【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html
- sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
复制代码
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
【转】HADOOP HDFS BALANCER介绍及经验总结的更多相关文章
- HADOOP HDFS BALANCER介绍及经验总结(转)
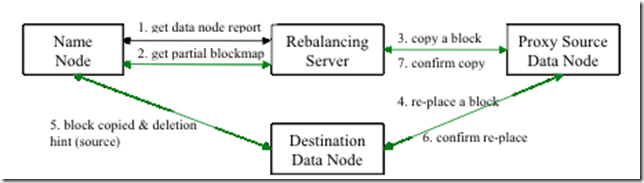
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决? 2.尽量不在NameNode上执行start-balancer.sh的原因是什么? 集群平衡介绍 Hadoop的HDFS集群非常 ...
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- Hadoop记录-HDFS balancer配置
HDFS balancer配置(可通过CM配置)dfs.datanode.balance.max.concurrent.moves 并行移动的block数量,默认5 dfs.datanode.bala ...
- 【Hadoop离线基础总结】HDFS详细介绍
HDFS详细介绍 分布式文件系统设计思路 概述 只有一台机器时的文件查找:hello.txt /export/servers/hello.txt 如果有多台机器时的文件查找:hello.txt nod ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- sudo -u hdfs hdfs balancer出现异常 No lease on /system/balancer.id
16/06/02 20:34:05 INFO balancer.Balancer: namenodes = [hdfs://dlhtHadoop101:8022, hdfs://dlhtHadoop1 ...
随机推荐
- Quartz.net开源作业调度框架使用详解(转)
前言 quartz.net作业调度框架是伟大组织OpenSymphony开发的quartz scheduler项目的.net延伸移植版本.支持 cron-like表达式,集群,数据库.功能性能强大更不 ...
- jquery源码分析-工具函数
jQuery的版本一路狂飙啊,现在都到了2.0.X版本了.有空的时候,看看jquery的源码,学习一下别人的编程思路还是不错的. 下面这里是一些jquery的工具函数代码,大家可以看看,实现思路还是很 ...
- 理解css中的line-height
在css中,line-height有下面五种可能的值:我们来看看w3c中列出如下可能值: normal:默认,设置合理的行间距. number:设置数字,此数字会与当前的字体尺寸相乘来设置行间距. l ...
- 关于vue.js 组件的调用
包子初学vue.js,有很多不明白的地方还请大家多多指教,在组件的调用的时候,包子有点懵,因为感觉调用组件的方式非常的麻烦,每一个都要实例化,不过,通过不断询问大牛们,我找到了,动态加载组件的方法~~ ...
- Billboard(线段树)
Billboard Time Limit:8000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit St ...
- js检测是否安装了flash插件
function flashChecker() { var hasFlash = 0; //是否安装了flash var flashVersion = 0; //flash版本 var isIE = ...
- 对于(function(){}())和function(){}实例的作用域分析(里面有很多问题……)
今天在群里看到一个问题,让我纠结了好一会.下面是我的分析,感觉里面还有很多问题,关于作用域还是不太理解,希望大家看到问题第一时间反馈给我,看到实在受不了的地方说几句都没关系,谢谢. 请看题: 1.对象 ...
- [ruby on rails] 跟我学之(4)路由映射
前面<[ruby on rails] 跟我学之Hello World>提到,路由对应的文件是 config/routes.rb 实际上我们只是添加了一句代码: resources :pos ...
- 生成PHP数组文件
1. 解释型语言的妙处之一,在于可以动态生成代码再调用执行~2. 对于数据量不大(几千条?)的(key,value),存成数组文件,执行查找操作,效率应该是好于数据库操作的:3. php的数组,是ha ...
- 【Other】推荐点好听的钢琴曲
2013-12-13 16:19 匿名 | 浏览 138977 次 音乐钢琴 推荐点好听的钢琴曲,纯音乐也可以thanks!!! 2013-12-14 19:34 网友采纳 热心网友 巴洛克:帕海贝尔 ...