fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时
fashion_mnist 计算准确率、召回率、F1值
1、定义
首先需要明确几个概念:
假设某次预测结果统计为下图:
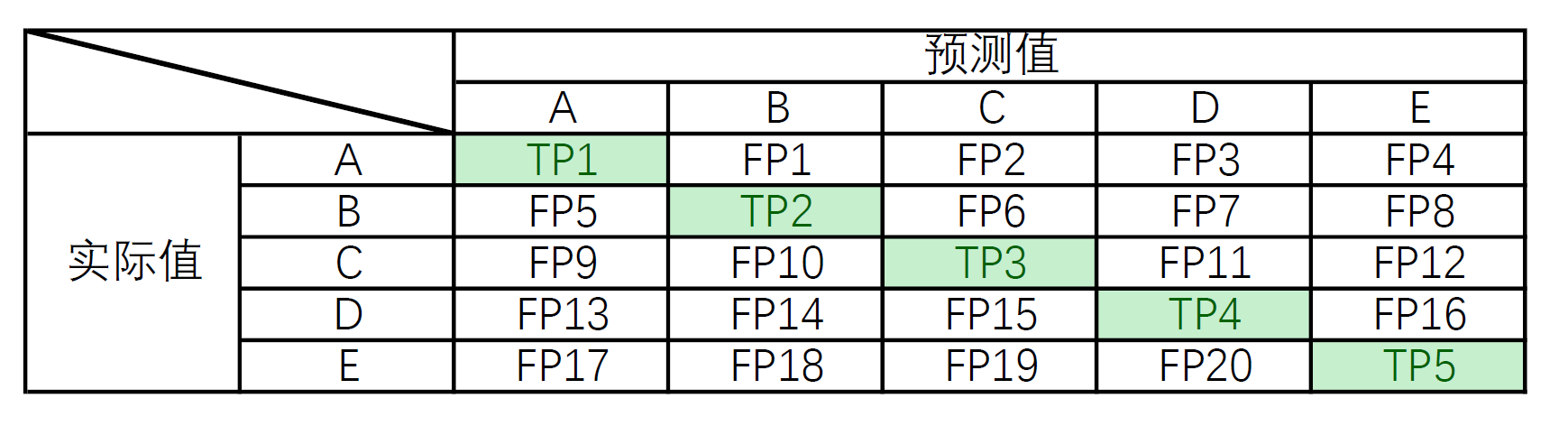
那么各个指标的计算方法为:
- A类的准确率:TP1/(TP1+FP5+FP9+FP13+FP17) 即预测为A的结果中,真正为A的比例
- A类的召回率:TP1/(TP1+FP1+FP2+FP3+FP4) 即实际上所有为A的样例中,能预测出来多少个A(的比例)
- A类的F1值:(准确率*召回率*2)/(准确率+召回率)
实际上我们在训练出某个模型后,会将测试集中每个测试样例进行一次结果预测,因此只需统计这些结果,经过计算即可得到各类数据的准确率、召回率、F1值
2、使用fashion_mnist
需要提前pip安装tensorflow、prettytable、numpy
from tensorflow import keras
import numpy as np
import prettytable
# 下载数据集
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 制作标签名称
class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boot']
# 图片数据归一化
train_images = train_images / 255.0
test_images = test_images / 255.0
# 构建3层DNN模型,使用激活函数softmax
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
# 定义模型的损失函数,优化器与评估指标
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy']
)
# 训练模型
model.fit(train_images, train_labels, epochs=5)
# 评估模型
predictions = model.predict(test_images)
train_result = np.zeros((10, 10), dtype=int)
for i in range(10000):
train_result[test_labels[i]][np.argmax(predictions[i])] += 1
result_table = prettytable.PrettyTable()
result_table.field_names = ['Type', 'Accu', 'Recall', 'F1']
for i in range(10):
ac = train_result[i][i] / sum(train_result.T[i])
rc = train_result[i][i] / sum(train_result[i])
result_table.add_row([class_names[i], round(ac, 3), round(rc, 3), round(ac * rc * 2 / (ac + rc), 3)])
print(result_table)
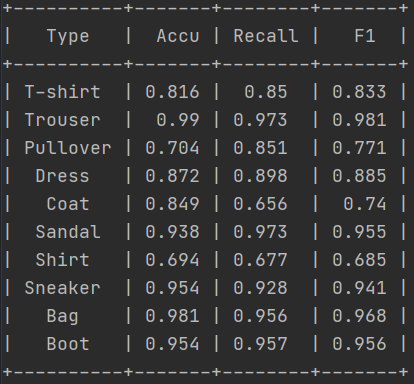
实际效果:
fashion_mnist 计算准确率、召回率、F1值的更多相关文章
- 机器学习笔记--classification_report&精确度/召回率/F1值
https://blog.csdn.net/akadiao/article/details/78788864 准确率=正确数/预测正确数=P 召回率=正确数/真实正确数=R F1 F1值是精确度和召回 ...
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介 sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要 ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率P 召回率R
Evaluation metricsa binary classifier accuracy,specificity,sensitivety.(整个分类器的准确性,正确率,错误率)表示分类正确:Tru ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
随机推荐
- jdbc插入或查询数据库时间总是比实际时间少8小时原因
mysql插入数据库的时间总是有问题,比实际时间要早8小时.检查是jdbc连接的url中配置的时区有问题,原先是 jdbc.url=jdbc:mysql://47.**.**.**:3306/yeey ...
- 关于static
static是静态的意思: static修饰的成员变量,在内存中存在于方法区中,只有一份,非静态的成员变量在堆中,每个对象中都有一份 public class Demo1 { public st ...
- 统计学习:逻辑回归与交叉熵损失(Pytorch实现)
1. Logistic 分布和对率回归 监督学习的模型可以是概率模型或非概率模型,由条件概率分布\(P(Y|\bm{X})\)或决 策函数(decision function)\(Y=f(\bm{X} ...
- 手把手带你基于嵌入式Linux移植samba服务
摘要:Samba是在Linux和UNIX系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成. 本文分享自华为云社区<嵌入式Linux下移植samba服务--<基于北斗和4G ca ...
- Solution -「LOJ #6053」简单的函数
\(\mathcal{Description}\) Link. 积性函数 \(f\) 满足 \(f(p^c)=p\oplus c~(p\in\mathbb P,c\in\mathbb N_+) ...
- Python基础—编码(Day2)
一.字符编码 1.ASCII码:包含英文.数字.特殊字符,8位=1字节byte =1个字符,如: 0010 1010 ASCII码表里的字符总共有256个,前128个为常用的字符如运算符,后128个称 ...
- unity3d导出xcode项目使用afnetworking 3框架导致_kUTTagClassMIMEType 问题解决方案
http://blog.csdn.net/huayu_huayu/article/details/51781953 (参考链接) Undefined symbols for architecture ...
- Windows server 2016 2019远程端口修改操作
windows server 2016 2019修改远程端口操作 一.修改3389远程端口 1,按"win+r"快捷键,在对话框中输入regedit 2, 找到路径 \HKEY ...
- [自动化]ansible-系统安全加固整改
基线漏洞安全整改 修复环境:centos7及以上 安全基线的概念 安全基线是一个信息系统的最小安全保证,即该信息系统最基本需要满足的安全要求.信息 系统安全往往需要在安全付出成本与所能够承受的安全风险 ...
- [BACKUP] Visual Studio Code 配置
0 VSCode 便携模式:https://code.visualstudio.com/docs/editor/portable#_enable-portable-mode 1. 字体 FiraCod ...