排序算法C语言实现
大学有一门课程叫做数据结构,严蔚敏的课本,其中详细介绍了集中经典的排序算法,学习复习反复几次,但是直到现在仍然只记得名字了,所以想记录下来,随时复习直至牢记于心。经常面试的朋友知道,排序算法在面试中出现的频率很高,尤其是开发、算法等岗位,因为排序算法是算法的入门知识。排序算法的思想可以灵活应用到实际的开发中解决问题。
排序算法有哪几种
- 交换排序
- 1.冒泡排序
- 2.快速排序
- 插入排序
- 1.直接插入排序
- 2.希尔(shell)排序
- 选择排序
- 1.直接选择排序
- 2.堆(Heap)排序
- 归并排序
一、交换排序
交换排序的基本思想都是通过比较两个数的大小,当满足某些条件时对它进行交换从而达到排序的目的。
1.冒泡排序
基本思想:比较相邻的两个数,如果前者比后者大,则进行交换。每一轮排序结束,选出一个未排序中最大的数放到数组后面。
#include<stdio.h>
#include<assert.h>
#include<stdlib.h> /*从头到尾,大的向后冒*/
void BubbleSort1(int *arr,int n){
int i,j;
assert(arr);
for(i=;i<n-;i++){
for(j=;j<n-i-;j++){
if(arr[j]>arr[j+]){
int tmp=arr[j];
arr[j]=arr[j+];
arr[j+]=tmp;
}
}
}
}
/*从尾到头,大的往前冒*/
void BubbleSort2(int *arr,int n){
int i,j;
assert(arr);
for(i=;i<n-;i++){
for(j=n-;j>i;j--){
if(arr[j]>arr[j-]){
int tmp=arr[j];
arr[j]=arr[j-];
arr[j-]=tmp;
}
}
}
} /*参数设置成函数指针的测试函数*/
void test(void (*Bubble)(int *arr,int n)){
int arr[]={,,,,,,,,,};
int i=;
int n=sizeof(arr)/sizeof(arr[]);
Bubble(arr,n);
for(i=;i<n;i++){
printf("%d",arr[i]);
}
printf("\n");
}
/*主函数*/
int main(){
test(BubbleSort1);
test(BubbleSort2);
return ;
}
最差时间复杂度为O(n^2),平均时间复杂度为O(n^2)。稳定性:稳定。辅助空间O(1)。
升级版冒泡排序法:通过从低到高选出最大的数放到后面,再从高到低选出最小的数放到前面,如此反复,直到左边界和右边界重合。当数组中有已排序好的数时,这种排序比传统冒泡排序性能稍好。
#include<stdio.h>
//升级版冒泡排序算法
void bubbleSort_1(int *arr, int n) {
//设置数组左右边界
int left = , right = n - ;
//当左右边界未重合时,进行排序
while (left<right) {
//从左到右遍历选出最大的数放到数组右边
for (int i =left; i < right; i++)
{
if (arr[i] > arr[i + ])
{
int temp = arr[i]; arr[i] = arr[i + ]; arr[i + ] = temp;
}
}
right--;
//从右到左遍历选出最小的数放到数组左边
for (int j = right;j> left; j--)
{
