Hadoop基础------>MR框架-->WordCount
认识Mapreduce
Mapreduce编程思想
Mapreduce执行流程
java版本WordCount实例
1. 简介:
Mapreduce源于Google一遍论文,是谷歌Mapreduce的克隆版,他充分借鉴了分而治之的思想,讲一个数据处理过程拆分为主要的Map(映射)和Reduce(归并)两步,只需要编写map函数和reduce函数即可。
2. Mapreduce优势:
分布式带来了三个复杂:1.程序的分布和启动
2.任务的监控和失败处理
3.中间数据的缓存和调度
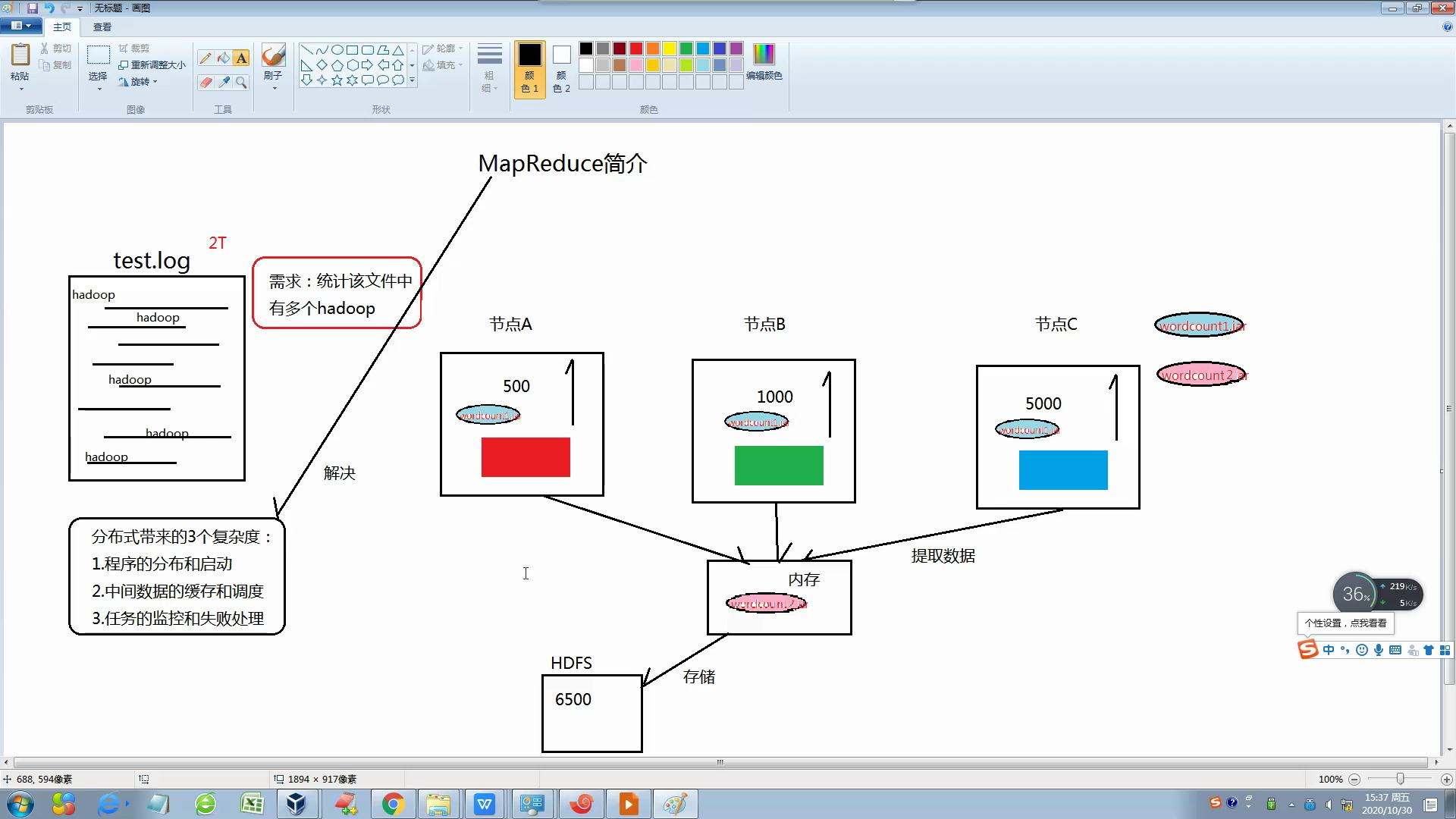
然后Mapreduce是一个并行程序设计模型与方法和好的解决了以上的缺点,并具有:1开发简单
2可扩展性强
3.容错性强
3 Mapreduce的执行流程图:

3-2 Mapreduce的实现过程图:
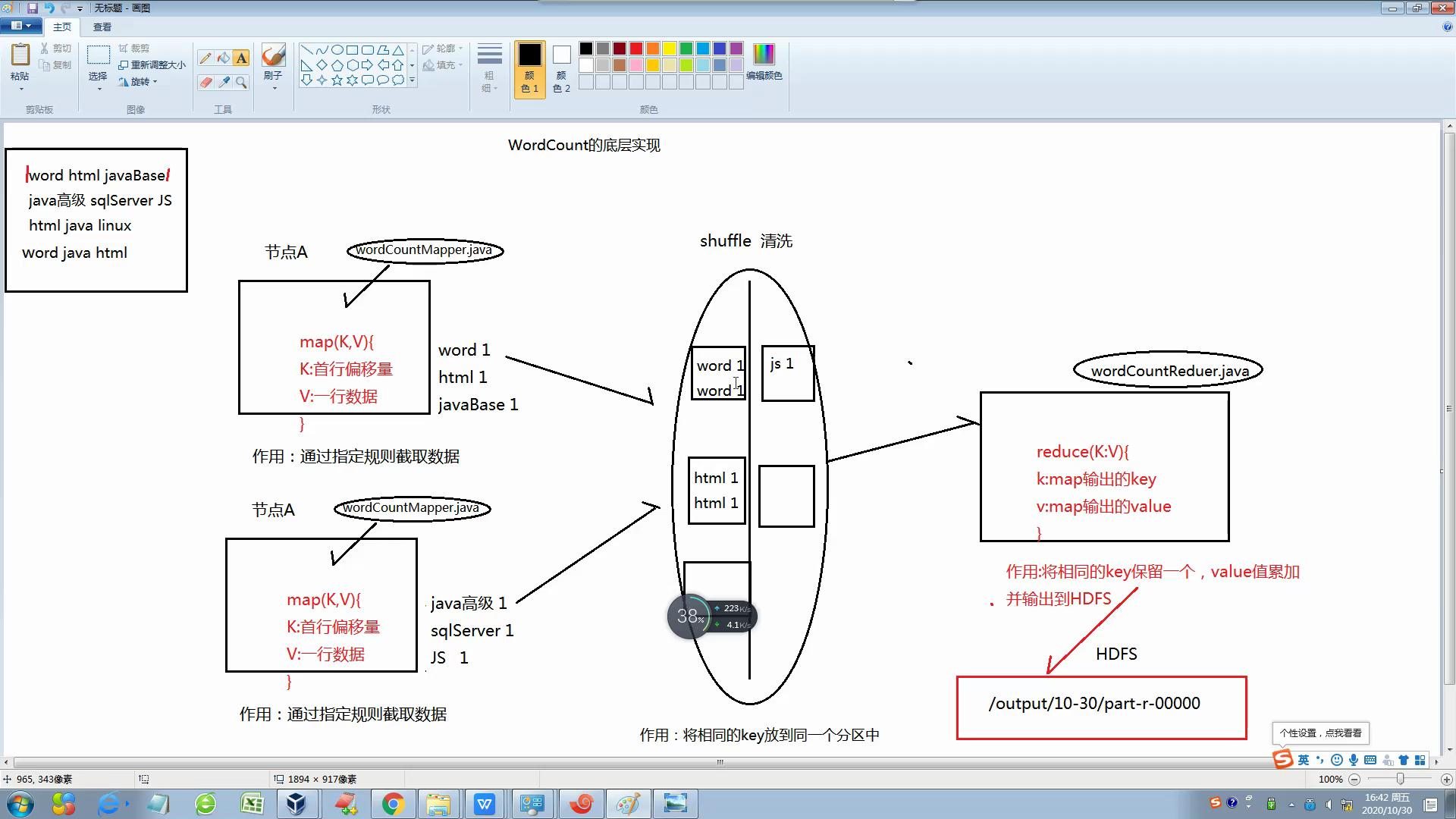
4 基层案例:
- 开发步骤:
- 1.新建项目导入所需的jar包
- 2.编写Mapper类
- 3.编写Reduce类
- 4.提交任务
- 5.观察结果
4-1 Mapper类:继承Mapper类重写map方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:读入每行文件开头的偏移量(首行偏移量)
- VALUEIN:读入每行文件内容的类型
- KEYOUT:表示Mapper完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Mapper完毕后,输出的文件作为VALUE的数据类型
执行流程:
- 读取一行数据
- 按照规则截取
- 获取有效数据
- 将数据写到上下文中
实例:
public class WordCount {
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//读取一行数据
String line = value.toString();
//根据指定规则截取数据
String [] words = line.split(" ");
//获取有效数据
for (int i = 0; i < words.length; i++) {
//将数据写入上下文
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
}
4-2 Reduce类:在写的时候需要继承Reducer类重写ducer方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:表示从mapper中传递过来的key的数据的数据类型
- VALUEIN:表示从mapper中传递过来的value的数据的数据类型
- KEYOUT:表示Reducer完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Reducer完毕后,输出的文件作为VAKUE的数据类型
执行流程:
- 定义一个空的变量来接受定义的值(累加器)
- 遍历values集合,累加统计
- 将结果写入上下文中
实例:
