爬虫系列(十三) 用selenium爬取京东商品
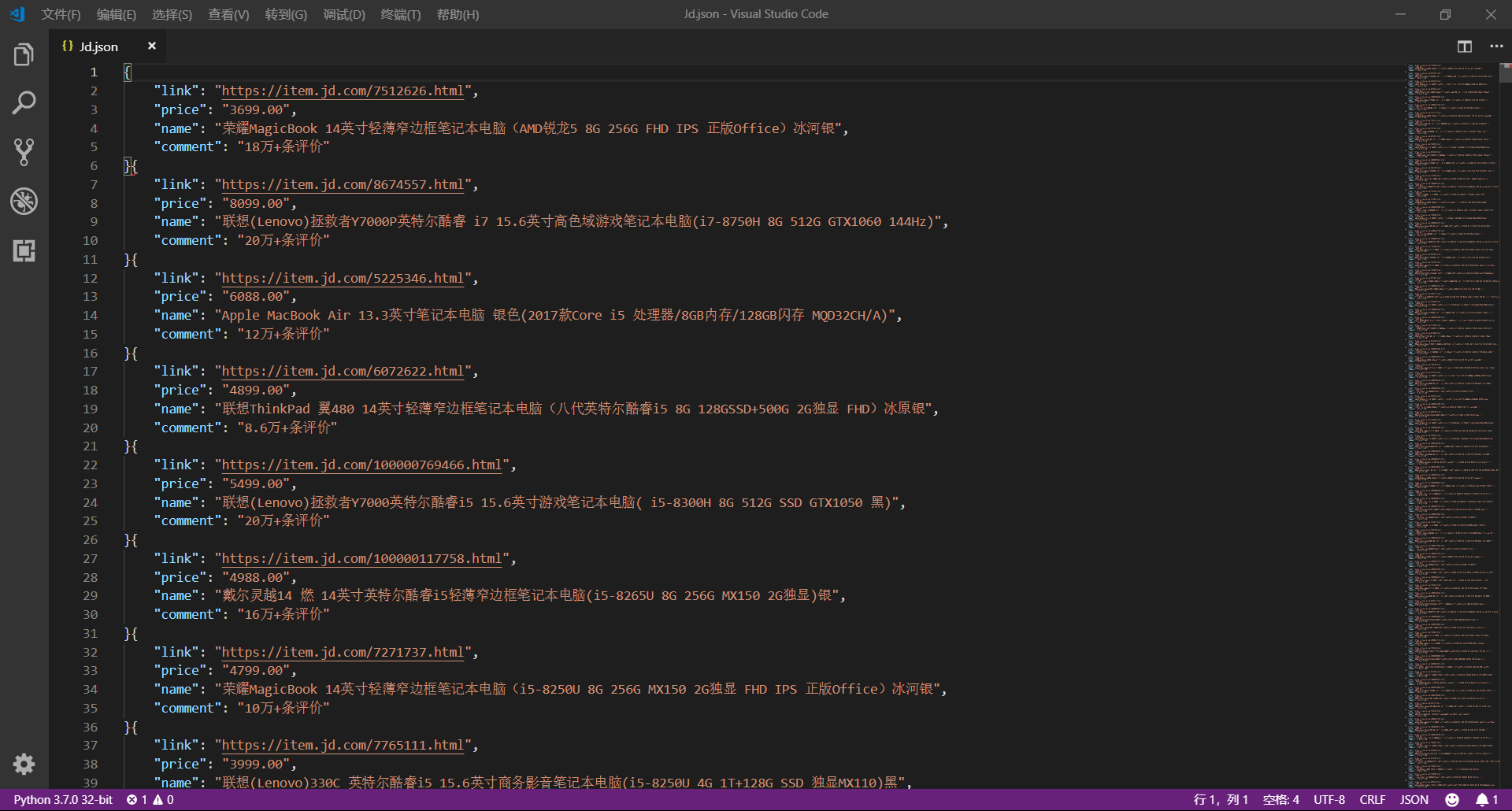
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图:
1、网页分析
(1)初步分析
原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程中发现,不同商品的网页结构竟然是不一样的
所以,后来就放弃了这个想法,转为只爬取笔记本类型商品的信息
如果需要爬取其它类型的商品信息,只需把提取数据的规则改变一下就好,有兴趣的朋友可以自己试试看呀
好了,下面我们正式开始!