if (arr[j + ] < arr[j])
{
int temp = arr[j]; arr[j] = arr[j + ]; arr[j + ] = temp;
}
}
left++;
} }
int main() {
int arr[] = { ,,,,,,,,, };
int n = sizeof(arr) / sizeof(int);
bubbleSort_1(arr, n);
printf("排序后的数组为:\n");
for (int j = ; j<n; j++)
printf("%d ", arr[j]);
printf("\n");
return ;
}
2.快速排序
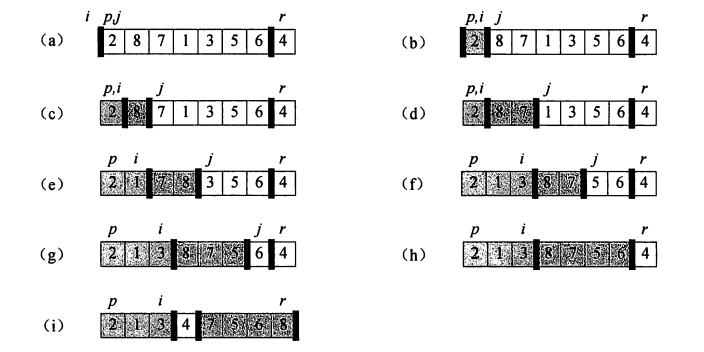
基本思想:选取一个基准元素,通常为数组最后一个元素(或者第一个元素)。从前向后遍历数组,当遇到小于基准元素的元素时,把它和左边第一个大于基准元素的元素进行交换。在利用分治策略从已经分好的两组中分别进行以上步骤,直到排序完成。下图表示了这个过程。
#include<stdio.h>
void swap(int *x, int *y) {
int tmp = *x;
*x = *y;
*y = tmp;
}
//分治法把数组分成两份
int patition(int *a, int left,int right) {
int j = left; //用来遍历数组
int i = j - ; //用来指向小于基准元素的位置
int key = a[right]; //基准元素
//从左到右遍历数组,把小于等于基准元素的放到左边,大于基准元素的放到右边
for (; j < right; ++j) {
if (a[j] <= key)
swap(&a[j], &a[++i]);
}
//把基准元素放到中间
swap(&a[right], &a[++i]);
//返回数组中间位置
return i;
}
//快速排序
void quickSort(int *a,int left,int right) {
if (left>=right)
return;
int mid = patition(a,left,right);
quickSort(a, left, mid - );
quickSort(a, mid + , right);
}
int main() {
int a[] = { ,,,,,,,,,,,,,,, };
int n = sizeof(a) / sizeof(int);
quickSort(a, ,n-);
printf("排序好的数组为:");
for (int l = ; l < n; l++) {
printf("%d ", a[l]);
}
printf("\n");
return ;
}
最差时间复杂度:每次选取的基准元素都为最大(或最小元素)导致每次只划分了一个分区,需要进行n-1次划分才能结束递归,故复杂度为O(n^2);最优时间复杂度:每次选取的基准元素都是中位数,每次都划分出两个分区,需要进行logn次递归,故时间复杂度为O(nlogn);平均时间复杂度:O(nlogn)。稳定性:不稳定的。辅助空间:O(nlogn)。
当数组元素基本有序时,快速排序将没有任何优势,基本退化为冒泡排序,可在选取基准元素时选取中间值进行优化。
二、插入排序
1.直接插入排序
基本思想:和交换排序不同的是它不用进行交换操作,而是用一个临时变量存储当前值。当前面的元素比后面大时,先把后面的元素存入临时变量,前面元素的值放到后面元素位置,再到最后把其值插入到合适的数组位置。
#include<stdio.h>