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//定义空变量
int i = 0 ;
//遍历values集合,累加统计
for (IntWritable value : values) {
i += value.get();
}
//写入上下文
context.write(key, new IntWritable(i));
}
}
4-3 提交类编写流程:
- 创建Configuration
- 准备清理已存在的输出目录
- 创建Jop
- 设置job的提交类
- 设置mapper相关的类和参数
- 设置reduce相关的类和参数
- 提交任务
实例:
public static void main(String[] args) throws Exception {
//加载配置文件
Configuration config = new Configuration();
//创建job对象
Job job = Job.getInstance(config);
//设置提交主类
job.setJarByClass(wordCountApp.class);
//设置mapper相关设置提交主类
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reducer相关
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入路径(必须存在hdfs上)
FileInputFormat.setInputPaths(job, new Path("/score.txt"));
//设置输出路径
FileOutputFormat.setOutputPath(job, new Path("/ouput10"));
//提交任务
job.waitForCompletion(true);
}
使用eclipse导出架包,并通关传输软件到LinuX上最后完成上传
Hadoop基础------>MR框架-->WordCount的更多相关文章
- Hadoop基础学习框架
我们主要使用Hadoop的2个部分:分布式文件存储系统(HDFS)和MapReduce计算模型. 关于这2个部分,可以参考一下Google的论文:The Google File System 和 Ma ...
- hadoop之mr框架的源码理解注意点
1.reduce源码中的 GroupComparable和SecondaryComparable到底都是干什么的 理解点1: 源码位置 理解点 secondaryComparable这个是可以对map ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础原理
Hadoop基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出 ...
- Hadoop【MR开发规范、序列化】
Hadoop[MR开发规范.序列化] 目录 Hadoop[MR开发规范.序列化] 一.MapReduce编程规范 1.Mapper阶段 2.Reducer阶段 3.Driver阶段 二.WordCou ...
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