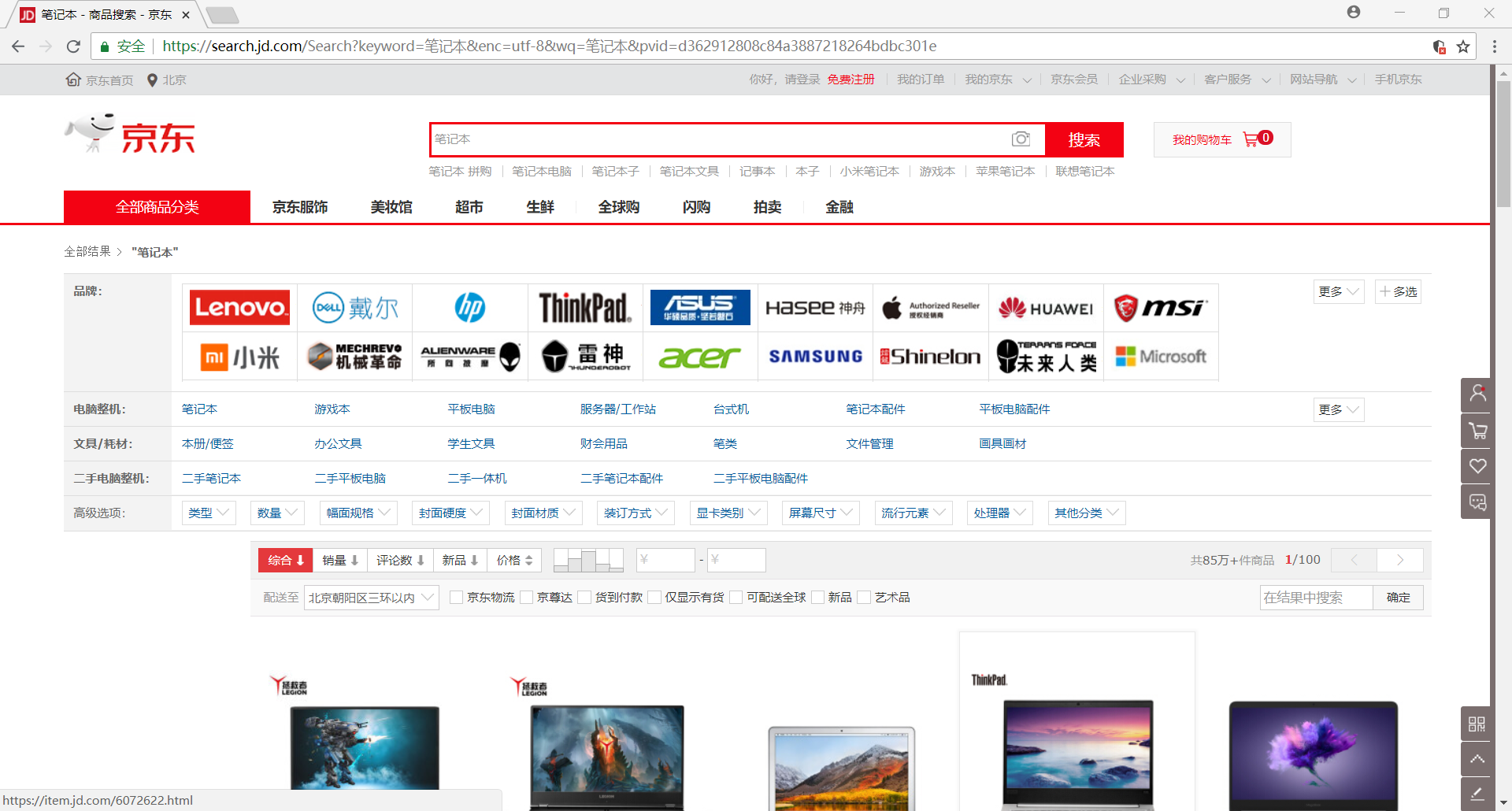
首先,用 Chrome 浏览器打开 笔记本商品首页,我们很容易发现该网页是一个 动态加载 的网页
因为刚打开网页时只会显示 30 个商品的信息,可是当我们向下拖动网页时,它会再次加载剩下 30 个商品的信息
这时候我们可以通过 selenium 模拟浏览器下拉网页的过程,获取网站全部商品的信息
>>> browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
(2)模拟翻页
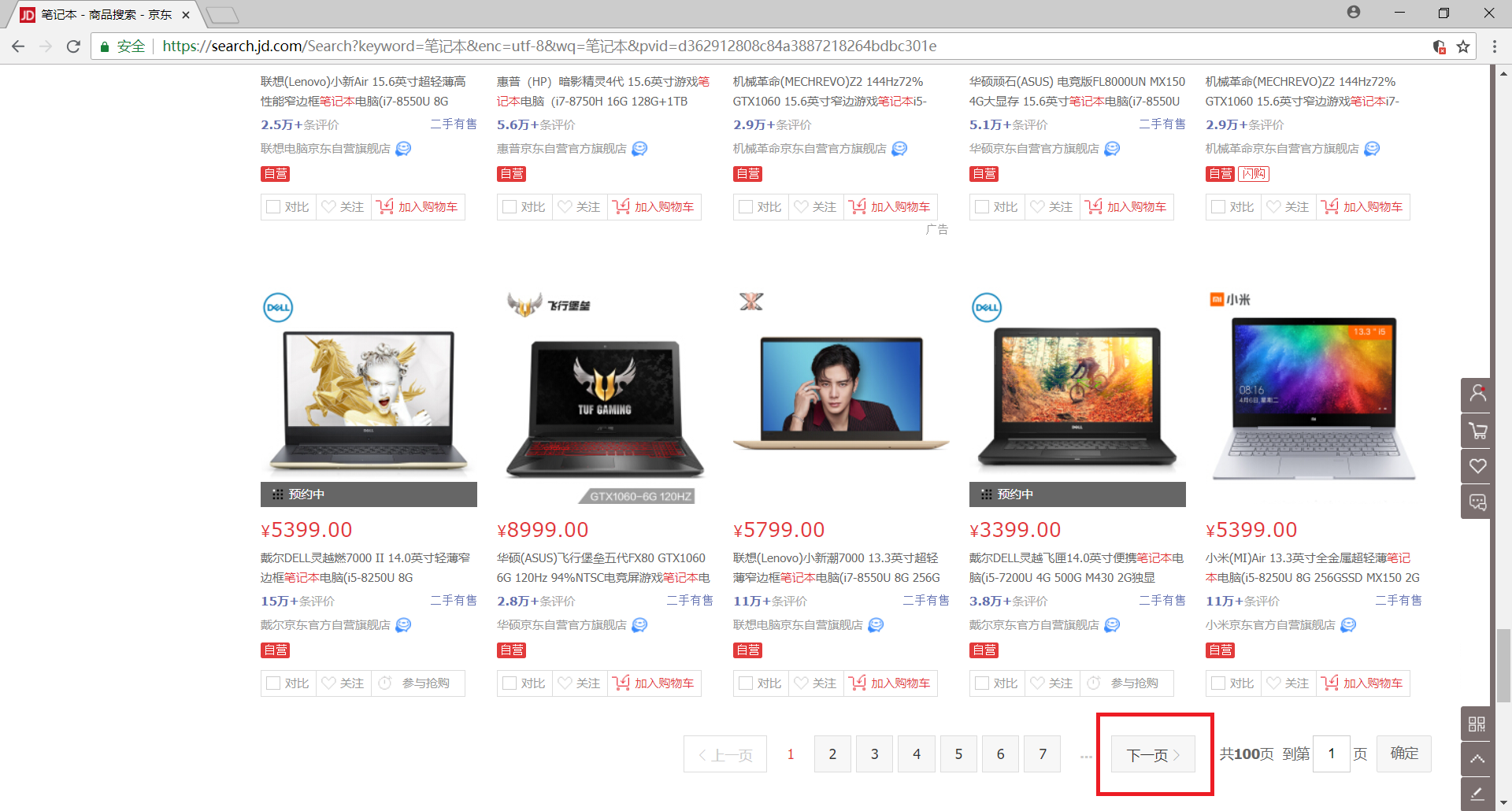
另外,我们发现该网站一共有 100 个网页
我们可以通过构造 URL 来获取每一个网页的内容,但是这里我们还是选择使用 selenium 模拟浏览器的翻页行为
下拉网页至底部可以发现有一个 下一页 的按钮,我们只需获取并点击该元素即可实现翻页
>>> browser.find_element_by_xpath('//a[@class="pn-next" and @onclick]').click()
(3)获取数据
接下来,我们需要解析每一个网页来获取我们需要的数据,具体包括(可以使用 selenium 选择元素):
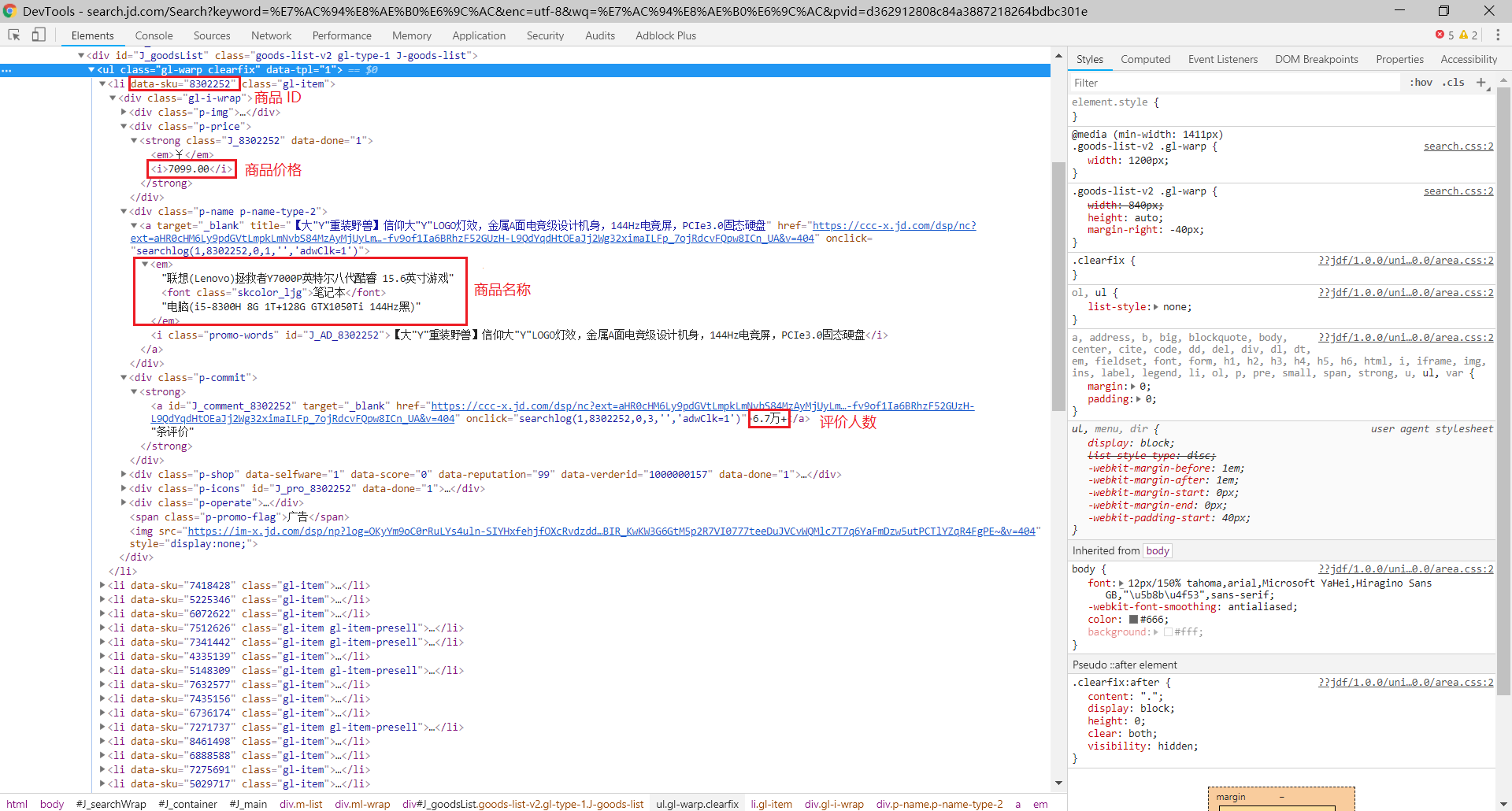
- 商品 ID:
browser.find_elements_by_xpath('//li[@data-sku]'),用于构造链接地址 - 商品价格:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[2]/strong/i') - 商品名称:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[3]/a/em') - 评论人数:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[4]/strong')
2、编码实现
好了,分析过程很简单,基本思路是使用 selenium 模拟浏览器的行为,下面是代码实现
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import selenium.common.exceptions
