Hadoop的SecondaryNameNode的作用是什么?
- 为节省篇幅,将SecondaryNameNode简称SNN,NameNode简称NN。
NN与fsimage、edits文件
NN负责管理HDFS中所有的元数据,包括但不限于文件/目录结构、文件权限、块ID/大小/数量、副本策略等等。客户端执行读写操作前,先从NN获得元数据。当NN在运行时,元数据都是保存在内存中,以保证响应时间。
显然,元数据只保留在内存中是非常不可靠的,所以也需要持久化到磁盘。NN内部有两类文件用于持久化元数据:
fsimage文件(镜像文件),以fsimage_为前缀,是序列化存储的元数据的整体快照;
edits文件(又称edit log),以edits_为前缀,是顺序存储的元数据的增量修改(即客户端写入操作)日志。
这两类文件均存储在${dfs.namenode.name.dir}/current/路径下,如下所示。
[root@master current]# pwd
/usr/local/src/hadoop-2.6.1/dfs/name/current
[root@master current]# ls -l
total 1040
-rw-r--r-- 1 root root 1048576 Aug 18 02:07 edits_inprogress_0000000000000000001
-rw-r--r-- 1 root root 351 Aug 18 01:59 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Aug 18 01:59 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Aug 18 02:00 seen_txid
-rw-r--r-- 1 root root 206 Aug 18 01:59 VERSION

可见,当前正在写入的edits文件名会有"inprogress"标识,而seen_txid文件保存的就是当前正在写入的edits文件的ID。
在任意时刻,最近的fsimage和edits文件的内容加起来就是全量元数据。NN在启动时,就会将最近的fsimage文件加载到内存,并重放它之后记录的edits文件,恢复元数据的现场。
SNN与checkpoint过程
为了避免edits文件过大,以及缩短NN启动时恢复元数据的时间,我们需要定期地将edits文件合并到fsimage文件,该合并过程叫做checkpoint(这个词是真正被用烂了哈)。
由于NN的负担已经比较重,再让它来进行I/O密集型的文件合并操作就不太科学了,所以Hadoop引入了SNN负责这件事。也就是说,SNN是辅助NN进行checkpoint操作的角色。
checkpoint的触发由hdfs-site.xml中的两个参数来控制。
dfs.namenode.checkpoint.period:触发checkpoint的周期长度,默认为1小时。
dfs.namenode.checkpoint.txns:两次checkpoint之间最大允许进行的操作数,默认为100万。
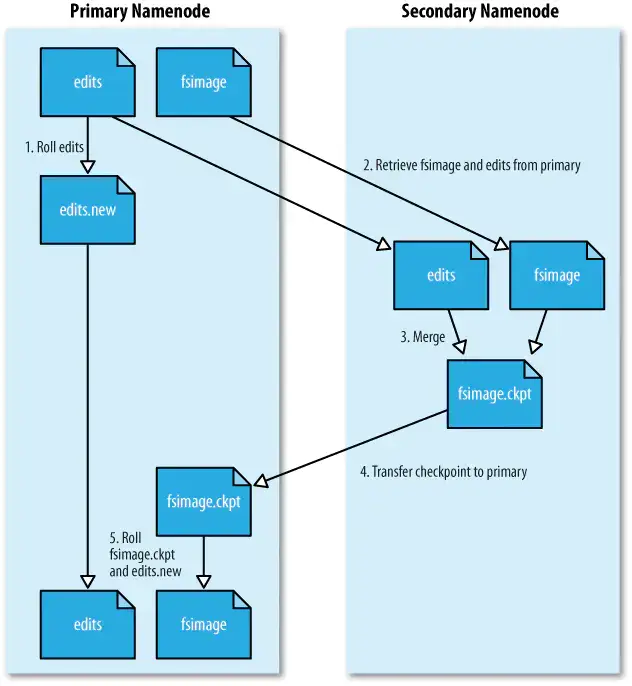
只要满足上述两个参数的条件之一,就会触发checkpoint过程,叙述如下:
NN生成新的edits_inprogress文件,后续的修改日志将写入该文件中,之前正在写的edits文件即为待合并状态。
将待合并的edits文件和fsimage文件一起复制到SNN本地。
SNN像NN启动时一样,将fsimage文件加载到内存,并重放edits文件进行合并。生成合并结果为fsimage.chkpoint文件。
SNN将fsimage.chkpoint复制回NN,并重命名为正式的fsimage文件名。
Hadoop官方给出的图示如下。虽然文件名称不同,但思想是一样的。
如果开启了NN高可用呢?