void InsertSort(int *a, int n) {
int tmp = ;
for (int i = ; i < n; i++) {
int j = i - ;
if (a[i] < a[j]) {
tmp = a[i];
a[i] = a[j];
while (tmp < a[j-]) {
a[j] = a[j-];
j--;
}
a[j] = tmp;
}
}
}
int main() {
int a[] = { ,,,,,,,,,,};
int n = sizeof(a)/sizeof(int);
InsertSort(a, n);
printf("排序好的数组为:");
for (int i = ; i < n; i++) {
printf(" %d", a[i]);
}
printf("\n");
return ;
}
最坏时间复杂度为数组为逆序时,为O(n^2)。最优时间复杂度为数组正序时,为O(n)。平均时间复杂度为O(n^2)。辅助空间O(1)。稳定性:稳定。
2.希尔(shell)排序
基本思想为在直接插入排序的思想下设置一个最小增量dk,刚开始dk设置为n/2。进行插入排序,随后再让dk=dk/2,再进行插入排序,直到dk为1时完成最后一次插入排序,此时数组完成排序。
#include<stdio.h>
// 进行插入排序
// 初始时从dk开始增长,每次比较步长为dk
void Insrtsort(int *a, int n,int dk) {
for (int i = dk; i < n; ++i) {
int j = i - dk;
if (a[i] < a[j]) { // 比较前后数字大小
int tmp = a[i]; // 作为临时存储
a[i] = a[j];
while (a[j] > tmp) { // 寻找tmp的插入位置
a[j+dk] = a[j];
j -= dk;
}
a[j+dk] = tmp; // 插入tmp
}
}
} void ShellSort(int *a, int n) {
int dk = n / ; // 设置初始dk
while (dk >= ) {
Insrtsort(a, n, dk);
dk /= ;
}
} int main() {
int a[] = { ,,,,,,,,,, };
int n = sizeof(a) / sizeof(int);
ShellSort(a, n);
printf("排序好的数组为:");
for (int j = ; j < n; j++) {
printf("%d ", a [j]);
}
return ;
}
最坏时间复杂度为O(n^2);最优时间复杂度为O(n);平均时间复杂度为O(n^1.3)。辅助空间O(1)。稳定性:不稳定。希尔排序的时间复杂度与选取的增量有关,选取合适的增量可减少时间复杂度。
三、选择排序
1.直接选择排序
基本思想:依次选出数组最小的数放到数组的前面。首先从数组的第二个元素开始往后遍历,找出最小的数放到第一个位置。再从剩下数组中找出最小的数放到第二个位置。以此类推,直到数组有序。
#include<stdio.h>
void SelectSort(int *a, int n) {
for (int i = ; i < n; i++)
{
int key = i; // 临时变量用于存放数组最小值的位置
for (int j = i + ; j < n; j++) {
if (a[j] < a[key]) {
key = j; // 记录数组最小值位置
}
}
if (key != i)
{
