时序数据库 Apache-IoTDB 源码解析之元数据索引块(六)
上一章聊到 TsFile 索引块的详细介绍,以及一个查询所经过的步骤。详情请见:
时序数据库 Apache-IoTDB 源码解析之文件索引块(五)
打一波广告,欢迎大家访问 IoTDB 仓库,求一波 Star 。欢迎关注头条号:列炮缓开局,欢迎关注OSCHINA博客
阿里云、东方国信等各家公司正在招聘IoTDB数据库开发工程师,欢迎加我微信内推:liutaohua001
这一章主要想聊聊:
- 原有索引中的不足
- 新版本中索引的设计
原有索引中的不足
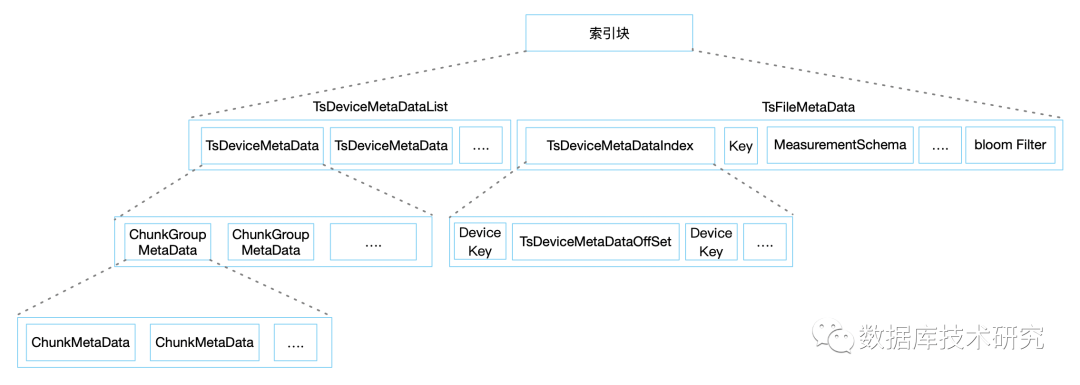
现在来张图回顾一下原有的数据存储方式,在文件尾部使用DeviceMetaDataIndexMap和MeasurementSchemaMap中记录所有设备数据偏移量、传感器的相关信息等。因为使用的是Map结构访问都是O(1)的,但是需要关注的一个问题就是它是在内存中O(1)的,在磁盘上并不能找到什么好的查询方式,唯一能做的就是全部读取出来然后放到内存中。
