disjoint set
MAKE-SET.x/ creates a new set whose only member (and thus representative)
is x. Since the sets are disjoint, we require that x not already be in some other
set.
UNION.x; y/ unites the dynamic sets that contain x and y, say Sx and Sy, into a
new set that is the union of these two sets. We assume that the two sets are disjoint
prior to the operation. The representative of the resulting set is any member
of Sx [ Sy, although many implementations of UNION specifically choose the
representative of either Sx or Sy as the new representative. Since we require
the sets in the collection to be disjoint, conceptually we destroy sets Sx and Sy,
removing them from the collection S. In practice, we often absorb the elements
of one of the sets into the other set.
FIND-SET.x/ returns a pointer to the representative of the (unique) set containing
x.

linklist implement
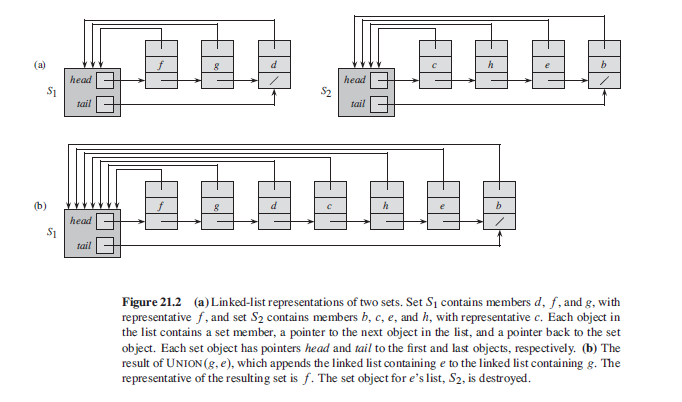
In the worst case, the above implementation of the UNION procedure requires an
average of ‚.n/ time per call because we may be appending a longer list onto
a shorter list; we must update the pointer to the set object for each member of
the longer list. Suppose instead that each list also includes the length of the list
(which we can easily maintain) and that we always append the shorter list onto the
longer, breaking ties arbitrarily. With this simple weighted-union heuristic, a single
UNION operation can still take _.n/ time if both sets have _.n/ members. As
the following theorem shows, however, a sequence of m MAKE-SET, UNION, and
FIND-SET operations, n of which are MAKE-SET operations, takes O.m C n lg n/
time.
Tree implement
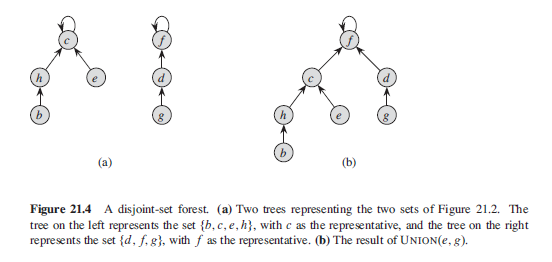
Heuristics to improve the running time
So far, we have not improved on the linked-list implementation. A sequence of
n 1 UNION operations may create a tree that is just a linear chain of n nodes. By
using two heuristics, however, we can achieve a running time that is almost linear
in the total number of operations m.
The first heuristic, union by rank, is similar to the weighted-union heuristic we
used with the linked-list representation. The obvious approach would be to make
the root of the tree with fewer nodes point to the root of the tree with more nodes.
Rather than explicitly keeping track of the size of the subtree rooted at each node,
we shall use an approach that eases the analysis. For each node, we maintain a
rank, which is an upper bound on the height of the node. In union by rank, we
make the root with smaller rank point to the root with larger rank during a UNION
operation.
The second heuristic, path compression, is also quite simple and highly effective.
As shown in Figure 21.5, we use it during FIND-SET operations to make each
node on the find path point directly to the root. Path compression does not change
any ranks(more nodes linked to the root will cause much possibility to find it).

When we use both union by rank and path compression, the worst-case running
time is O.m ˛.n//, where ˛.n/ is a very slowly growing function, which we define
in Section 21.4. In any conceivable application of a disjoint-set data structure,
˛.n/ 4; thus, we can view the running time as linear in m in all practical situations.