int tmp = a[key]; a[key] = a[i]; a[i] = tmp; // 交换最小值
} }
}
int main() {
int a[] = { ,,,,,,,,,,,, };
int n = sizeof(a) / sizeof(int);
SelectSort(a, n);
printf("排序好的数组为: ");
for (int k = ; k < n; k++)
printf("%d ", a[k]);
printf("\n");
return ;
}
最差、最优、平均时间复杂度都为O(n^2)。辅助空间为O(1)。稳定性:不稳定。
2.堆(Heap)排序
基本思想:先把数组构造成一个大顶堆(父亲节点大于其子节点),然后把堆顶(数组最大值,数组第一个元素)和数组最后一个元素交换,这样就把最大值放到了数组最后边。把数组长度n-1,再进行构造堆,把剩余的第二大值放到堆顶,输出堆顶(放到剩余未排序数组最后面)。依次类推,直至数组排序完成。
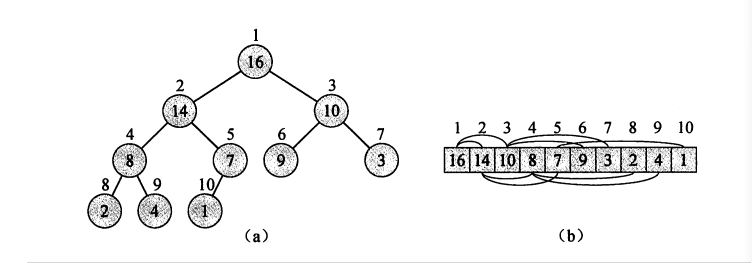
下图为堆结构及其在数组中的表示。可以知道堆顶的元素为数组的首元素,某一个节点的左孩子节点为其在数组中的位置*2,其右孩子节点为其在数组中的位置*2+1,其父节点为其在数组中的位置/2(假设数组从1开始计数)。
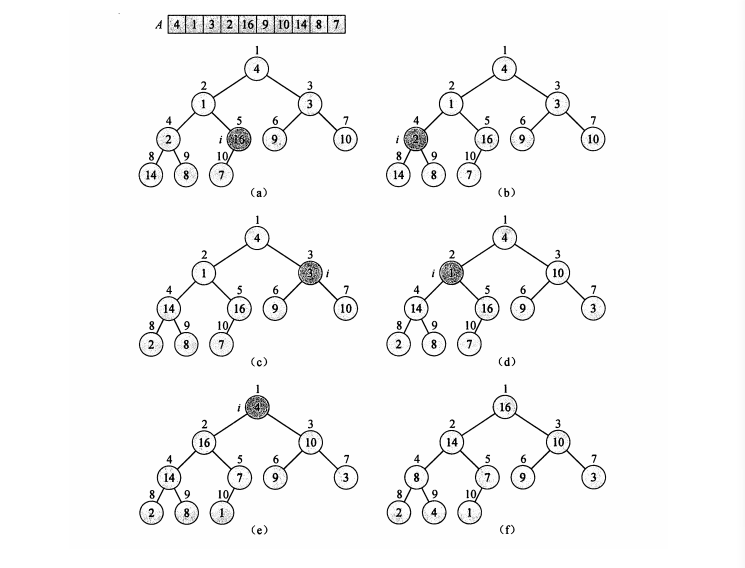
下图为怎么把一个无序的数组构造成一个大堆顶结构的数组的过程,注意其是从下到上,从右到左,从右边第一个非叶子节点开始构建的。
#include<stdio.h> // 创建大堆顶,i为当节点,n为堆的大小
// 从第一个非叶子结点i从下至上,从右至左调整结构
// 从两个儿子节点中选出较大的来与父亲节点进行比较
// 如果儿子节点比父亲节点大,则进行交换
void CreatHeap(int a[], int i, int n) { // 注意数组是从0开始计数,所以左节点为2*i+1,右节点为2*i+2
for (; i >= ; --i)
{
int left = i * + ; //左子树节点
int right = i * + ; //右子树节点
int j = ;
//选出左右子节点中最大的
if (right < n) {
a[left] > a[right] ? j= left : j = right;
}
else
j = left;
//交换子节点与父节点
if (a[j] > a[i]) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
} // 进行堆排序,依次选出最大值放到最后面
void HeapSort(int a[], int n) {
//初始化构造堆
CreatHeap(a, n/-, n);
//交换第一个元素和最后一个元素后,堆的大小减1
for (int j = n-; j >= ; j--) { //最后一个元素和第一个元素进行交换
int tmp = a[];
a[] = a[j];
a[j] = tmp; int i = j / - ;
CreatHeap(a, i, j);
}
}
int main() {
int a[] = { ,,,,,,,,,,,,,,, };
int n = sizeof(a) / sizeof(int);
HeapSort(a, n);
printf("排序好的数组为:");
for (int l = ; l < n; l++) {
printf("%d ", a[l]);
}
printf("\n");
return ;
}