通常情况下这不会有什么问题,但是使用在工业场景中,传感器+设备很有可能数以百万计,这会引发无论你读取的是一个传感器或者是一个设备的数据,在DeviceMetaDataIndexMap这一段数据都需要完整的从磁盘上读取回来,这好吗?这不好,还拿之前的数据举例:
| 时间戳 | 人名 | 体温 | ... | 年龄 |
|---|---|---|---|---|
| 1580950800 | 张一 | 36.5 | ... | 30 |
| 1580950800 | 张二 | 36.9 | ... | 30 |
| 1580950800 | 张三 | 36.7 | ... | 30 |
| 1580950800 | 张.. | 36.7 | ... | 30 |
| 1580950800 | 张两百万 | 36.7 | ... | 30 |
当执行一个查询select 体温 from 张三 where time = 1580950800 时,张一、张二、张三...张两百万这两百万个名字都需要从硬盘中读取并反序列化出来(通常 IoTDB 中的路径是root.T000100010002.A_JB01.JB01.JTJBGMCA6K2052561),也就是1999999个都是多余的读取。
此外,在TsDeviceMetaDataList中,也是按照chunkGroup存储,意味着,如果我仅查询一列,同样会把其它的列信息读取出来。
新版本中索引的设计
为了尽可能贴近只读投影列的思想,新版本中对于TsDeviceMetaDataList部分不再按照设备级别存储,改为按照传感器级别存储,TsFileMetaData部分不再使用map存储所有设备,改为使用多叉树并有序排列。
改动1: 使用将一个传感器的所有ChunkMetaData的存储在一起,并使用TimeseriesMetadata结构进行维护(保存某个传感器的开始的offset及数据长度),如图: 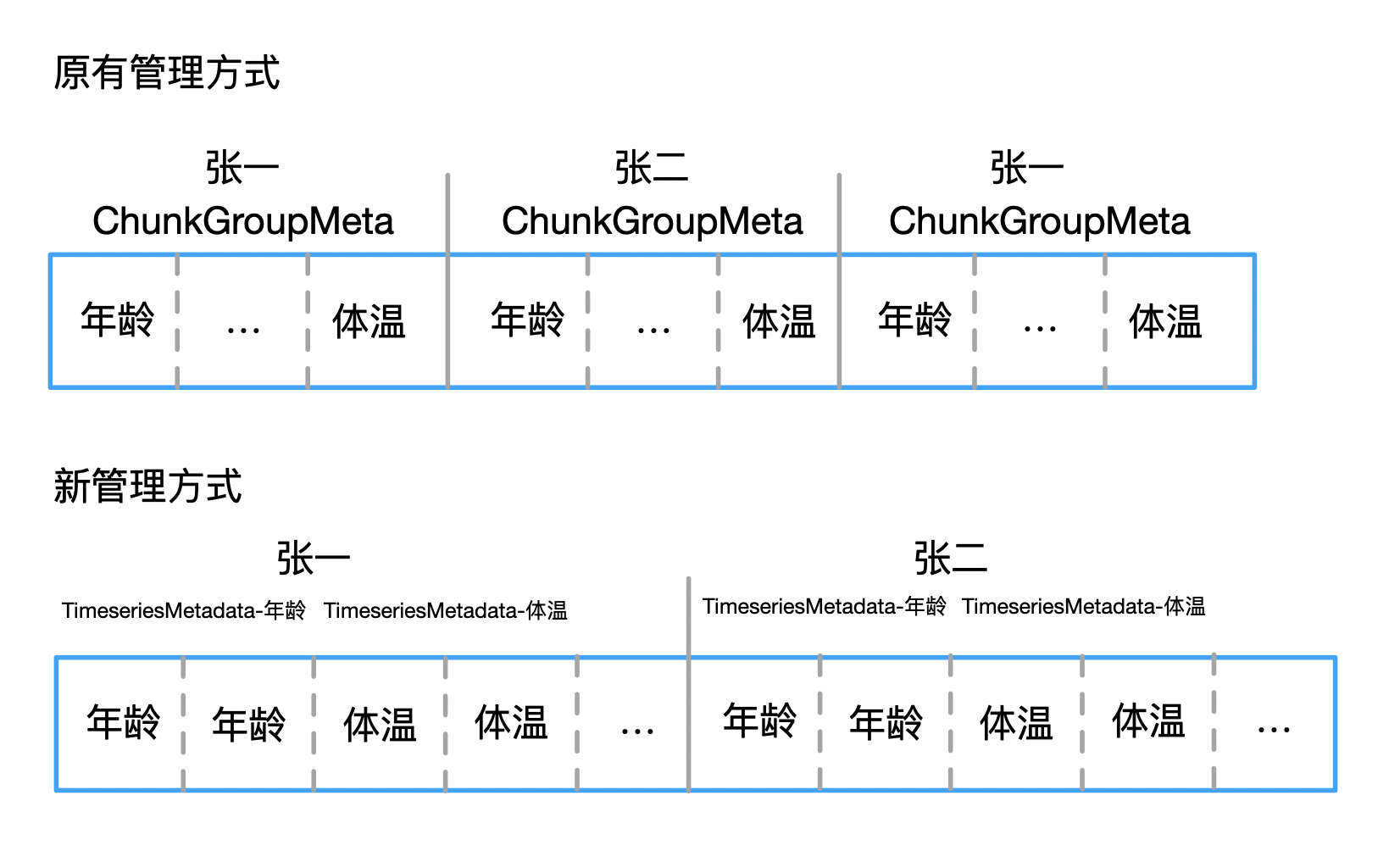
改动2: 在完成改动1之后,我们得到了TimeSeriesMetadata-年龄,TimeSeriesMetadata-体温, ..., TimeSeriesMetadata-x,在刷盘之前将所有TimeSeriesMetadata按照传感器名字排序,那么在这里就可以进行二分查找了,如图:
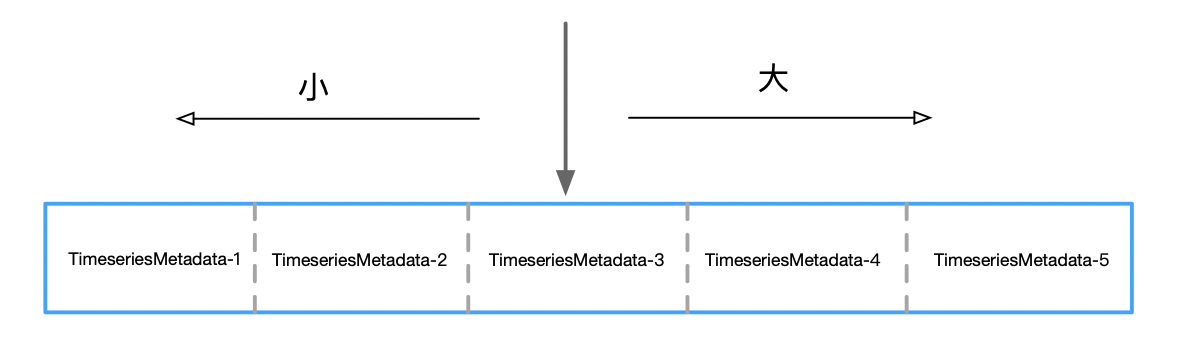
