Big Data(五)关于Hadoop的HA的实践搭建
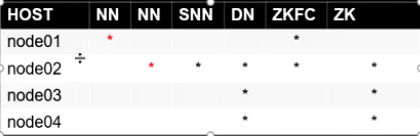
JoinNode 分布在node01,node02,node03
1.停止之前的集群
2.免密:node01,node02
node02:
cd ~/.ssh
ssh-keygen -t dsa -P '' -f ./id_dsa
cat id_dsa.pub >> authorized_keys
scp ./id_dsa.pub node01:`pwd`/node02.pub
node01:
cd ~/.ssh
cat node02.pub >> authorized_keys
3.zookeeper 集群搭建 java语言开发(需要jdk)
node02:
tar xf zook....tar.gz
mv zoo... /opt/bigdata
cd /opt/bigdata/zoo....
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/var/bigdata/hadoop/zk
server.=node02::
server.=node03::
server.=node04::
mkdir /var/bigdata/hadoop/zk
echo > /var/bigdata/hadoop/zk/myid
vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
. /etc/profile
cd /opt/bigdata
scp -r ./zookeeper-3.4. node03:`pwd`
scp -r ./zookeeper-3.4. node04:`pwd`
node03:
mkdir /var/bigdata/hadoop/zk
echo > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile
node04:
mkdir /var/bigdata/hadoop/zk
echo > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile node02~node04:
zkServer.sh start
4.配置hadoop的core和hdfs
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>node02:,node03:,node04:</value>
</property> hdfs-site.xml
#下面是重命名
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/data</value>
</property>
#以下是 一对多,逻辑到物理节点的映射
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:</value>
</property> #以下是JN在哪里启动,数据存那个磁盘
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property> #HA角色切换的代理类和实现方法,我们用的ssh免密
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property> #开启自动化: 启动zkfc
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
5.分发两个配置文件
6.开启1,2,3台的journalnode
hadoop-daemon.sh start journalnode
7.选择一个NN 做格式化
hdfs namenode -format
8.启动该NN的namenode
hadoop-daemon.sh start namenode
9.在另一台NN进行同步
hdfs namenode -bootstrapStandby
10.在node01下格式化zk
hdfs zkfc -formatZK
11.启动
start-dfs.sh
12.验证
kill - xxx
a)杀死active NN
b)杀死active NN身边的zkfc
c)shutdown activeNN 主机的网卡 : ifconfig eth0 down
2节点一直阻塞降级
如果恢复1上的网卡 ifconfig eth0 up
最终 2 变成active
Big Data(五)关于Hadoop的HA的实践搭建的更多相关文章
- hadoop yarn HA集群搭建
可先完成hadoop namenode HA的搭建:http://www.cnblogs.com/kisf/p/7458519.html 搭建yarnde HA只需要在namenode HA配置基础上 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- 安装hadoop+zookeeper ha
安装hadoop+zookeeper ha 前期工作配置好网络和主机名和关闭防火墙 chkconfig iptables off //关闭防火墙 1.安装好java并配置好相关变量 (/etc/pro ...
- hadoop NameNode HA 和ResouceManager HA
官网配置地址: HDFS HA : http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvai ...
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
随机推荐
- SAP MaxDB Backup and Restore
Back up the data and redo log entries from the data and log areas of your database to data carriers ...
- DPM(物体检测)
1.DPM(物体检测流程) 1.计算DPM特征图 2.计算响应图 3.使用SVM对响应图进行分类 4.对最后的选框做局部检测识别 DPM的梯度提取方向,将图片中的四个区域进行区分,将有符号梯度方向从0 ...
- 匿名内部类 this.val$的问题
一天偶尔在网上找到一个jar包,反编译后出现了如下的代码: public void defineAnonymousInnerClass(String name) { new Thread(na ...
- web开发(三) 会话机制,Cookie和Session详解
在网上看见一篇不错的文章,写的详细. 以下内容引用那篇博文.转载于<http://www.cnblogs.com/whgk/p/6422391.html>,在此仅供学习参考之用. 一.会话 ...
- Android 动态申请权限
AndroidManifest.xml(清单文件)添加需要的权限 <uses-permission android:name="android.permission.ACCESS_CO ...
- linux计划crontab
linux计划crontab 启动crontab服务 一般启动服务用 /sbin/service crond start 若是根用户的cron服务可以用 sudo service crond sta ...
- MySQL备份工具之mysqlhotcopy
mysqlhotcopy使用lock tables.flush tables和cp或scp来快速备份数据库.它是备份数据库或单个表最快的途径,完全属于物理备份,但只能用于备份MyISAM存储引擎和运行 ...
- 对于富文本编辑器中使用lazyload图片懒加载
使用lazyload.js图片懒加载的作用是给用户一个好的浏览体验,同时对服务器减轻了压力,当用户浏览到该图片的时候再对图片进行加载,项目中使用lazyload的时候需要将图片加入data-orgin ...
- 应用安全 - 工具 - 浏览器 - 火狐(FireFox) - 漏洞汇总
CVE-2010-3131 Date Aug 类型 Mozilla Firefox - 'dwmapi.dll' DLL Hijacking 影响范围 Firefox <= CVE-2010 ...
- Studio 3T 破解教程
亲测可用 ,且小编一直在使用 1.创建文件studio3t.bat 并将下面这段内容复制 @echo off ECHO 重置Studio 3T的使用日期...... FOR /f "toke ...