tensorflow目标检测API之建立自己的数据集
1 收集数据
为了方便,我找了11张月儿的照片做数据集,如图1,当然这在实际应用过程中是远远不够的
2 labelImg软件的安装
使用labelImg软件(下载地址:https://github.com/tzutalin/labelImg)为图片做标签
下载下来之后解压缩,用Anaconda Prompt cd到解压缩后的labelImg文件目录下,例如 cd C:\Users\admin\Desktop\labelImg-master
然后安装pyqt,输入命令 conda install pyqt=5(注意:一定要使用管理员方式运行命令)
完成后输入命令 pyrcc5 -o resources.py resources.qrc,这个命令没有返回
最后执行 python labelImg.py,如果提示缺少包则安装就行
运行结果如图2
3 labelImg软件的使用
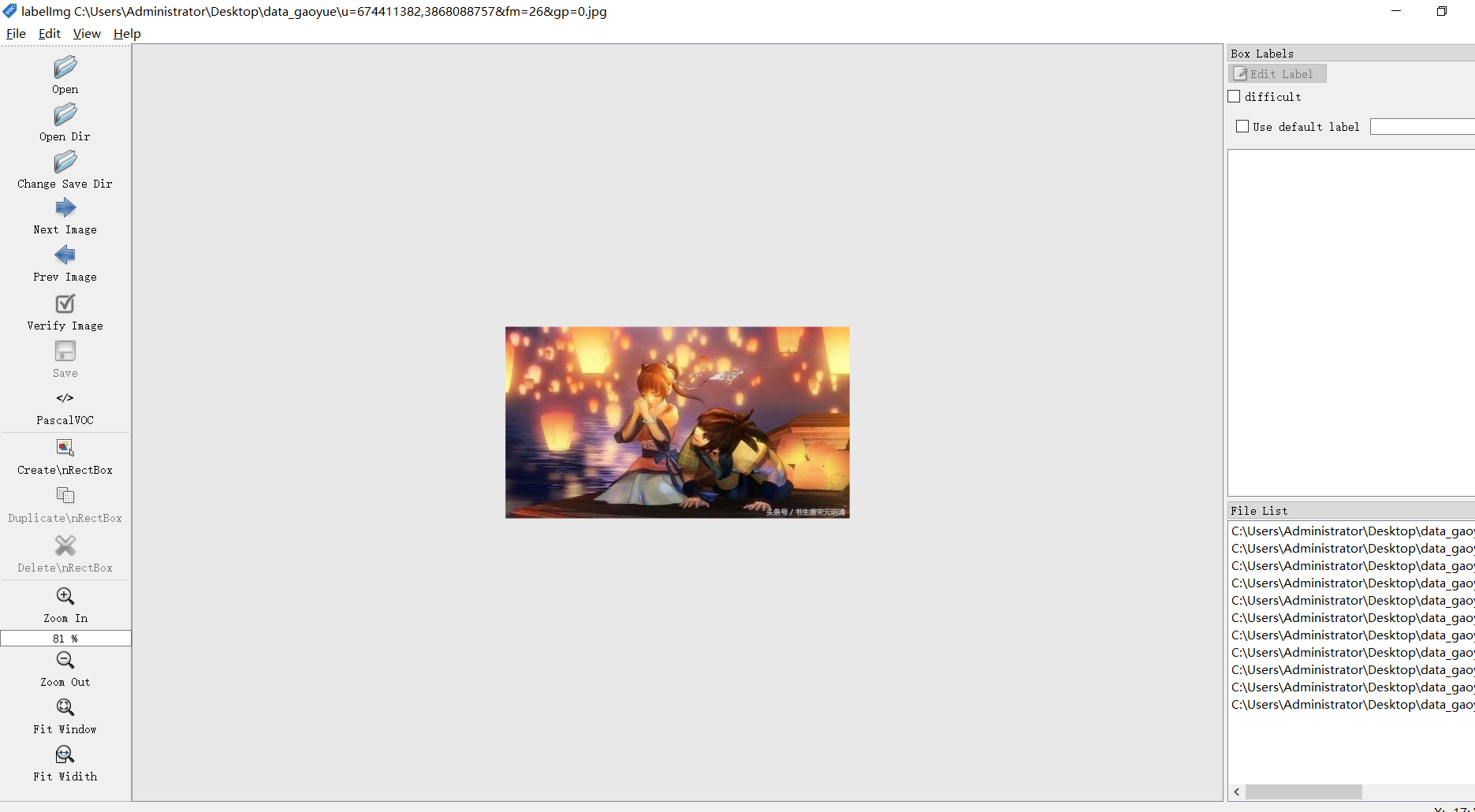
点击Open Dir打开数据集所在的文件夹,将图片导入。如图3所示。
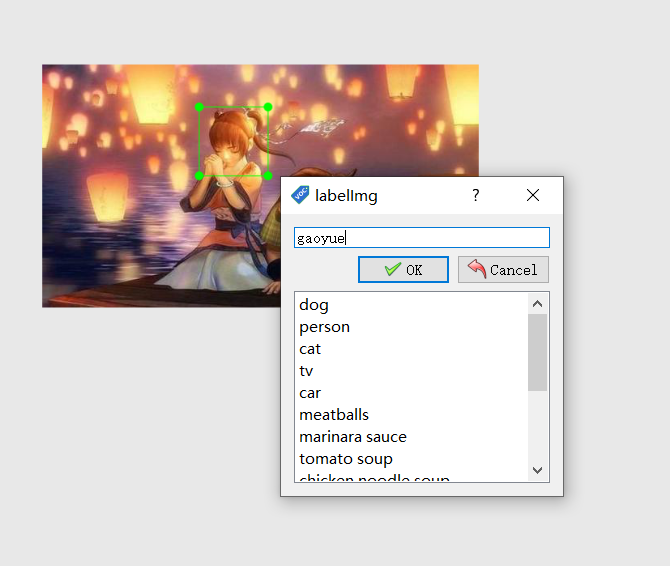
在界面中按下w键,选择你的目标,然后在弹出的框中为你的目标确定一个名字。如图4
标记完之后每张图片都有一个对应的xml文件,如图5所示
4 标签文件的格式转换(一定要将这一步中的代码放在object_detection文件夹下)
(1)xml转csv
代码(xml_to_csv.py)
# -*- coding: utf-8 -*- import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET os.chdir('C:/Code/models-master/research/object_detection/my_train_images/train') # 这个是我文件夹的目录,改成你自己的
path = 'C:/Code/models-master/research/object_detection/my_train_images/train' # 训练图片的路径,改成你自己的 def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df def main():
image_path = path
xml_df = xml_to_csv(image_path)
xml_df.to_csv('gaoyue_train.csv', index=None) # 输出xsv文件的名字,改成你自己的
print('Successfully converted xml to csv.') main()
运行之后可以看到train文件夹下多了一个gaoyue.csv文件,重复上面的代码,更改文件夹,将test数据也生成一个.csv文件。

(2)csv转tfrecord
代码(csv_to_tfrecord.py)
