Sklearn (一) 监督学习
本系列博文是根据SKlearn的一个学习小结,并非原创!
1.直接学习TensorFlow有点不知所措,感觉需要一些基础知识做铺垫。
2.之前机器学习都是理论《Ng机器学习基础》+底层编写《机器学习实战》,现实生活基本用不到。
3.会增加一些个人总结,也会删除一些以前学过的知识。
|
广义线性模型 |
1.1 普通最小二乘法
然而,对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵  的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
Example:
SK的数据集介绍:https://blog.csdn.net/sa14023053/article/details/52086695,暂时用不到那么多,用到什么看什么吧!
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
'''
这是一个糖尿病的数据集,
主要包括442行数据,10个属性值
分别是:Age(年龄)、
性别(Sex)、
Body mass index(体质指数)、
Average Blood Pressure(平均血压)、
S1~S6一年后疾病级数指标。
Target为一年后患疾病的定量指标。
'''
diabetes = datasets.load_diabetes()
# 取其中的一个数据进行试验
# https://blog.csdn.net/lanchunhui/article/details/49725065,
# np.newaxis的含义和分析,其中也可以写作下面的形式:
# diabetes.data[:,2][:,np.newaxis] 或者 diabetes.data[:,2][:,None]
# 目的为了增加一个轴
diabetes_X = diabetes.data[:, np.newaxis, 2] #(442,10)
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients,打印权重
print('Coefficients: \n', regr.coef_)
# The mean squared error,损失函数
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
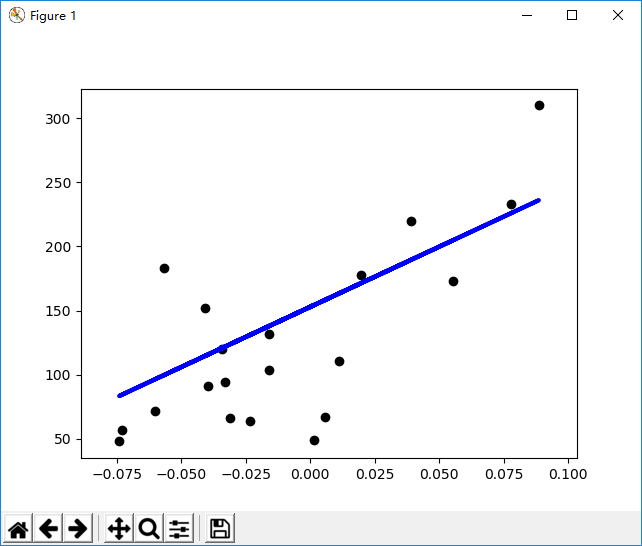
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
#plt.xticks()/plt.yticks()设置轴记号
#现在是明白干嘛用的了,就是人为设置坐标轴的刻度显示的值
'''
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\pi/2$', r'$0$', r'$+\pi/2$', r'$+\pi$'])
plt.yticks([-1, 0, +1],
[r'$-1$', r'$0$', r'$+1$'])
'''
#plt.xticks(())
#plt.yticks(())
plt.show()
1.2 岭回归
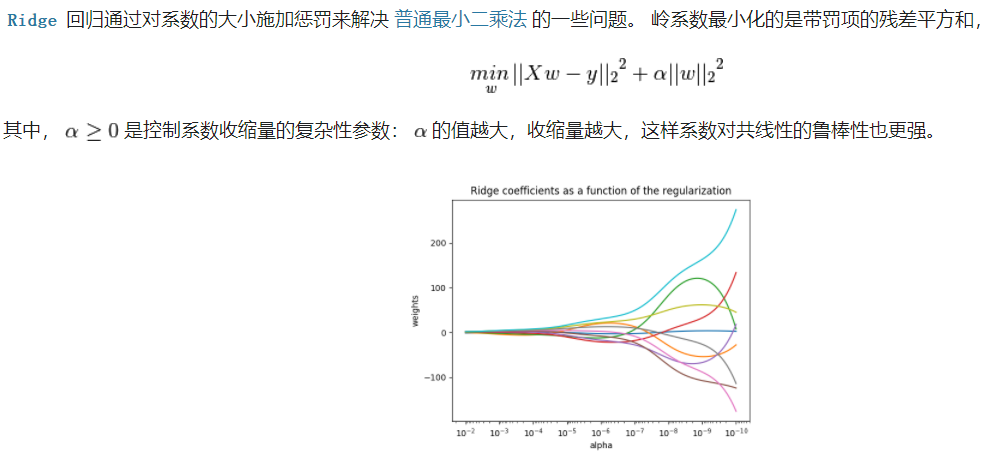
注释:就是加了一个惩罚项,防止过拟合~~
Exanple和简单线性回归一样的表达~~
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge (alpha = .5)
>>> reg.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
>>> reg.coef_
array([ 0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...