随机推荐
- SON Web Tokens 工具类 [ JwtUtil ]
pom.xml <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt< ...
- Python-全局函数(内置方法、内置函数)
Python有很多内置方法,这些都全局可用 abs() 求数值的绝对值,如果是复数则返回其模 print(abs(-17), abs(30.2), abs(3+4j)) # Python中复数表示为 ...
- 理解RESTful:理论与最佳实践
什么是 REST 什么是 RESTful Richardson 成熟度模型 RESTful API 设计最佳实践 补充:HTTP 状态码及说明 什么是 REST REST 一词,是由 HTTP 协议的 ...
- Python练习题 023:比后面的人大2岁
[Python练习题 023] 有5个人坐在一起,问第五个人多少岁?他说比第4个人大2岁.问第4个人岁数,他说比第3个人大2岁.问第三个人,又说比第2人大两岁.问第2个人,说比第一个人大两岁.最后 问 ...
- CF600E Lomsat gelral 树上启发式合并
题目描述 有一棵 \(n\) 个结点的以 \(1\) 号结点为根的有根树. 每个结点都有一个颜色,颜色是以编号表示的, \(i\) 号结点的颜色编号为 \(c_i\). 如果一种颜色在以 \(x\) ...
- Java date format 时间格式化
import java.util.Date; import java.text.DateFormat; /** * 格式化时间类 * DateFormat.FULL = 0 * DateForma ...
- 046 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 08 for循环的注意事项
046 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 08 for循环的注意事项 本文知识点:for循环的注意事项 for循环的注意事项 for循环有3个 ...
- Java知识系统回顾整理01基础03变量07final关键字
一.final赋值 final 修饰一个变量,有很多种说法,比如不能改变等等 准确的描述是 当一个变量被final修饰的时候,该变量只有一次赋值的机会 二.在声明的时候赋值 i已经被赋值为5,所以这里 ...
- C++读写ini配置文件GetPrivateProfileString()&WritePrivateProfileString()
转载: 1.https://blog.csdn.net/fengbingchun/article/details/6075716 2. 转自:http://hi.baidu.com/andywangc ...
- P3660 [USACO17FEB]Why Did the Cow Cross the Road III G
Link 题意: 给定长度为 \(2N\) 的序列,\(1~N\) 各处现过 \(2\) 次,i第一次出现位置记为\(ai\),第二次记为\(bi\),求满足\(ai<aj<bi<b ...