改动3: 在一个复杂的设备上传感器很有可能多达数千个,例如:新能源汽车当中,每台车量可以多达4000多个信号项。假如我们需要管理10万辆车,那么依然会有10万 * 4000 = 4亿个TimeSeriesMetadata。还是太多了,假如我们进行多个传感器的值查询时,每次都进行二分,这无疑是浪费的。
所以进行一个树状的提取,假设每1024个提取一次,那么4亿个可以节省为390,625个,假如再抽取一次,那就可以减少到382个了,这样我们从硬盘上一次读取1024个,最多读取3次硬盘就可以完成查找。大意如图: 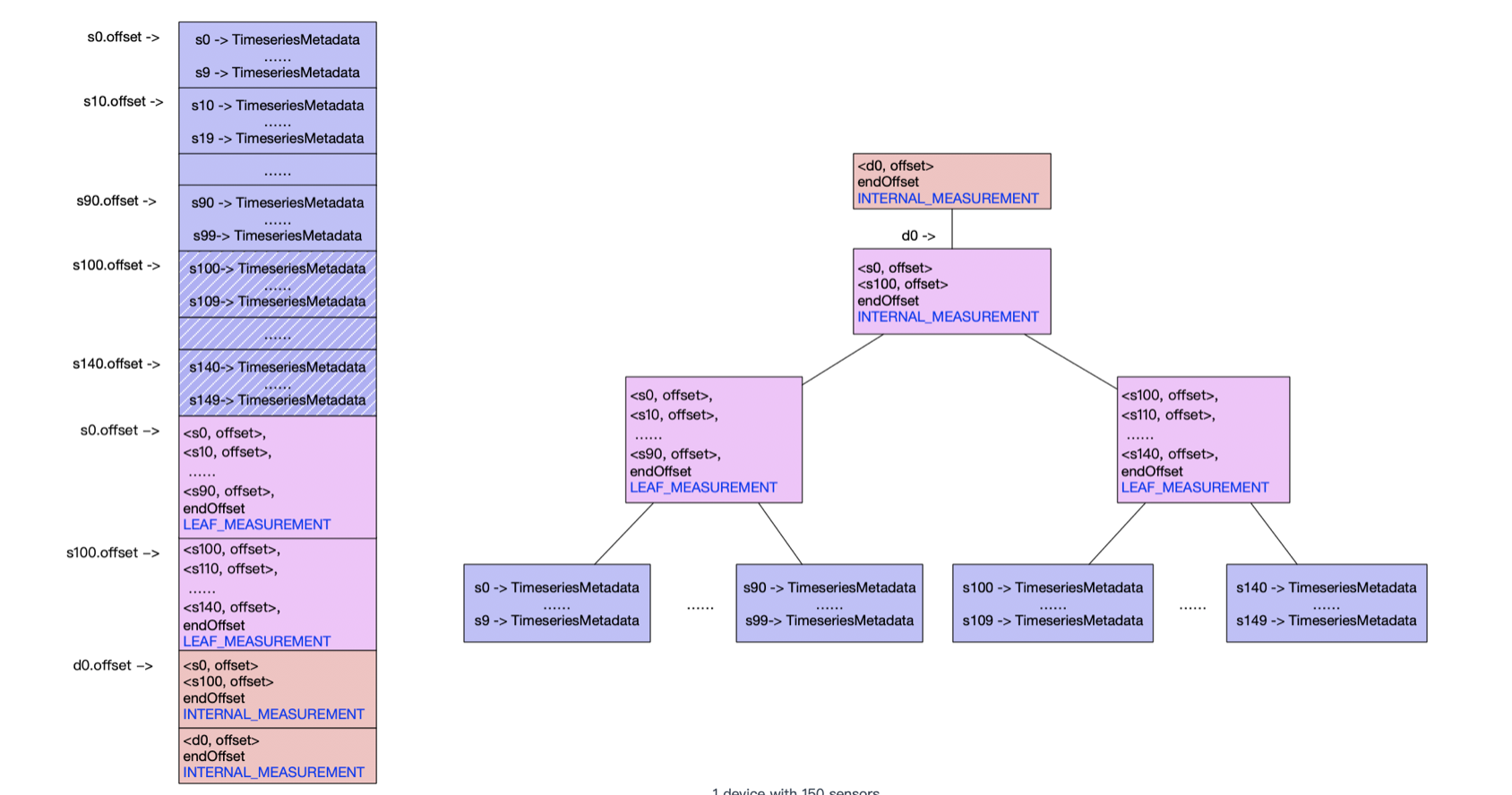
改动4: 除了传感器之外,还要考虑的是设备级别,因为设备也是数以万计,但同上面的逻辑是一样的。再此就不进行赘述,如图: 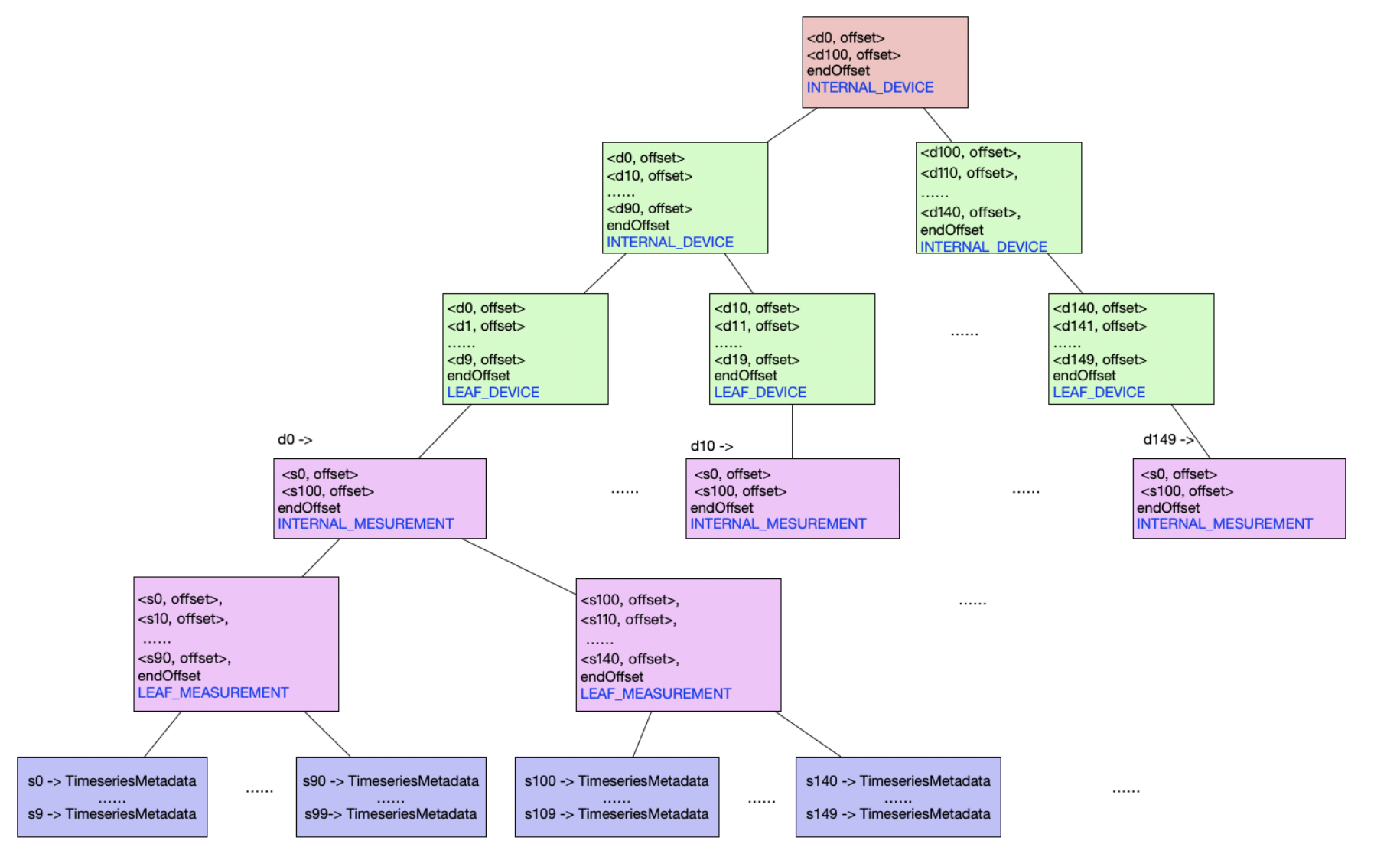
在代码中使用MetadataIndexNode类进行存储图中的数据,代表了当前节点属于管理设备的节点还是管理传感器的节点,是中间节点还是叶子节点。使用MetadataIndexEntry用来存储具体的信息,也就是TimeSeriesMetadata结构在硬盘上的偏移量或者子节点MetadataIndexNode在硬盘上的偏移量.