最差、最优‘平均时间复杂度都为O(nlogn),其中堆的每次创建重构花费O(lgn),需要创建n次。辅助空间O(1)。稳定性:不稳定。
四.归并排序
基本思想:归并算法应用到分治策略,简单说就是把一个答问题分解成易于解决的小问题后一个个解决,最后在把小问题的一步步合并成总问题的解。这里的排序应用递归来把数组分解成一个个小数组,直到小数组的数位有序,在把有序的小数组两两合并而成有序的大数组。
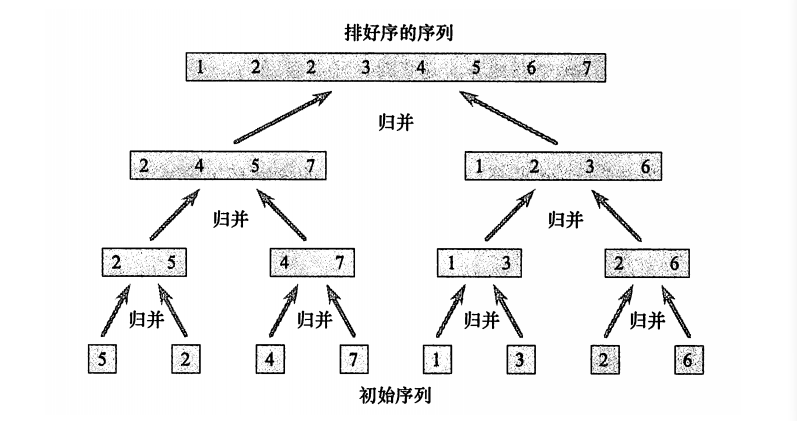
下图为展示如何归并的合成一个数组。
下图展示了归并排序过程各阶段的时间花费。
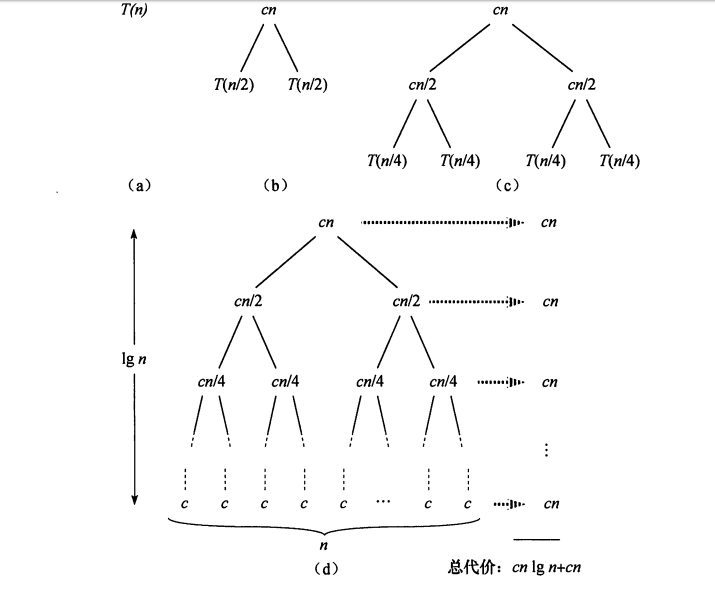
#include <stdio.h>
#include <limits.h> // 合并两个已排好序的数组
void Merge(int a[], int left, int mid, int right)
{
int len = right - left + ; // 数组的长度
int *temp = new int[len]; // 分配个临时数组
int k = ;
int i = left; // 前一数组的起始元素
int j = mid + ; // 后一数组的起始元素
while (i <= mid && j <= right)
{
// 选择较小的存入临时数组
temp[k++] = a[i] <= a[j] ? a[i++] : a[j++];
}
while (i <= mid)
{
temp[k++] = a[i++];
}
while (j <= right)
{
temp[k++] = a[j++];
}
for (int k = ; k < len; k++)
{
a[left++] = temp[k];
}
} // 递归实现的归并排序
void MergeSort(int a[], int left, int right)
{
if (left == right)
return;
int mid = (left + right) / ;
MergeSort(a, left, mid);
MergeSort(a, mid + , right);
Merge(a, left, mid, right);
} int main() {
int a[] = { ,,,,,,,,,, };
int n = sizeof(a) / sizeof(int);
MergeSort(a, , n - );
printf("排序好的数组为:");
for (int k = ; k < n; ++k)
printf("%d ", a[k]);
printf("\n");
return ;
}
最差、最优、平均时间复杂度都为O(nlogn),其中递归树共有lgn+1层,每层需要花费O(n)。辅助空间O(n)。稳定性:稳定。
注:参考于:!Vincent的博客和https://www.cnblogs.com/qq329914874/p/6002297.html
排序算法C语言实现的更多相关文章
- 快色排序算法(C语言描述)
快速排序 算法思想 快速排序采用了一种分治策略,学术上称之为分治法(Divide-and-Conquer Method). 哨兵(如下算法中的key) 每趟排序将哨兵插入到数组的合适位置,使得哨兵左侧 ...
- 排序算法c语言描述---堆排序
排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析. 文章规划: 一.通过自己对排序算法本身的理解,对每个方法写个小测试程序.具体思路分析不 ...
