python爬虫实战 获取豆瓣排名前250的电影信息--基于正则表达式
一、项目目标
爬取豆瓣TOP250电影的评分、评价人数、短评等信息,并在其保存在txt文件中,html解析方式基于正则表达式
二、确定页面内容
爬虫地址:https://movie.douban.com/top250
确定爬取内容:视频链接,视频名称,导演/主演名称,视频评分,视频简介,评价人数等信息
打开网页,按F12键,可获取以下界面信息
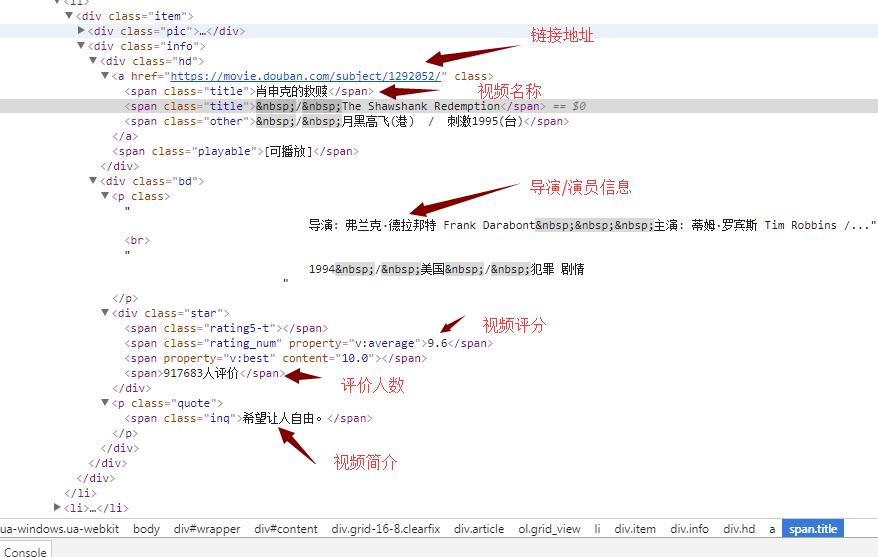
观察可知,每一部视频的详细信息都存放在li标签中
每部视频的视频名称在 class属性值为title 的span标签里,视频名称有可能有多个(中英文);
每部视频的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每部视频的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每部视频的链接在对应li标签里的一个a标签里
每部视频的简介在对应li标签里的一个class属性值为ing的标签里
python 代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/12/1 15:55
# @Author : gj
# @Site :
# @File : test_class.py
# @Software: PyCharm import urllib2,re,threading '''
伪造头信息
'''
def Get_header():
headers = {
'USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
}
return headers '''
获取页面内容
''' def Spider(url,header):
req = urllib2.Request(url=url,headers=header)
html = urllib2.urlopen(req)
info = html.read()
return info def Analyse(infos):
pattern = re.compile('<ol class="grid_view">(.*?)</ol>',re.S)
info = pattern.findall(infos)
pattern = re.compile("<li>(.*?)</li>",re.S)
movie_infos = pattern.findall(info[0])
movie=[]
for movie_info in movie_infos:
movie_temp=[]
url = ""
title=""
director=""
score=""
peoples=""
inq=""
#获取链接地址
pattern_url = re.compile('<a href="(.*?)" class="">')
movie_urls = pattern.findall(movie_info)
for movie_url in movie_urls:
url = url+movie_url
movie_temp.append(url) # 获取视频名称
pattern_title = re.compile('<span class="title">(.*?)</span>')
movie_titles = pattern_title.findall(movie_info)
for movie_title in movie_titles:
title = title+movie_title
movie_temp.append(title) # 获取视频演员表
pattern_director = re.compile('<p class="">(.*?)<br>',re.S)
movie_directors = pattern_director.findall(movie_info)
for movie_director in movie_directors:
director = director+movie_director
movie_temp.append(director) #获取视频评分
pattern_score = re.compile('<div class="star">.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S)
movie_scores = pattern_score.findall(movie_info)
for movie_score in movie_scores:
score = movie_score[0]
peoples = movie_score[1]
break
movie_temp.append(score)
movie_temp.append(peoples) # 获取视频简介
pattern_inq = re.compile('<p class="quote">.*?<span class="inq">(.*?)</span>.*?</p>',re.S)
movie_inqs = pattern_inq.findall(movie_info)
if len(movie_inqs)>0:
inq = movie_inqs[0]
else:
inq ='该视频无简介'
movie_temp.append(inq)
movie.append(movie_temp)
return movie '''
将返回内容写入文件
'''
def write_file(infos):
#防止多个线程写文件造成数据错乱
mutex.acquire()
with open("./movie.txt","ab") as f:
for info in infos:
