Sklearn (一) 监督学习
本系列博文是根据SKlearn的一个学习小结,并非原创!
1.直接学习TensorFlow有点不知所措,感觉需要一些基础知识做铺垫。
2.之前机器学习都是理论《Ng机器学习基础》+底层编写《机器学习实战》,现实生活基本用不到。
3.会增加一些个人总结,也会删除一些以前学过的知识。
|
广义线性模型 |
1.1 普通最小二乘法
然而,对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵  的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
Example:
SK的数据集介绍:https://blog.csdn.net/sa14023053/article/details/52086695,暂时用不到那么多,用到什么看什么吧!
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
'''
这是一个糖尿病的数据集,
主要包括442行数据,10个属性值
分别是:Age(年龄)、
性别(Sex)、
Body mass index(体质指数)、
Average Blood Pressure(平均血压)、
S1~S6一年后疾病级数指标。
Target为一年后患疾病的定量指标。
'''
diabetes = datasets.load_diabetes()
# 取其中的一个数据进行试验
# https://blog.csdn.net/lanchunhui/article/details/49725065,
# np.newaxis的含义和分析,其中也可以写作下面的形式:
# diabetes.data[:,2][:,np.newaxis] 或者 diabetes.data[:,2][:,None]
# 目的为了增加一个轴
diabetes_X = diabetes.data[:, np.newaxis, 2] #(442,10)
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients,打印权重
print('Coefficients: \n', regr.coef_)
# The mean squared error,损失函数
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
#plt.xticks()/plt.yticks()设置轴记号
#现在是明白干嘛用的了,就是人为设置坐标轴的刻度显示的值
'''
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\pi/2$', r'$0$', r'$+\pi/2$', r'$+\pi$'])
plt.yticks([-1, 0, +1],
[r'$-1$', r'$0$', r'$+1$'])
'''
#plt.xticks(())
#plt.yticks(())
plt.show()
1.2 岭回归
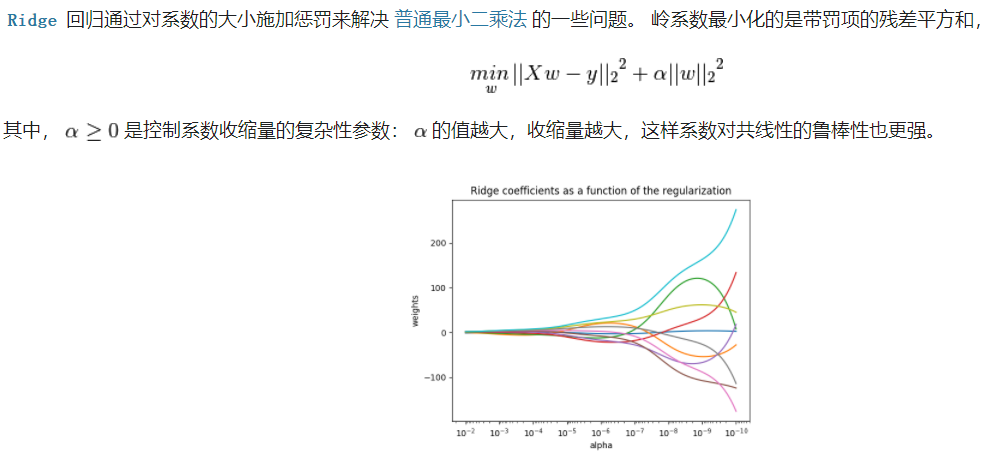
注释:就是加了一个惩罚项,防止过拟合~~
Exanple和简单线性回归一样的表达~~
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge (alpha = .5)
>>> reg.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
>>> reg.coef_
array([ 0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...
1.3 贝叶斯岭回归
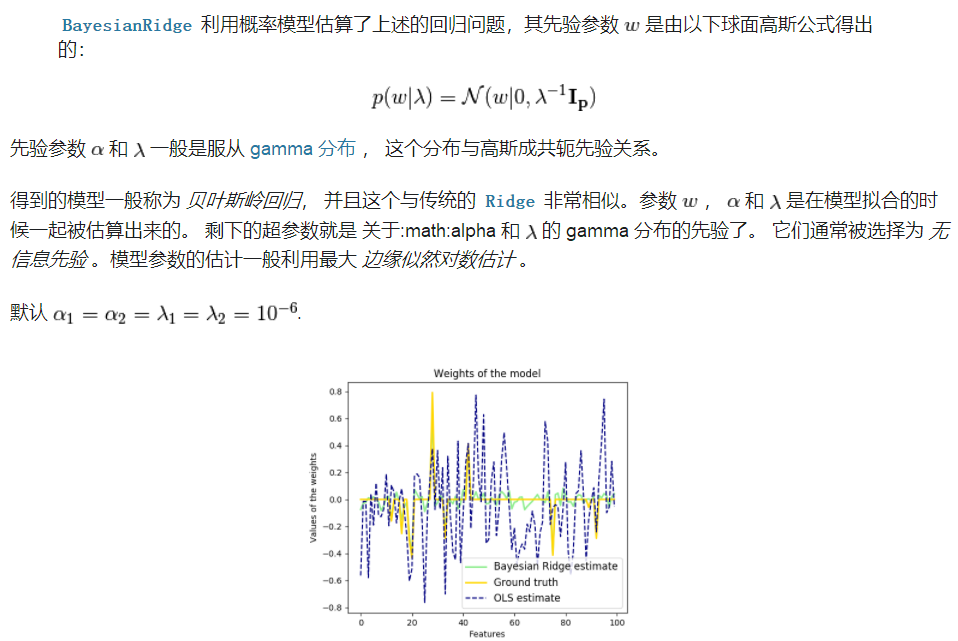
训练数据:
>>> from sklearn import linear_model
>>> X = [[0., 0.], [1., 1.], [2., 2.], [3., 3.]]