# -*- coding: utf-8 -*- """
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/tv_vehicle_labels.csv --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
""" import os
import io
import pandas as pd
import tensorflow as tf from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict os.chdir('C:/Code/models-master/research/object_detection') # 当前工作目录 flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS # TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'gaoyue':
return 1
# elif row_label == 'vehicle':
# return 2
else:
return 0 def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = [] for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
# path = os.path.join(os.getcwd(), 'images/train')
path = os.path.join(os.getcwd(), 'my_train_images/train') # 当前路径加上你图片存放的路径
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString()) writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path)) if __name__ == '__main__':
tf.app.run()
然后打开Anaconda Prompt cd到你csv_to_tfrecord.py文件所在的地方
输入命令
python csv_to_tfrecord.py --csv_input=my_train_images/test/gaoyue_test.csv --output_path=gaoyue_train.record (csv_to_tfrecord.py为转换的代码文件,csv_input是你要转换的csv文件所在的路径,output_path是你输出tfrecord文件的路径)
运行结果如图所示

生成 gaoyue_train.csv文件

tensorflow目标检测API之建立自己的数据集的更多相关文章
- tensorflow目标检测API之训练自己的数据集
1.训练文件的配置 将生成的csv和record文件都放在新建的mydata文件夹下,并打开object_detection文件夹下的data文件夹,复制一个后缀为.pbtxt的文件到mtdata文件 ...