1.3 贝叶斯岭回归
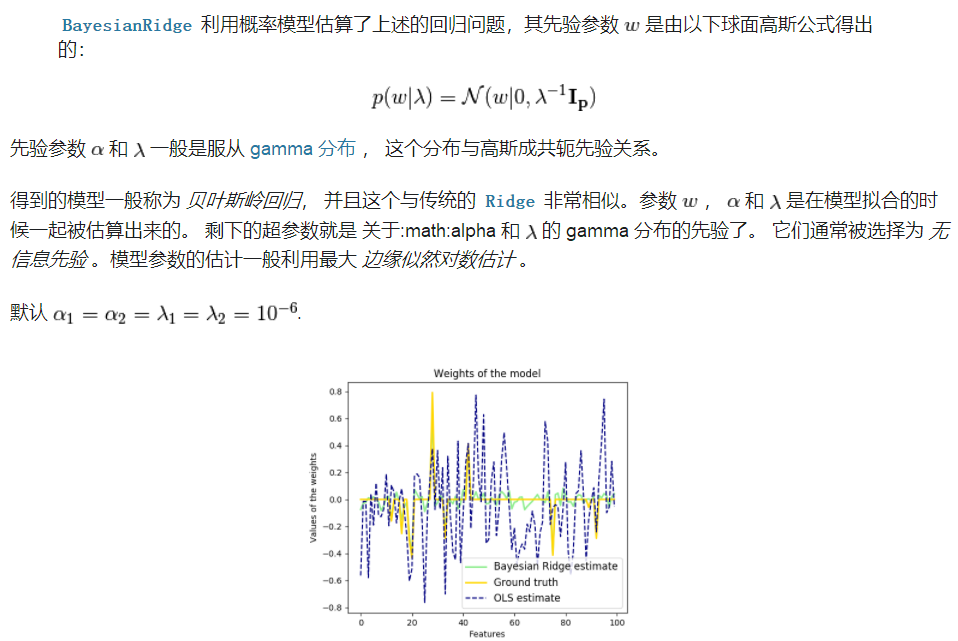
训练数据:
>>> from sklearn import linear_model
>>> X = [[0., 0.], [1., 1.], [2., 2.], [3., 3.]]
>>> Y = [0., 1., 2., 3.]
>>> reg = linear_model.BayesianRidge()
>>> reg.fit(X, Y)
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,
normalize=False, tol=0.001, verbose=False)
预测数据:
>>> reg.predict ([[1, 0.]]) array([ 0.50000013])
查看权重:
>>> reg.coef_ array([ 0.49999993, 0.49999993])
参考:
http://sklearn.apachecn.org/cn/0.19.0/modules/linear_model.html
https://blog.csdn.net/eastmount/article/details/52929765
http://cwiki.apachecn.org/pages/viewpage.action?pageId=10814293
http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge
Sklearn (一) 监督学习的更多相关文章
- sklearn半监督学习
标签: 半监督学习 作者:炼己者 欢迎大家访问 我的简书 以及 我的博客 本博客所有内容以学习.研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢! --- 摘要:半监督学习 ...
- 关于sklearn,监督学习几种模型的对比
# K近邻,适用于小型数据集,是很好的基准模型,容易解释 from sklearn.neighbors import KNeighborsClassifier # 线性模型,非常可靠的首选算法,适用于 ...
- sklearn算法库的顶层设计
sklearn监督学习的各个模块 neighbors近邻算法,svm支持向量机,kernal_ridge核岭回归,discriminant_analysis判别分析,linear_model广义线性模 ...
- sklearn算法中的顶层设计
sklearn监督学习的各个模块 neighbors近邻算法,svm支持向量机,kernal_ridge核岭回归,discriminant_analysis判别分析,linear_model广义线性模 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- skearn自学路径
sklearn学习总结(超全面) 关于sklearn,监督学习几种模型的对比 sklearn之样本生成make_classification,make_circles和make_moons pytho ...
- sklearn小知识
特征缩放:# 为了追求机器学习和最优化算法的最佳性能,我们将特征缩放 from sklearn.preprocessing import StandardScaler sc = StandardSca ...
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
随机推荐
- day050 django第一天 自定义框架
1.简单的web框架 1. 创建一个简单的python文件: import socket sever=socket.socket() sever.bind(('127.0.0.1',8001)) se ...
- 1. qt 入门-整体框架
总结: 本文先通过一个例子介绍了Qt项目的大致组成,即其一个简单的项目框架,如何定义窗口类,绑定信号和槽,然后初始化窗口界面,显示窗口界面,以及将程序的控制权交给Qt库. 然后主要对Qt中的信号与槽机 ...
- SharePoint Framework Extensions GA Release
博客地址:http://blog.csdn.net/FoxDave SharePoint Framework Extensions GA版本已经发布了,介于最近个人工作的变动调整,还没时间好好了解一下 ...
- THML
结构<!DOCTYE html> <html> <head> <meta charset="UTF-8> <titie>< ...
- touchend偶尔不触发(待解决)
新闻流,实现tab横向切换效果,出现偶尔切到一半,手指移开后,没有跳转到上一个或下一个tab,而是持续在当前切了一半的位置. 找到原因: 没有切换的时候,touchend都没有触发. 网上找到的解决办 ...
- BiLstm原理
Lstm这里就不说了,直接说Bilstm. 前向的LSTM与后向的LSTM结合成BiLSTM.比如,我们对“我爱中国”这句话进行编码,模型如图所示. 前向的依次输入“我”,“爱”,“中国”得到三个向量 ...
- FCC JS基础算法题(1):Factorialize a Number(计算一个整数的阶乘)
题目描述: 如果用字母n来代表一个整数,阶乘代表着所有小于或等于n的整数的乘积.阶乘通常简写成 n!例如: 5! = 1 * 2 * 3 * 4 * 5 = 120. 算法: function fac ...
- usermod语法
语法 usermod [-LU][-c <备注>][-d <登入目录>][-e <有效期限>][-f <缓冲天数>][-g <群组>][-G ...
- 基于Verilog的带FIFO写入缓冲的串口发送接口封装
一.模块框图及基本思路 tx_module:串口发送的核心模块,详细介绍请参照前面的“基于Verilog的串口发送实验” fifo2tx_module:当fifo不为空时,读取fifo中的数据并使能发 ...
- day 11 函数参数
形参与实参 形参:就是形式参数,在函数定义时,写在括号里面指定的参数就是形式参数 实参:在调用函数时传入的参数就是实参 在调用函数时就会自动的把形参与实参绑定起来,然后调用结束之后,解除绑定关系 位置 ...