5、爬虫之scrapy框架
一 scrapy框架简介
1 介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
整体架构大致如下:
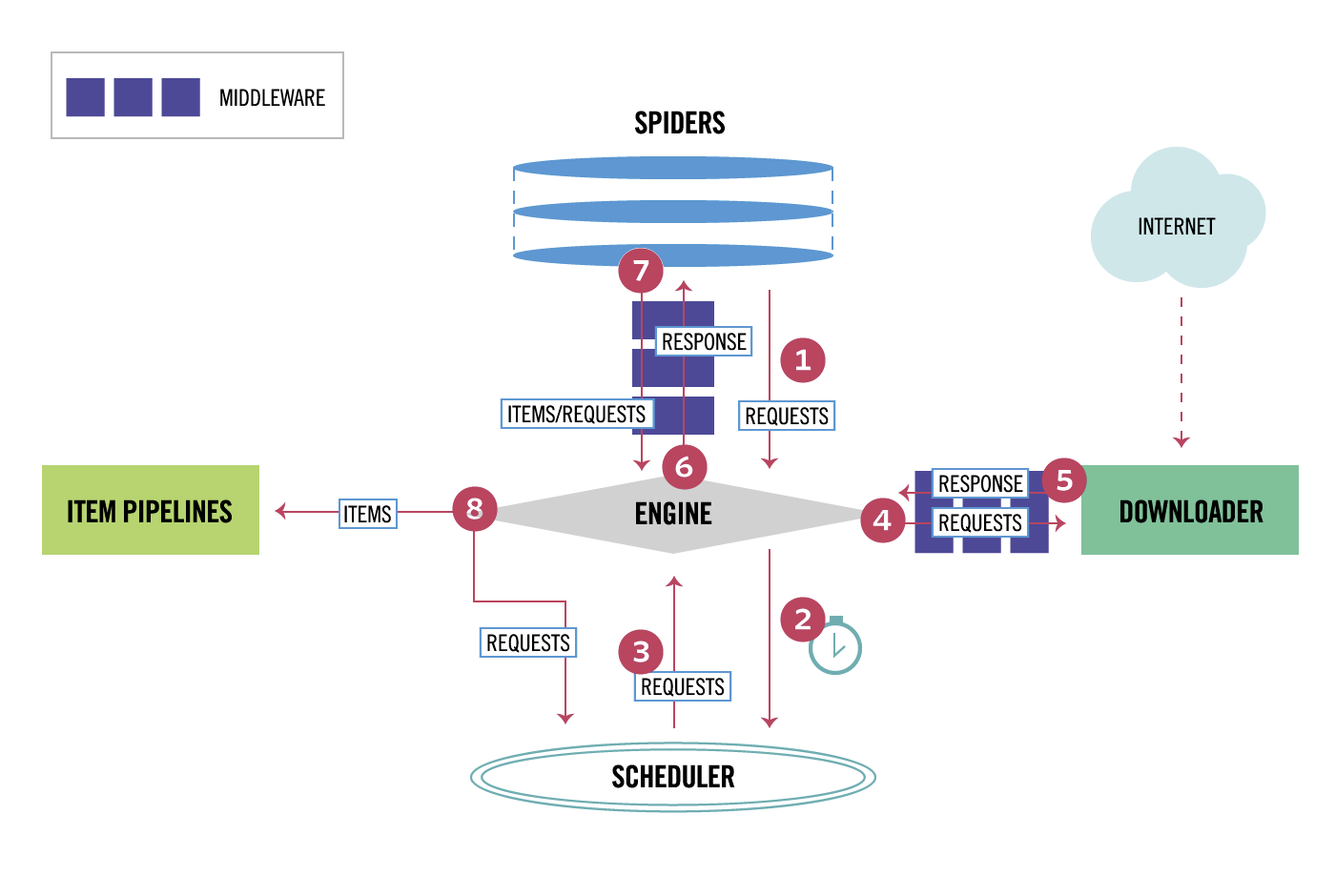
Components:
1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
2、调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5、项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
你可用该中间件做以下几件事:
(1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
(2) change received response before passing it to a spider;
(3) send a new Request instead of passing received response to a spider;
(4) pass response to a spider without fetching a web page;
(5) silently drop some requests.
6、爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
下载
#Linux:
pip3 install scrapy
#Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
5、爬虫之scrapy框架的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
随机推荐
- array与xml转换实现(转)
<?php function xml_encode($data, $charset = 'utf-8', $root = 'so') { $xml = '<?xml version=&qu ...
- 实验吧 burpsuie拦截修改请求
Forbidden 解题链接:http://ctf5.shiyanbar.com/basic/header/ 把language改成zh-hk,go,flag到手 Forms 题目地址:http:// ...
- netty源码解解析(4.0)-12 Channel NIO实现:channel初始化
创建一个channel实例,并把它register到eventLoopGroup中之后,这个channel然后处于inactive状态,仍然是不可用的.只有在bind或connect方法调用成功之后才 ...
- FFmpeg编解码处理1-转码全流程简介
本文为作者原创,转载请注明出处:https://www.cnblogs.com/leisure_chn/p/10584901.html FFmpeg编解码处理系列笔记: [0]. FFmpeg时间戳详 ...
- 记录解决phpStudy报出403Forbidden问题的方法
本人输入ip地址+目录去访问PHPTutorial/WWW目录下的某个文件,发生了没有权限访问的问题,导了一个下午,终于解决……不忘在此做个记录 1. 打开phpStudy,点击按键“其他选项菜单”= ...
- typeof() 和 GetType()区是什么
1.typeof(x)中的x,必须是具体的类名.类型名称等,不可以是变量名称. 2.GetType()方法继承自Object,所以C#中任何对象都具有GetType()方法,它的作用和typeof() ...
- Vue动态新增对象属性
Vue.set( target, key, value ) 参数: {Object | Array} target {string | number} key {any} value 返回值:设置的值 ...
- hadoop之 hadoop能为企业做什么?
hadoop是什么? Hadoop是一个开源的框架,可编写和运行分不是应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式.Hadoop=HDFS( ...
- Starting zookeeper ... already running as process 1805错误
启动zookeeper的时候,报Starting zookeeper ... already running as process 1805错误 上面这个错误意思为以作为进程1805运行.系统检测到你 ...
- Linux常用基本命令:grep-从文件或者管道中筛选匹配的行
grep命令 作用:从文本文件或管道数据流中筛选匹配的行及数据,配合正则表达式一起使用,功能更加强大. 格式: grep [options] [pattern] [file] 1,匹配包含" ...