hadoop NameNode HA 和ResouceManager HA
官网配置地址:
ResourceManager HA : http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
安装jdk
关闭防火墙
hadoop自动HA借助于zookeeper实现,整体架构如下:
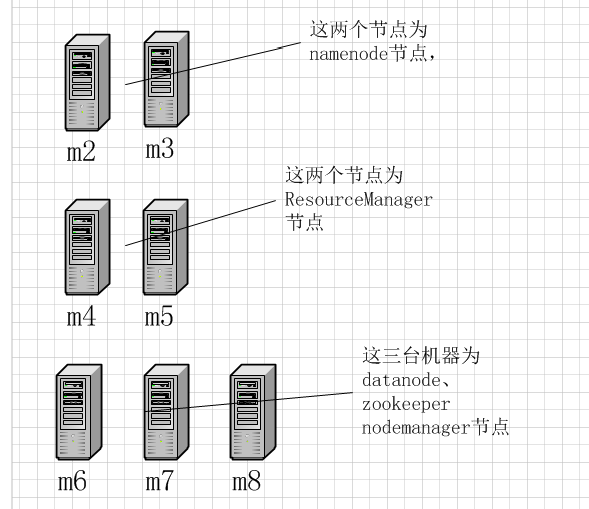
m2和m3作为NameNode节点应该配置与其他所有节点的SSH无密码登录
m4和m5应该与m6、m7、m8配置SSH无密码登录
core-site.xml具体配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>m6:2181,m7:2181,m8:2181</value>
</property>
</configuration>
hdfs-site.xml具体配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property> <property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property> <property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>m2:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>m3:9820</value>
</property> <property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>m2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>m3:9870</value>
</property> <property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://m6:8485;m7:8485;m8:8485;/cluster</value>
</property> <property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(shell(/bin/true))
</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property> <property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value>
</property> <property>
<name>dfs.replication</name>
<value>3</value>
</property> <property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> </configuration>
yarn-site.xml具体配置
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties --> <property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>m4</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>m5</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>m4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>m5:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>m6:2181,m7:2181,m8:2181</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> </configuration>
mapred-site.xml具体配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves具体配置
m6
m7
m8
拷贝hadoop到m3、m4、m5、m6、m7、m8
scp -r hadoop-2.7.3/ m3:/home/hadoop/app/
scp -r hadoop-2.7.3/ m4:/home/hadoop/app/
scp -r hadoop-2.7.3/ m5:/home/hadoop/app/
scp -r hadoop-2.7.3/ m6:/home/hadoop/app/
scp -r hadoop-2.7.3/ m7:/home/hadoop/app/
scp -r hadoop-2.7.3/ m8:/home/hadoop/app/
zookeeper配置zoo.cfg(m6 m7 m8)
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/home/hadoop/app/zookeeper-3.3.6/data
# the port at which the clients will connect
clientPort=2181
server.1=m6:2888:3888
server.2=m7:2888:3888
server.3=m8:2888:3888
配置好后的启动顺序:
1、启动zookeeper ./bin/zkServer.sh start
2、分别在m6 m7 m8上启动journalnode, ./hadoop-daemon.sh start journalnode只有第一次才需要手动启动journalnode,以后启动hdfs的时候会自动启动journalnode
3、在m2上格式化namenode,格式化成功后拷贝元数据到m3节点上
4、格式化zkfc ./bin/hdfs zkfc -formatZK 只需要一次
5、启动hdfs
6、启动yarn
验证:
通过kill命令杀死namenode进程观察namenode节点是否会自动切换
yarn rmadmin -getServiceState rm1查看那个resourceManager是active那个是standby
单独启动namenode: ./sbin/hadoop-daemon.sh start namenode
hadoop NameNode HA 和ResouceManager HA的更多相关文章
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop搭建高可用的HA集群
一.工具准备 1.7台虚拟机(至少需要3台),本次搭建以7台为例,配好ip,关闭防火墙,修改主机名和IP的映射关系(/etc/hosts),关闭防火墙 2.安装JDK,配置环境变量 二.集群规划: 集 ...
- 虚拟机centos7系统下安装hadoop ha和yarn ha(详细)
一:基础环境准备 (一):虚拟机新建五个centos7系统(复制文件夹的方式) (二):角色分配 (三)按照角色分配表配置 (1)更改主机ip(自行查找),如果只是个人搭建玩一玩,可选择安装cento ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- hadoop 2.0安装及HA配置简述
一.单机模式 a.配置本机到本机的免密登录 b.解压hadoop压缩包,修改hadoop.env.sh中的JAVA_HOME c.修改core-site.xml <configuration&g ...
- Hadoop集群搭建(非HA)
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
随机推荐
- JavaScript正则验证邮箱
正则表达式/^正则$/.test() <html> <head> <title>JavaScript</title> <meta charset= ...
- NV OIT algorithm : Depth peeling is a fragment-level depth sorting technique
https://developer.nvidia.com/content/interactive-order-independent-transparency Correctly rendering ...
- 简单排序算法 C++类实现
简单排序算法: 冒泡排序 插入排序 选择排序 .h代码: // // SortClass.h // sort and selection // // Created by wasdns on 16/1 ...
- Memcached 笔记与总结(6)PHP 实现 Memcached 的一致性哈希分布算法
首先创建一个接口,有 3 个方法: addServer:添加一个服务器到服务器列表中 removeServer:从服务器列表中移除一个服务器 lookup:在当前的服务器列表中找到合适的服务器存放数据 ...
- Redis 笔记与总结3 list 类型
redis 版本 [root@localhost ~]# redis-server --version Redis server v= sha=: malloc=jemalloc- bits= bui ...
- PHP 错误与异常 笔记与总结(1)错误(Deprecated,Notice,Warning)
[常见的错误类型] ① 语法错误 [例1]程序语句结尾少了';' <?php $username = "dee" //少了分号; echo $username; 输出: ( ...
- 西川善司【神秘海域(Uncharted)】的图形分析
本文是为传播0月8日发售的[神秘海域 合集]魅力而短篇连载的第2回,这次主要集中在神秘海域系列的图形的技术方面.原文链接在 http://weekly.ascii.jp/elem/000/ ...
- phpstorm8注册码
phpstorm8注册码 phpstorm 8 注册码 用户名:Learn Programming License key:(包括LICENSE BEGIN和LICENSE END部分) ==== ...
- B-Tree indexs
mysql_High.Performance.MySQL.3rd.Edition.Mar.2012 A B-Tree index speeds up data access because the s ...
- BAE3.0上的java+tomcat代码发布
---------------------------------2016/01/25更新-------------------------------------- 最近两天去百度开放云,发现它再也 ...