附上一个文件展示:
POSITION| CONTENT
-------- -------
0| [magic head] TsFile
6| [version number] 000002
||||||||||||||||||||| [Chunk Group] of root.sg1.d1, num of Chunks:10000
12| [Chunk] of s8289, numOfPoints:500, time range:[0,499], tsDataType:INT64,
startTime: 0 endTime: 499 count: 500 [minValue:1,maxValue:1,firstValue:1,lastValue:1,sumValue:500.0]
| 1 pages
...
350026| [Chunk] of s0, numOfPoints:500, time range:[0,499], tsDataType:INT64,
startTime: 0 endTime: 499 count: 500 [minValue:1,maxValue:1,firstValue:1,lastValue:1,sumValue:500.0]
| 1 pages
...
1418902| [Chunk Group Footer]
| [marker] 0
| [deviceID] root.sg1.d1
| [dataSize] 1418890
| [num of chunks] 10000
||||||||||||||||||||| [Chunk Group] of root.sg1.d1 ends
1418947| [marker] 2
1418948| [ChunkMetadataList] of root.sg1.d1.s0, tsDataType:INT64
| [ChunkMetaData] of s0, offset:350026
...
2247838| [TimeseriesMetadata] name:s0, offset:1418948, chunkMetaDataListDataSize:80
3116728| [MetadataIndexNode] nodeType:LEAF_MEASUREMENT, childSize:10
| [MetadataIndexEntry] name:s0, offset:2247838, endOffset:2336808
| [MetadataIndexEntry] name:s192, offset:2336808, endOffset:2425782
| [MetadataIndexEntry] name:s2841, offset:2425782, endOffset:2514757
| [MetadataIndexEntry] name:s3763, offset:2514757, endOffset:2603732
| [MetadataIndexEntry] name:s4685, offset:2603732, endOffset:2692705
| [MetadataIndexEntry] name:s5606, offset:2692705, endOffset:2781680
| [MetadataIndexEntry] name:s6528, offset:2781680, endOffset:2870655
| [MetadataIndexEntry] name:s745, offset:2870655, endOffset:2959629
| [MetadataIndexEntry] name:s8371, offset:2959629, endOffset:3048604
| [MetadataIndexEntry] name:s9293, offset:3048604, endOffset:3116728
3116906| [TsFileMetadata] deviceNums:1,chunkNums:10000,invalidChunkNums:0
| [MetadataIndexNode] nodeType:INTERNAL_MEASUREMENT,childSize:1
| [MetadataIndexEntry] name:root.sg1.d1,offset:3116728,endOffset:3116906
| [bloom filter bit vector byte array length] 7794
| [bloom filter bit vector byte array]
| [bloom filter number of bits] 62353
| [bloom filter number of hash functions] 5
3124764| [TsFileMetadataSize] 7858
3124768| [magic tail] TsFile
3124774| END of TsFile
---------------------------------- TsFile Sketch End ----------------------------------
到此已经介绍完了文件的整体结构,以及索引的改进过程。
那么一个sql是如何执行的呢,是怎样进行的查询?又是怎样高速的写入数据?
欢迎持续关注。。。。
时序数据库 Apache-IoTDB 源码解析之元数据索引块(六)的更多相关文章
- 时序数据库 Apache-IoTDB 源码解析之文件索引块(五)
上一章聊到 TsFile 的文件组成,以及数据块的详细介绍.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件数据块(四) 打一波广告,欢迎大家访问IoTDB 仓库,求一波 Star. ...
