facebook 摘要生成阅读笔记(一) A Neural Attention Model for Sentence Summarization
流程:
1.文本和摘要全部输入到模型中。
2.训练时,对生成摘要取前C个词,从头开始取,如果生成的摘要不足C,那么不足的地方直接补<s>。
3.训练时,最大化生成的摘要与原摘要的概率,即每个生成的词与原摘要的词进行对比,用损失函数计算梯度,然后下降。
4.预测时,已经具有了权重的模型,会逐词生成N个词的摘要。
5.注意力:已生成的摘要的前C个词,求出一个注意力权重,然后再成乘以全部文本经过平滑以后的。
6.这里生成词,不是只生成一个,而是生成K个集合。,采用beam search算法来寻找目标单词。
a.这样生成的词不是只有一个,而是生成了K个备选集。
b.第一个词的时候,按照权重生成第一个词,K种可能不是一个词,而是生成K中可能,要逐渐迭代迭代生成词的词数循环。
例如:第一个词生成了K种可能。第二次与第一次生成的词要组成K种可能,原来是K2可能,选出K种概率最大的可能的组合。
Encoder:
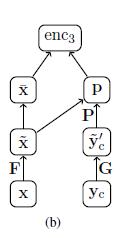
x:整个输入文本
yc:生成的摘要前C个词
y'c:前C个词,经过卷积后的向量
p:soft alighment因子
F:词嵌入矩阵,这里使用的是BOW
G:词嵌入矩阵
P:软对其因子学习矩阵
Decoder:
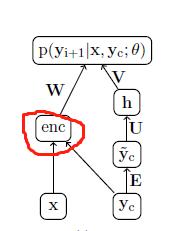
U、W、V:权重矩阵
E:词嵌入矩阵,BOW(这里前C个已生成摘要的词,不需要卷积)
Decoder:会生成K个最大词的概率,然后用beam search去选
总体流程:
encoder->decoder->beam search
facebook 摘要生成阅读笔记(一) A Neural Attention Model for Sentence Summarization的更多相关文章
- facebook 摘要生成阅读笔记(二) Abstractive Sentence Summarization with Attentive Recurrent Neural Networks
整体流程与第一篇差不多,只是在encoder和decoder加入了RNN Encoder: 1. ai=xi+li ai=词向量+词在序列中的位置信息(相当于一个权重,[M, 1]) 流程: 先是CN ...
- 《Graph Neural Networks: A Review of Methods and Applications》阅读笔记
本文是对文献 <Graph Neural Networks: A Review of Methods and Applications> 的内容总结,详细内容请参照原文. 引言 大量的学习 ...
- 阅读笔记——《How a Facebook rejection pushed me to start and grow a profitable business in 12 months》
阅读笔记——<How a Facebook rejection pushed me to start and grow a profitable business in 12 months> ...
- 人体姿势识别,Convolutional pose machines文献阅读笔记。
开源实现 https://github.com/shihenw/convolutional-pose-machines-release(caffe版本) https://github.com/psyc ...
- 关于 AlphaGo 论文的阅读笔记
这是Deepmind 公司在2016年1月28日Nature 杂志发表论文 <Mastering the game of Go with deep neural networks and tre ...
- 《An Attentive Survey of Attention Models》阅读笔记
本文是对文献 <An Attentive Survey of Attention Models> 的总结,详细内容请参照原文. 引言 注意力模型现在已经成为神经网络中的一个重要概念,并已经 ...
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
随机推荐
- SoC FPGA JTAG电路设计 要点
JTAG协议制定了一种边界扫描的规范,边界扫描架构提供了有效的测试布局紧凑的PCB板上元件的能力.边界扫描可以在不使用物理测试探针的情况下测试引脚连接,并在器件正常工作的过程中捕获运行数据. SoC ...
- [转自知乎] 从github上下载单个文件夹
原文地址: 如何从 GitHub 上下载单个文件夹? 注意:如果是在公司网络环境的话需要配置可以访问外网的代理,否则 svn checkout 时会出错.
- 初探FFT(快速傅里叶变换)
第一次接触省选的知识点呢!zrf大佬在课堂上讲的非常清楚,但由于本蒟蒻实在太菜了,直接掉线了.今天赶紧恶补一下. 那么这篇博客将分为两块,第一块是FFT的推导和实现,第二块则是FFT在OI上的应用 因 ...
- delphi 使用oauth的控件
unit OAuth; interface uses Classes, SysUtils, IdURI, Windows; type EOAuthException = class(Exception ...
- C# 如何防止重放攻击(转载)
转载地址:http://www.cnblogs.com/similar/p/6776921.html 重放攻击 重放攻击是指黑客通过抓包的方式,得到客户端的请求数据及请求连接,重复的向服务器发送请求的 ...
- poj 3250 Bad Hair Day(栈的运用)
http://poj.org/problem?id=3250 Bad Hair Day Time Limit: 2000MS Memory Limit: 65536K Total Submissi ...
- Android------------------的资源文件的学习
一.style的学习 用法: 使用: 使用系统自带的style的风格 使用: 效果: 二.drawable的使用 selector是一个xml文件进行加载使用的: 文件名叫做buttonselecto ...
- 弦论(tjoi2015,bzoj3998)(sam(后缀自动机))
对于一个给定长度为\(N\)的字符串,求它的第\(K\)小子串是什么. Input 第一行是一个仅由小写英文字母构成的字符串\(S\) 第二行为两个整数\(T\)和\(K\),\(T\)为0则表示不同 ...
- zoj4019 Schrödinger's Knapsack(dp)
题意:有两种物品分别为n,m个,每种物品对应价值k1,k2.有一个容量为c的背包,每次将一个物品放入背包所获取的价值为k1/k2*放入物品后的剩余体积.求问所获取的最大价值. 整体来看,优先放入体积较 ...
- mybatis源码追踪1——Mapper方法用法解析
Mapper中的方法执行时会构造为org.apache.ibatis.binding.MapperMethod$MethodSignature对象,从该类源码中可以了解如何使用Mapper方法. [支 ...