- 各种排序算法(C语言)
#include <stdlib.h> #include <stdio.h> void DataSwap(int* data1, int* data2) { int temp ...
- 排序算法c语言描述---冒泡排序
排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析. 文章规划: 一.通过自己对排序算法本身的理解,对每个方法写个小测试程序. 具体思路分析 ...
- 排序算法c语言描述---选择排序
排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析. 文章规划: 一.通过自己对排序算法本身的理解,对每个方法写个小测试程序. 具体思路分析 ...
- 【转】九大排序算法-C语言实现及详解
概述 排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存. 我们这里说说八大排序就是内部排序. 当n较大, ...
- 排序算法C语言实现——冒泡、快排、堆排对比
对冒泡.快排.堆排这3个算法做了验证,结果分析如下: 一.结果分析 时间消耗:快排 < 堆排 < 冒泡. 空间消耗:冒泡O(1) = 堆排O(1) < 快排O(logn)~O(n) ...
- 排序算法(Apex 语言)
/* Code function : 冒泡排序算法 冒泡排序的优点:每进行一趟排序,就会少比较一次,因为每进行一趟排序都会找出一个较大值 时间复杂度:O(n*n) 空间复杂度:1 */ List< ...
- 史上最全单链表的增删改查反转等操作汇总以及5种排序算法(C语言)
目录 1.准备工作 2.创建链表 3.打印链表 4.在元素后面插入元素 5.在元素前面增加元素 6.删除链表元素,要注意删除链表尾还是链表头 7.根据传入的数值查询链表 8.修改链表元素 9.求链表长 ...
随机推荐
- .NET 下的 POP3 编程代码共享
前一段时间在论坛上看见有人问如何使用.net进行POP3编程,其实POP3的使用很简单,所以.net没有向SMTP那样给出相应的类来控制. 废话少说,程序员最需要的使代码. 1.打开VS.NET 20 ...
- Hibernate Annotation (…
引自:http://www.cnblogs.com/hongten/archive/2011/07/20/2111773.html 进入:http://www.hibernate.org 说明文档: ...
- Python 在windows上安装BeautifulSoup和request以及小案例
Python以及PyCharm安装成功后,操作如下: 此时,代码import requests不报错了. 那么,Python 在windows上安装BeautifulSoup,怎么操作呢? 1. 打开 ...
- Google Analytics添加到网站
把Google Analytics添加到网站的具体方式 https://developers.google.com/analytics/devguides/collection/analyticsjs ...
- POJ - 2533 Longest Ordered Subsequence与HDU - 1257 最少拦截系统 DP+贪心(最长上升子序列及最少序列个数)(LIS)
Longest Ordered Subsequence A numeric sequence of ai is ordered if a1 < a2 < ... < aN. Let ...
- cogs 1901. [国家集训队2011]数颜色
Cogs 1901. [国家集训队2011]数颜色 ★★★ 输入文件:nt2011_color.in 输出文件:nt2011_color.out 简单对比时间限制:0.6 s 内存限制 ...
- css中多余文字省略号显示
项目中很多情况都要求多余的文字要以省略号的形式展示在前端页面上.虽然用的多,但是我也不知道为啥,我始终记不住.所以,通过这种方式,让自己加深一下印象 情况一:单行文字超出规定宽度后,以省略号形式展示 ...
- IT兄弟连 Java语法教程 运行Java程序
编译好Java字节码文件后,接下来就应该运行Java程序了. 运行Java程序需要使用JDK中提供的java命令,因为已经把java命令所在的路径添加到了系统的Path环境变量中,因此现在可以直接使用 ...
- python 扩展注册功能装饰器举例
db_path='db.txt'def get_uname(): while True: uname=input('请输入用户名:').strip() if uname.isalpha(): with ...
- thinkphp5.1静态文件存放问题
5.1的版本不能将静态文件放在application目录下,只能放在public目录下,否则会拒绝访问