- tensorflow目标检测API安装及测试
1.环境安装配置 1.1 安装tensorflow 安装tensorflow不再仔细说明,但是版本一定要是1.9 1.2 下载Tensorflow object detection API 下载地址 ...
- tensorflow2.4与目标检测API在3060显卡上的配置安装
目前,由于3060显卡驱动版本默认>11.0,因此,其不能使用tensorflow1版本的任何接口,所以学习在tf2版本下的目标检测驱动是很有必要的,此配置过程同样适用于任何30系显卡配置tf2 ...
- TensorFlow目标检测(object_detection)api使用
https://github.com/tensorflow/models/tree/master/research/object_detection 深度学习目标检测模型全面综述:Faster R-C ...
- 目标检测:keras-yolo3之制作VOC数据集训练指南
制作VOC数据集指南 Github:https://github.com/hyhouyong/keras-yolo3 LabelImg标注工具(windows环境下):https://github.c ...
- TensorFlow object detection API应用
前一篇讲述了TensorFlow object detection API的安装与配置,现在我们尝试用这个API搭建自己的目标检测模型. 一.准备数据集 本篇旨在人脸识别,在百度图片上下载了120张张 ...
- TensorFlow object detection API应用--配置
目标检测在图形识别的基础上有了更进一步的应用,但是代码也更加繁琐,TensorFlow专门为此开设了一个object detection API,接下来看看怎么使用它. object detectio ...
- TensorFlow Object Detection API中的Faster R-CNN /SSD模型参数调整
关于TensorFlow Object Detection API配置,可以参考之前的文章https://becominghuman.ai/tensorflow-object-detection-ap ...
- 10分钟内基于gpu的目标检测
10分钟内基于gpu的目标检测 Object Detection on GPUs in 10 Minutes 目标检测仍然是自动驾驶和智能视频分析等应用的主要驱动力.目标检测应用程序需要使用大量数据集 ...
随机推荐
- Codeforces Round #562 (Div. 2) B. Pairs
链接:https://codeforces.com/contest/1169/problem/B 题意: Toad Ivan has mm pairs of integers, each intege ...
- spring基础概念AOP与动态代理理解
一.代理模式 代理模式的英文叫做Proxy或Surrogate,中文都可译为”代理“,所谓代理,就是一个人或者一个机构代表另一个人或者另一个机构采取行动.在一些情况下,一个客户不想或者不能够直接引用一 ...
- 071 Simplify Path 简化路径
给定一个文档 (Unix-style) 的完全路径,请进行路径简化.例如,path = "/home/", => "/home"path = " ...
- 洛谷P1965 转圈游戏
https://www.luogu.org/problem/show?pid=1965 快速幂 #include<iostream> #include<cstdio> #inc ...
- VS连接Access数据库--连接字符串及执行查询语句的方法(增删改查,用户名查重,根据用户获取密码查询)
ACCESS数据的连接及语句执行操作,不难,久不用会生疏,每次都要找资料,干脆自己整理下,记录下来,需要的时候,直接查看,提高效率.也供初学者参考 1.连接字符串 public static stri ...
- c# ExpandoObject动态扩展对象
js中的Object 对象. php中的stdClass. c# 也有动态可扩展对象 ExpandoObject,需要添加System.Dynamic引用 用法: dynamic model = ne ...
- Kendo MVVM (二) ObservableObject 对象
概述 Kendo MVVM 框架关键的一个部分为 ViewModel,它主要是通过 kendo.data.ObserableObject 来提供支持的.它可以监控改变( UI 变化或是值的变化)并通知 ...
- 【简问】一些个人不会的问题,收到解答经核实OK的会在下方附注答案
1.p标签内放行内块(如,input)适宜么(已知p是块元素,但p内不宜放置div)? 2.如何单独设置文字下划线颜色? 3.行内元素可以定位吗? 4.支持 margin:0 auto; 的元素类型有 ...
- mui页面间传接值例子
传值页面index.html <!DOCTYPE html><html><head> <meta charset="utf-8"> ...
- IOS制作纯色背景
// 生成纯色背景图- (UIImage *)createPureColorImageWithColor:(UIColor *)color alpha:(CGFloat)alpha size:(CGS ...