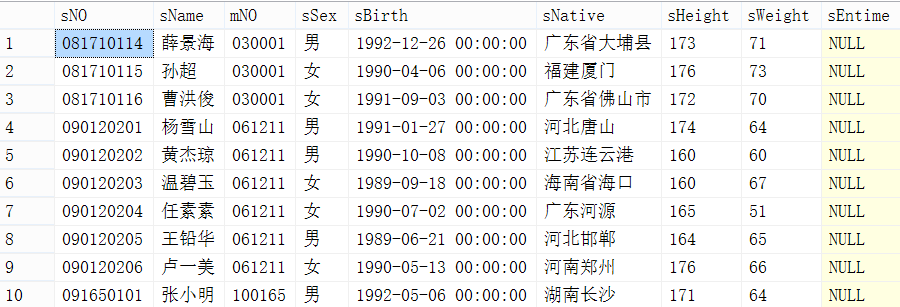
方法三:利用row_number关键字
直接利用row_number() over(order by id)函数计算出行数,选定相应行数返回即可,不过该关键字只有在SQL server 2005版本以上才有。
SQL实现
set statistics time on;
-- 分页查询(通用型)
select top pageSize *
from (select row_number()
over(order by sno asc) as rownumber,*
from student) temp_row
where rownumber>((pageIndex-1)*pageSize);
set statistics time on;
-- 分页查询第2页,每页有10条记录
select top 10 *
from (select row_number()
over(order by sno asc) as rownumber,*
from student) temp_row
where rownumber>10;
查询出的结果及时间

第四种方法:offset /fetch next(2012版本及以上才有)
代码实现
set statistics time on;
-- 分页查询(通用型)
select * from student
order by sno
offset ((@pageIndex-1)*@pageSize) rows
fetch next @pageSize rows only;
-- 分页查询第2页,每页有10条记录
select * from student
order by sno
offset 10 rows
fetch next 10 rows only ;
offset A rows ,将前A条记录舍去,fetch next B rows only ,向后在读取B条数据。
结果及运行时间
封装的存储过程
最后,我封装了一个分页的存储过程,方便大家调用,这样到时候写分页的时候,直接调用这个存储过程就可以了。
分页的存储过程
create procedure paging_procedure
( @pageIndex int, -- 第几页
@pageSize int -- 每页包含的记录数
)
as
begin
select top (select @pageSize) * -- 这里注意一下,不能直接把变量放在这里,要用select
from (select row_number() over(order by sno) as rownumber,*
from student) temp_row
where rownumber>(@pageIndex-1)*@pageSize;
end
-- 到时候直接调用就可以了,执行如下的语句进行调用分页的存储过程
exec paging_procedure @pageIndex=2,@pageSize=10;
总结
根据以上四种分页的方法执行的时间可以知道,以上四种分页方法中,第二,第三,第三四种方法性能是差不多的,但是第一种性能很差,不推荐使用。还有就是这篇博客这是测试了小量数据,还没有分页大量数据,所以不清楚在大量数据要分页时哪种方法的性能更加好。我这里推荐第四种,毕竟第四种是SQL server公司升级后推出的新方法,所以应该理论上性能和可读性都会更加好。

SQL server分页的四种方法(算很全面了)的更多相关文章
- SQL server分页的四种方法
SQL server分页的四种方法 1.三重循环: 2.利用max(主键); 3.利用row_number关键字: 4.offset/fetch next关键字 方法一:三重循环思路 先取前20页, ...
- .net(C#数据库访问) Mysql,Sql server,Sqlite,Access四种数据库的连接方式
便签记录Mysql,Sql server,Sqlite,Access四种数据库的简单连接方式 //using MySql.Data.MySqlClient; #region 执行简单SQL语句,使用M ...
- JavaWeb实现分页的四种方法
一.借助数组进行分页 原理:进行数据库查询操作时,获取到数据库中所有满足条件的记录,保存在应用的临时数组中,再通过List的subList方法,获取到满足条件的所有记录. 实现: 首先在dao层,创建 ...
- SQL Server启动的几种方法
SQL Server 启动有以下几种方法: (1)在Control Panel——Administrative Tools——Services,找到SQL Server (XXX)进行启动. 其中XX ...
- SQL Server 备份的 8 种方法。
方法 1. 完整备份 方法 2. 差异备份 方法 3. 部分备份(备份数据库的read_write部分) 方法 4. 文件备份 方法 5. 文件组备份 方法 6. 只复制备份 方法 7. 日志备份 - ...
- SQL Server事务的四种隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些是在事务内和事务间可见的,哪些是不可见的.较低级别的隔离通常可以执行更高的并发,系统的开销也更低. 1.未提交读(Read ...
- 收缩SQL Server 数据库的几种方法
方法一: Use 数据库名 Select NAME,size From sys.database_files ALTER DATABASE 数据库名 SET RECOVERY SIMPLE WITH ...
- Sql Server分页分段查询百万级数据四种项目实例
实际项目中需要实现自定义分页,最关键第一步就是写分页SQL语句,要求语句效率要高. 那么本文的一个查询示例是查询第100000-100050条记录,即每页50条的结果集.查询的表名为infoTab,且 ...
- SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Server 分页方法汇总
SQL Server游标 转载自:http://www.cnblogs.com/knowledgesea/p/3699851.html. 什么是游标 结果集,结果集就是select查询之后返回的所 ...
随机推荐
- py基础知识(一)
python基础知识(一) print('1','2','3',sep=',',end='.') print 函数的用法 print(value,...,sep='',end='\n') 这里的val ...
- puk2367 拓扑排序
Description The system of Martians' blood relations is confusing enough. Actually, Martians bud when ...
- NB-IOT关键技术分析
NB-IOT(NarrowBand Internet of Things,窄带IoT)是一种基于蜂窝的窄带物联网技术,支持低功耗设备在广域网的蜂窝数据连接.NB-IOT在物联网应用广泛,许多领域都充分 ...
- Hadoop基础------>MR框架-->WordCount
认识Mapreduce Mapreduce编程思想 Mapreduce执行流程 java版本WordCount实例 1. 简介: Mapreduce源于Google一遍论文,是谷歌Mapreduce的 ...
- Docker(10)- docker create 命令详解
如果你还想从头学起 Docker,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1870863.html 作用 创建一个新的容器但不启动它 ...
- CF1108E2 Array and Segments (Hard version)
线段树 对于$Easy$ $version$可以枚举极大值和极小值的位置,然后判断即可 但对于$Hard$ $version$明显暴力同时枚举极大值和极小值会超时 那么,考虑只枚举极小值 对于数轴上每 ...
- 直播平台搭建之音视频开发:认识主流视频编码技术H.264
H.264简介 什么是H.264?H.264是一种高性能的视频编解码技术.目前国际上制定视频编解码技术的组织有两个,一个是"国际电联",它制定的标准有H.261.H.263.H.2 ...
- Mongoose Guide(转)
转自:http://www.w3c.com.cn/mongoose-guide Queries 文件可以通过一些静态辅助模型的方法检索. 任何涉及 指定 查询 条件的模型方法,有两种执行的方式: 当一 ...
- mongoDB之C#and.net Driver
之前一直都是用NodeJS来连接操作mongoDB的,但是最近需要用C#操作mongoDB的需要,所以研究了下C#驱动.mongoDB官方在GitHub上提供了C#驱动源码https://github ...
- php之4个坐标点判断是否为矩形和正方形
代码 <?php $a=[0,0]; $b=[0,1]; $c=[1,1]; $d=[1,0]; $ar=array($a,$b,$c,$d); $a1=[]; // 0 1 2 3 forea ...