>>> Y = [0., 1., 2., 3.]
>>> reg = linear_model.BayesianRidge()
>>> reg.fit(X, Y)
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,
normalize=False, tol=0.001, verbose=False)
预测数据:
>>> reg.predict ([[1, 0.]]) array([ 0.50000013])
查看权重:
>>> reg.coef_ array([ 0.49999993, 0.49999993])
参考:
http://sklearn.apachecn.org/cn/0.19.0/modules/linear_model.html
https://blog.csdn.net/eastmount/article/details/52929765
http://cwiki.apachecn.org/pages/viewpage.action?pageId=10814293
http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge
Sklearn (一) 监督学习的更多相关文章
- sklearn半监督学习
标签: 半监督学习 作者:炼己者 欢迎大家访问 我的简书 以及 我的博客 本博客所有内容以学习.研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢! --- 摘要:半监督学习 ...
- 关于sklearn,监督学习几种模型的对比
# K近邻,适用于小型数据集,是很好的基准模型,容易解释 from sklearn.neighbors import KNeighborsClassifier # 线性模型,非常可靠的首选算法,适用于 ...
- sklearn算法库的顶层设计
sklearn监督学习的各个模块 neighbors近邻算法,svm支持向量机,kernal_ridge核岭回归,discriminant_analysis判别分析,linear_model广义线性模 ...
- sklearn算法中的顶层设计
sklearn监督学习的各个模块 neighbors近邻算法,svm支持向量机,kernal_ridge核岭回归,discriminant_analysis判别分析,linear_model广义线性模 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- skearn自学路径
sklearn学习总结(超全面) 关于sklearn,监督学习几种模型的对比 sklearn之样本生成make_classification,make_circles和make_moons pytho ...
- sklearn小知识
特征缩放:# 为了追求机器学习和最优化算法的最佳性能,我们将特征缩放 from sklearn.preprocessing import StandardScaler sc = StandardSca ...
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
随机推荐
- C++中 string 的用法大全
之所以抛弃char*的字符串而选用C++标准程序库中的string类,是因为他和前者比较起来,不必 担心内存是否足够.字符串长度等等,而且作为一个类出现,他集成的操作函数足以完成我们大多数情况下(甚至 ...
- 19_04_02校内训练[deadline]
题意 给出一个二分图,左边为A集合,右边为B集合,要求把A集合中每一个点染为黑白两色中的一种,B集合中的颜色已定.染色后对于原本相邻且颜色相同的点,建立新的二分图,即得到了两个新的二分图,它们是独立的 ...
- docker-compose docker启动工具,容器互联
简介: docker可以一条命令就运行一个配置好的服务器,很是方便. 但是也有一个问题就是,当参数比较多,映射目录比较多,映射端口比较多………… 我以前就是写个脚本,用脚本来启动,很low啊. 也见到 ...
- iOS 在工程内部创建一个静态库target
当你在开发项目的时候需要把公用的东西打包出来,其他项目方便使用的时候,打包成静态库是你的最优选择,在工程内部开发的时候新建一个target进行静态库的开发可以使你的开发调试更加方便而不是单独新建一个工 ...
- leetcode python 009
##懒得自己做 ## 验证回文数字int0=63435435print(int(str(int0)[::-1])==int)
- top 常用
top -c 查看进程 同时 shift +m 内存倒序
- ipone 5s上,字体rem遇到的问题
webapp中,12px的字体,利用rem实现自适应布局, 发现只有在ipone 5s中字体超大, 这两个class元素中字体一样大小,发现上面元素字体在ipone 5s中很大, 后来验证问题在哪里, ...
- 微信连wifi,中文ssid报Invalid sign tosign错误
Invalid sign tosign错误如上: 是微信官方接受和回传的问题,改固定字符解决: 比如将ssid固定修改为字符串‘ssid’即可:
- Add和AddRange的使用
Add 是每次将单个元素添加到集合里面 AddRange可以一次性添加多个元素到集合里面 AddRange例子: public static int ExecuteCommand(st ...
- SLEUTH 城市扩张模型
3.19号准备试着运行一下SLEUTH模型,但是好不容易没报错出了一个test的结果,我就再也没看过了,导致现在我竟然差不多忘记当时怎么搞出来的了... 这也提醒我了,,,以后解决一个什么东西一定要立 ...