import json
import csv
import time
class JdSpider():
def open_file(self):
self.fm = input('请输入文件保存格式(txt、json、csv):')
while self.fm!='txt' and self.fm!='json' and self.fm!='csv':
self.fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
if self.fm=='txt' :
self.fd = open('Jd.txt','w',encoding='utf-8')
elif self.fm=='json' :
self.fd = open('Jd.json','w',encoding='utf-8')
elif self.fm=='csv' :
self.fd = open('Jd.csv','w',encoding='utf-8',newline='')
def open_browser(self):
self.browser = webdriver.Chrome()
self.browser.implicitly_wait(10)
self.wait = WebDriverWait(self.browser,10)
def init_variable(self):
self.data = zip()
self.isLast = False
def parse_page(self):
try:
skus = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//li[@class="gl-item"]')))
skus = [item.get_attribute('data-sku') for item in skus]
links = ['https://item.jd.com/{sku}.html'.format(sku=item) for item in skus]
prices = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[2]/strong/i')))
prices = [item.text for item in prices]
names = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[3]/a/em')))
names = [item.text for item in names]
comments = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[4]/strong')))
comments = [item.text for item in comments]
self.data = zip(links,prices,names,comments)
except selenium.common.exceptions.TimeoutException:
print('parse_page: TimeoutException')
self.parse_page()
except selenium.common.exceptions.StaleElementReferenceException:
print('parse_page: StaleElementReferenceException')
self.browser.refresh()
def turn_page(self):
try:
self.wait.until(EC.element_to_be_clickable((By.XPATH,'//a[@class="pn-next"]'))).click()
time.sleep(1)
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
except selenium.common.exceptions.NoSuchElementException:
self.isLast = True
except selenium.common.exceptions.TimeoutException:
print('turn_page: TimeoutException')
self.turn_page()
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException')
self.browser.refresh()
def write_to_file(self):
if self.fm == 'txt':
for item in self.data:
self.fd.write('----------------------------------------\n')
self.fd.write('link:' + str(item[0]) + '\n')
self.fd.write('price:' + str(item[1]) + '\n')
self.fd.write('name:' + str(item[2]) + '\n')
self.fd.write('comment:' + str(item[3]) + '\n')
if self.fm == 'json':
temp = ('link','price','name','comment')
for item in self.data:
json.dump(dict(zip(temp,item)),self.fd,ensure_ascii=False)
if self.fm == 'csv':
writer = csv.writer(self.fd)
for item in self.data:
writer.writerow(item)
def close_file(self):
self.fd.close()
def close_browser(self):
self.browser.quit()
def crawl(self):
self.open_file()
self.open_browser()
self.init_variable()
print('开始爬取')
self.browser.get('https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8')
time.sleep(1)
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
count = 0
while not self.isLast:
count += 1
print('正在爬取第 ' + str(count) + ' 页......')