- Ocelot简易教程(七)之配置文件数据库存储插件源码解析
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9852711.html 上篇文章给大家分享了如何集成我写的一个Ocelot扩展插件把Ocelot的配置存储 ...
- identityserver4源码解析_2_元数据接口
目录 identityserver4源码解析_1_项目结构 identityserver4源码解析_2_元数据接口 identityserver4源码解析_3_认证接口 identityserver4 ...
- 时序数据库 Apache-IoTDB 源码解析之文件数据块(四)
上一章聊到行式存储.列式存储的基本概念,并介绍了 TsFile 是如何存储数据以及基本概念.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件格式简介(三) 打一波广告,欢迎大家访问Io ...
- tensorflow源码解析系列文章索引
文章索引 framework解析 resource allocator tensor op node kernel graph device function shape_inference 拾遗 c ...
- Mybatis源码解析(四) —— SqlSession是如何实现数据库操作的?
Mybatis源码解析(四) -- SqlSession是如何实现数据库操作的? 如果拿一次数据库请求操作做比喻,那么前面3篇文章就是在做请求准备,真正执行操作的是本篇文章要讲述的内容.正如标题一 ...
- identityserver4源码解析_3_认证接口
目录 identityserver4源码解析_1_项目结构 identityserver4源码解析_2_元数据接口 identityserver4源码解析_3_认证接口 identityserver4 ...
- [源码解析] 从TimeoutException看Flink的心跳机制
[源码解析] 从TimeoutException看Flink的心跳机制 目录 [源码解析] 从TimeoutException看Flink的心跳机制 0x00 摘要 0x01 缘由 0x02 背景概念 ...
- [源码解析] Flink的Slot究竟是什么?(1)
[源码解析] Flink的Slot究竟是什么?(1) 目录 [源码解析] Flink的Slot究竟是什么?(1) 0x00 摘要 0x01 概述 & 问题 1.1 Fllink工作原理 1.2 ...
随机推荐
- Core3.0路由配置
前言 MSDN文档,对ASP.NETCore中的路由完整的介绍 https://docs.microsoft.com/zh-cn/aspnet/core/fundamentals/routing?vi ...
- C#中获取DataTable某一列的值转换为集合
直接使用 //Linqvar l1 = (from d in dt.AsEnumerable() select d.Field<int>("ID")).ToList() ...
- Excel 多/整列(多/整行)移位操作
步骤1:创建测试数据 步骤2:把B列和C列进行移位操作(整列移位操作,多列移位操作方法一样) 选中B列,鼠标放到B列边缘地带,直到鼠标显示带有四个箭头方向为止,点击键盘shift键进行拖拽,拖拽时显示 ...
- 微服务 - 服务消费(七)Feign
介绍 Spring Cloud Feign是一套基于Netflix Feign实现的声明式服务调用客户端.它使得编写Web服务客户端变得更加简单.我们只需要通过创建接口并用注解来配置它既可完成对Web ...
- Java面试被经常问到的常用算法
一.冒泡排序 原理:比较两个相邻的元素,较大的放在右边 N个数字要排序完成,总共进行N-1趟排序,每i趟的排序次数为(N-i)次 最好时间复杂度为O(N) Cmax = N(N-1)/2 = O(N2 ...
- python保存二维列表到txt文件,读取txt文件里面的数据转化为二维列表
源码: # 读文件里面的数据转化为二维列表 def Read_list(filename): file1 = open(filename+".txt", "r" ...
- C语言I博客作业1
1 .班级链接: https://edu.cnblogs.com/campus/zswxy/SE2020-3 2 .作业要求链接: https://edu.cnblogs.com/campus/zsw ...
- 解决threadLocal父子变量传递问题
一.问题的提出 在系统开发过程中常使用ThreadLocal进行传递日志的RequestId,由此来获取整条请求链路.然而当线程中开启了其他的线程,此时ThreadLocal里面的数据将会出现无法获取 ...
- 两个字搞定DDD(领域驱动设计),DDD脱水版(一)修订版
摘自微信公众号丁辉的软件架构说
- ASP.NET Core路由中间件[3]: 终结点(Endpoint)
到目前为止,ASP.NET Core提供了两种不同的路由解决方案.传统的路由系统以IRouter对象为核心,我们姑且将其称为IRouter路由.本章介绍的是最早发布于ASP.NET Core 2.2中 ...