上面说的都是集群只有一个NN的情况。如果有两个NN并且开启了HA的话,SNN就没用了——checkpoint过程会直接交给Standby NN来负责。Active NN会将edits文件同时写到本地与共享存储(QJM方案就是JournalNode集群)上去,Standby NN从JournalNode集群拉取edits文件进行合并,并保持fsimage文件与Active NN的同步。
Hadoop的SecondaryNameNode的作用是什么?的更多相关文章
- hadoop各个类及其作用
1.基础包(包括工具包和安全包) 包括工具和安全包.其中,hdfs.util包含了一些HDFS实现需要的辅助数据结构:hdfs.security.token.block和hdfs.security.t ...
- SecondaryNameNode 的作用
Secondary NameNode:它究竟有什么作用? 尽量不要将 secondarynamede 和 namenode 放在同一台机器上. 1. NameNode NameNode 主要是用来保存 ...
- hadoop 根据SecondaryNameNode恢复Namenode
1.修改conf/core-site.xml 增加 <property> <name>fs.checkpoint.period</name> <value&g ...
- Hadoop守护进程的作用(转)
概述: <ignore_js_op> Hadoop是一个能够对大量数据进行分布式处理的软件框架,实现了Google的MapReduce编程模型和框架,能够把应用程序分割成许多的 小的工作单 ...
- Hadoop中Combiner的作用
1.Partition 把 Map任务输出的中间结果按 key的范围划分成 R份( R是预先定义的 Reduce任务的个数),划分时通常使用hash函数如: hash(key) mod R,这样可以保 ...
- Hadoop SecondaryNameNode备份及恢复
1.同步各个服务器时间 yum install ntp ntpdate ntp.fudan.edu.cn hdfs-site.xml配置 如果没有配置这一项,hadoop默认是0.0.0.0:5009 ...
- Hadoop集群datanode死掉或者secondarynamenode进程消失处理办法
当Hadoop集群的某单个节点出现问题时,一般不必重启整个系统,只须重启这个节点,它会自动连入整个集群. 在坏死的节点上输入如下命令即可: hadoop-daemon.sh start datanod ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- hadoop面试100道收集(带答案)
1.列出安装Hadoop流程步骤 a) 创建hadoop账号 b) 更改ip c) 安装Java 更改/etc/profile 配置环境变量 d) 修改host文件域名 e) 安装ssh 配置无密码登 ...
随机推荐
- 人工智能?.netcore一样胜任!
提起AI,大家都会先想到Python,确实Python作为一门好几十年的老语言,上一波的AI大流行使它焕发了青春.大家用Phtyon来做AI,最主要的原因无非就是编码量更少,很多数学和AI相关的Api ...
- Python long() 函数
描述 long() 函数将数字或字符串转换为一个长整型.高佣联盟 www.cgewang.com 语法 long() 函数语法: class long(x, base=10) 参数 x -- 字符串或 ...
- PDO::getAttribute
PDO::getAttribute — 取回一个数据库连接的属性(PHP 5 >= 5.1.0, PECL pdo >= 0.1.0) 说明 语法 mixed PDO::getAttrib ...
- PDO::getAvailableDrivers
PDO::getAvailableDrivers — 返回一个可用驱动的数组(PHP 5 >= 5.1.0, PECL pdo >= 0.1.0) 说明 语法 static array P ...
- PHP getName() 函数
实例 返回 XML 元素及其子元素的名称: <?php$xml=<<<XML高佣联盟 www.cgewang.com<?xml version="1.0&quo ...
- C/C++编程笔记:C语言写推箱子小游戏,大一学习C语言练手项目
C语言,作为大多数人的第一门编程语言,重要性不言而喻,很多编程习惯,逻辑方式在此时就已经形成了.这个是我在大一学习 C语言 后写的推箱子小游戏,自己的逻辑能力得到了提升,在这里同大家分享这个推箱子小游 ...
- 程序员面试:C/C++求职者必备 20 道面试题,一道试题一份信心!
面试真是痛并快乐的一件事,痛在被虐的体无完肤,快乐在可以短时间内积累很多问题,加速学习. 在我们准备面试的时候,遇到的面试题有难有易,不能因为容易,我们就轻视,更不能因为难,我们就放弃.我们面对高薪就 ...
- SparkSQL & Spark on Hive & Hive on Spark
刚开始接触Spark被Hive在Spark中的作用搞得云里雾里,这里简要介绍下,备忘. 参考:https://blog.csdn.net/zuochang_liu/article/details/82 ...
- iOS CALayer 简单介绍
https://www.jianshu.com/p/09f4e36afd66 什么是CALayer: 总结:能看到的都是uiview,uiview能显示在屏幕上是因为它内部的一个层calyer层. 在 ...
- JVM进行篇
结合字节码指令理解Java虚拟机栈和栈帧 栈帧:每个栈帧对应一个被调用的方法,可以理解为一个方法的 ...