write_info = ""
for i in range(0,len(info)):
info[i] = info[i].replace("\n","")
write_info = write_info+info[i]+" "
write_info= write_info+"\n"
f.write(write_info)
mutex.release() def start(i):
url = "https://movie.douban.com/top250?start=%d&filter="%(i*25)
headers = Get_header()
infos= Spider(url,headers)
movie_infos = Analyse(infos)
write_file(movie_infos) def main():
#创建多线程
Thread = []
for i in range(0,10):
t=threading.Thread(target=start,args=(i,))
Thread.append(t)
for i in range(0,10):
Thread[i].start()
for i in range(0,10):
Thread[i].join()
if __name__ == "__main__":
#加锁
mutex = threading.Lock()
main()
最终结果会在当前目录下生成一个movie.txt txt中记录了每部视频的相关信息,大概格式如下(没有过多的调整文件格式,这里面可以写入mysql,或者写入execl中,更加方便查看)

以上就是基于正则表达式来获取豆瓣排名钱250的电影信息的爬虫原理及简单脚本。
python爬虫实战 获取豆瓣排名前250的电影信息--基于正则表达式的更多相关文章
- python3爬取豆瓣排名前250电影信息
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : doubanmovie.py # @Author: Anthony.waa # @Dat ...
- 记一次python爬虫实战,豆瓣电影Top250爬虫
import requests from bs4 import BeautifulSoup import re import traceback def GetHtmlText(url): for i ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
- 如何用Python在豆瓣中获取自己喜欢的TOP N电影信息
一.什么是 Python Python (蟒蛇)是一门简单易学. 优雅健壮. 功能强大. 面向对象的解释型脚本语言.具有 20+ 年发展历史, 成熟稳定. 具有丰富和强大的类库支持日常应用. 1989 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
随机推荐
- (MariaDB)MySQL数据类型详解和存储机制
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...
- poi入门之读写excel
Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程式对Microsoft Office格式档案读和写的功能.该篇是介绍poi基本的 ...
- LeetCode 287. Find the Duplicate Number (找到重复的数字)
Given an array nums containing n + 1 integers where each integer is between 1 and n (inclusive), pro ...
- oracle赋值问题(将同一表中某一字段赋值给另外一个字段的语句)
将同一表中某一字段赋值给另外一个字段的语句update jxc_ckmx ckmx1 set ckmx1.ddsl = (select ckmx2.sl from jxc_ckmx ckmx2 whe ...
- 一起来学linux:NFS服务器搭建
p { margin-bottom: 0.25cm; line-height: 120% } a:link { } nfs是network file system的缩写,作用在于让不同的网络,不同的机 ...
- js判断元素滑动方向(上下左右)移动端
每天学习一点点. 1 var startx, starty; //获得角度 function getAngle(angx, angy) { return Math.atan2(angy, angx) ...
- Lua 和 C 交互中虚拟栈的操作
Lua 和 C 交互中虚拟栈的操作 /* int lua_pcall(lua_State *L, int nargs, int nresults, int msgh) * 以保护模式调用具有" ...
- Winsock网络编程笔记(2)----基于TCP的server和client
今天抽空看了一些简单的东西,主要是对服务器server和客户端client的简单实现. 面向连接的server和client,其工作流程如下图所示: 服务器和客户端将按照这个流程就行开发..(个人觉得 ...
- Django开发小型站之前期准备(一)
语言:python3.5 工具:JetBrains PyCharm virtualenvwrapper优点: 1.使不同的应用开发环境独立 2.环境升级不影响其他应用,也不会影响全局的python环境 ...
- js之学习正则表达式
看了掘金的一个作者写的JS正则表达式完整教程 受益匪浅,感谢作者的无私奉献.在此,做下笔记. 目录 0. 目录 1. 正则表达式字符匹配 1.1.字符组 1.2.量词 1.3.多选分支 1.4.案例分 ...