Strictly speaking, however, it is superlinear. In Section 21.4, we prove this
upper bound.
package disjoint_sets;
// there have two ways,one is the linkedlist,the other is the tree,use the tree here
public class disjoint_set {
private static class Node{
private Node p;
private int rank;
private String name;
public Node(String na){
p = this; rank = 0;name = na;
}
}
public static void union(Node x,Node y){
link(findset(x),findset(y));
}
public static void link(Node x,Node y){
if(x.rank > y.rank){
y.p = x;
}
else if(y.rank > x.rank){
x.p = y;
}
else{
y.p = x;
x.rank = x.rank + 1;
}
}
public static Node findset(Node x){
if(x != x.p){
x.p = findset(x.p); //path compression
}
return x.p;
}
public static void print(Node x){ System.out.println(x.name);
if(x != x.p){
x = x.p;
print(x);
}
return;
}
public static void main(String[] args) {
Node a = new Node("a");
Node b = new Node("b");
Node c = new Node("c");
Node d = new Node("d");
union(a,b);
union(b,c);
union(a,d);
print(d); } }
disjoint set的更多相关文章
- [LeetCode] Data Stream as Disjoint Intervals 分离区间的数据流
Given a data stream input of non-negative integers a1, a2, ..., an, ..., summarize the numbers seen ...
- hdu 1232, disjoint set, linked list vs. rooted tree, a minor but substantial optimization for path c 分类: hdoj 2015-07-16 17:13 116人阅读 评论(0) 收藏
three version are provided. disjoint set, linked list version with weighted-union heuristic, rooted ...
- 数据结构与算法分析 – Disjoint Set(并查集)
什么是并查集?并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题. 并查集的主要操作1.合并两个不相交集合2.判断两个元素是否属于同一集合 主要操作的解释 ...
- 并查集(Disjoint Set)
在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.这一类问题其特点是看似并不复杂, ...
- Leetcode: Data Stream as Disjoint Intervals && Summary of TreeMap
Given a data stream input of non-negative integers a1, a2, ..., an, ..., summarize the numbers seen ...
- LeetCode-Data Stream as Disjoint Intervals
Given a data stream input of non-negative integers a1, a2, ..., an, ..., summarize the numbers seen ...
- leetcode@ [352] Data Stream as Disjoint Intervals (Binary Search & TreeSet)
https://leetcode.com/problems/data-stream-as-disjoint-intervals/ Given a data stream input of non-ne ...
- 【leetcode】352. Data Stream as Disjoint Intervals
问题描述: Given a data stream input of non-negative integers a1, a2, ..., an, ..., summarize the numbers ...
- 352. Data Stream as Disjoint Intervals
Plz take my miserable life T T. 和57 insert interval一样的,只不过insert好多. 可以直接用57的做法一个一个加,然后如果数据大的话,要用tree ...
- 数据结构 之 并查集(Disjoint Set)
一.并查集的概念: 首先,为了引出并查集,先介绍几个概念: 1.等价关系(Equivalent Relation) 自反性.对称性.传递性. 如果a和b存在等价关系,记 ...
随机推荐
- 《CSS世界》读书笔记(三) --width:auto
<!-- <CSS世界> 张鑫旭著 --> width:auto width:auto至少包含了以下4种不同的宽度表现: 充分可利用空间.比方说,<div>.&l ...
- phpstudy 安装 Apcahe SSL证书 实现https连接
摘自:https://jingyan.baidu.com/article/64d05a022e6b57de54f73b51.html Windows phpstudy安装ssl证书教程. 工具/原料 ...
- 【一些容易忘记的node的npm命令】【收集】
更新npm到最新版本 npm update -g npm 安装依赖包时命令的一些区别 npm install xxx -g //(全局安装) npm install xxx --save-dev // ...
- java329 继承、类的高级概念
- lvs 初始 第一章
Linux Virtual Server 第一章 初识 一 . 介绍 LVS集群采用IP负载均衡技术和基于内容请求分发技术.调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动 ...
- vue中使用cookies和crypto-js实现记住密码和加密
前端加密 使用crypto-js加解密 第一步,安装 npm install crypto-js 第二步,在你需要的vue组件内import import CryptoJS from "cr ...
- vi删除当前行的字符
x 删除当前光标下的字符dw 删除光标之后的单词剩余部分.d$ 删除光标之后的该行剩余部分.dd 删除当前行
- sony Z5P 刷rec、root的方法
想root需要刷第三方recovery,刷recovery需要先解锁.但如果直接解锁,会丧失相机算法.屏幕超逼真模式,所以不能直接来. 大体步骤就是解完锁后自己做个内核刷进去,欺骗系统让他觉得没解锁. ...
- git在本地回退
参考https://www.cnblogs.com/qufanblog/p/7606105.html 已经用 git commit 提交了代码. 可以使用 git reset --hard HEAD ...
- h5设计图尺寸
640 标准的话 设计图: 640*1136 body,html 背景图的话需要640*1008的 这样才能整屏刚刚好 750 标准的话 设计图: 750*1334 body,html背景图的话,75 ...