self.parse_page()
self.write_to_file()
self.turn_page()
self.close_file()
self.close_browser()
print('结束爬取')
if __name__ == '__main__':
spider = JdSpider()
spider.crawl()
代码中有几个需要注意的地方,现在记录下来便于以后学习:
1、self.fd = open('Jd.csv','w',encoding='utf-8',newline='')
在打开 csv 文件时,最好加上参数 newline='' ,否则我们写入的文件会出现空行,不利于后续的数据处理
2、self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
在模拟浏览器向下拖动网页时,由于数据更新不及时,所以经常出现 StaleElementReferenceException 异常
一般来说有两种处理方法:
- 在完成操作后使用
time.sleep()给浏览器充足的加载时间 - 捕获该异常进行相应的处理
3、skus = [item.get_attribute('data-sku') for item in skus]
在 selenium 中使用 xpath 语法选取元素时,无法直接获取节点的属性值,而需要使用 get_attribute() 方法
4、无头启动浏览器可以加快爬取速度,只需在启动浏览器时设置无头参数即可
opt = webdriver.chrome.options.Options()
opt.set_headless()
browser = webdriver.Chrome(chrome_options=opt)
【爬虫系列相关文章】
爬虫系列(十三) 用selenium爬取京东商品的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
随机推荐
- Bag标签之删除书包中的一条数据
删除书包中的一条数据 查询 <esql module=help id=list> Select ID,Subject,Writer,DayTime From Messages </e ...
- 在NSUserDefaults中保存自己定义的对象
在iOS开发中.须要用到一些回调值(从A到B,从B返回时把B中的值带回A中).事实上方法也非常多(delegate,block.nsuserdefaults等).我想用NSUserDefaults回调 ...
- Color a Tree HDU - 6241
/* 十分巧妙的二分 题意选最少的点涂色 使得满足输入信息: 1 x的子树涂色数不少于y 2 x的子树外面涂色数不少于y 我们若是把2转化到子树内最多涂色多少 就可以维护这个最小和最大 如果我们二分出 ...
- Linux gadget驱动分析1------驱动加载过程
为了解决一个问题,简单看了一遍linux gadget驱动的加载流程.做一下记录. 使用的内核为linux 2.6.35 硬件为芯唐NUC950. gadget是在UDC驱动上面的一层,如果要编写ga ...
- stack 栈
其实今天我们主要讲的是搜索,但是留作业不知道怎么就突然全变成栈了. 其实栈和队列没什么区别,只是一个先进先出,一个先进后出.基本操作也是一样的. 栈(stack)又名堆栈,它是一种运算受限的线性表.其 ...
- tp 推送微信的模板消息
设置推送类: <?php /** * tpshop 微信支付插件 * ============================================================== ...
- CSS3 中弹性盒模型--容器的属性
1.display : flex | inline-flex注意,设为 Flex 布局以后,子元素的float.clear和vertical-align属性 将失效. 2.flex-direction ...
- .Net Core中使用Quartz.Net Vue开即用的UI管理
Quartz.NET Quartz.Net 定制UI维护了常用作业添加.删除.修改.停止.启动功能,直接使用cron表达式设置作业执行间隔,有完整的日志记录. Quartz.NET是一个功能齐全的开源 ...
- 2019手机号码JS正则表达式
前端的正则表达式验证往往是最繁多最复杂的,所以整理了一些最近自己常用的正则表达式,希望能对大家有所帮助! /* 合法uri */ export function validateURL(textval ...
- Cloudera Manager安装之利用parcels方式(在线或离线)安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubuntu14.04)(四)
.. 欢迎大家,加入我的微信公众号:大数据躺过的坑 免费给分享 同时,大家可以关注我的个人博客: http://www.cnblogs.com/zlslch/ 和 http ...