MLlib--SVD算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4db529fa9f4c042673c6dc8218251f6c.html
SVD算法
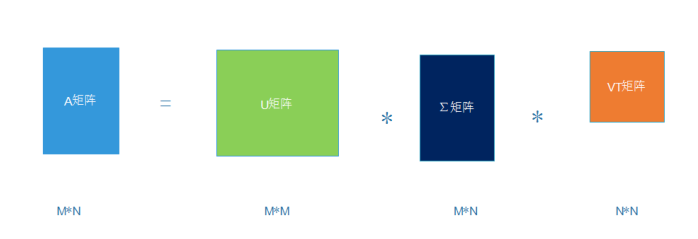
1.1什么是SVD?
1.2矩阵的深入理解
就如同一个对象可能有多个引用名字不同,所以一组相似矩阵都是一个线性变换在不同的组基的描述
1.3SVD提取矩阵的特征,解决以上的局限
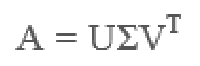
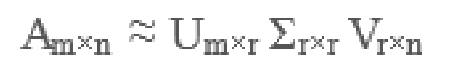

1.4SVD_code
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg
import org.apache.spark.mllib.linalg.{Matrix, SingularValueDecomposition, Vectors}
import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.rdd.RDD
/**
* Created by hzf
*/
object SVD_new {
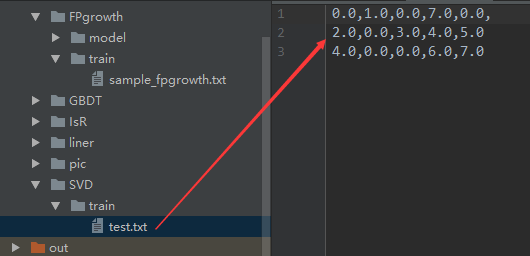
// E:\IDEA_Projects\mlib\data\SVD\train\test.txt E:\IDEA_Projects\mlib\data\SVD\model 3 true 1.0E-9d local
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
if (args.length < 6) {
System.err.println("Usage: SVD <inputPath> <modelPath> <num> <compute> <ignore> <master> [<AppName>]")
System.exit(1)
}
val appName = if (args.length > 6) args(6) else "SVD"
val conf = new SparkConf().setAppName(appName).setMaster(args(5))
val sc = new SparkContext(conf)
val data = sc.textFile(args(0))
val train: RDD[linalg.Vector] = data.map(sample => {
Vectors.dense(sample.split(",").map(_.toDouble))
})
val mat: RowMatrix = new RowMatrix(train)
var compute = true
compute = args(3) match {
case "true" => true
case "false" => false
}
//第一个参数3意味着取top 3个奇异值,第二个参数true意味着计算矩阵U,第三个参数意味小于1.0E-9d的奇异值将被抛弃
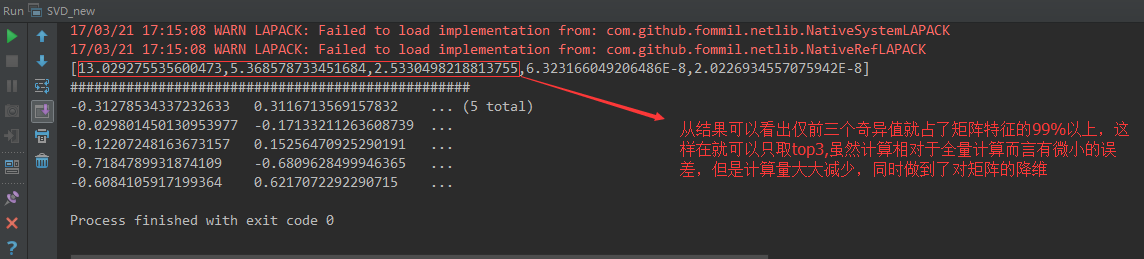
val svd: SingularValueDecomposition[RowMatrix, Matrix] = mat.computeSVD(args(2).toInt, compute);
val u = svd.U;
//矩阵U
val s = svd.s
//奇异值
val v = svd.V //矩阵V
println(s);
println("#" * 50);
println(v);
}
}
E:\IDEA_Projects\mlib\data\SVD\train\test.txt E:\IDEA_Projects\mlib\data\SVD\model 3true1.0E-9d local
MLlib--SVD算法的更多相关文章
- 推荐系统 SVD和SVD++算法
推荐系统 SVD和SVD++算法 SVD: SVD++: [Reference] 1.SVD在推荐系统中的应用详解以及算法推导 2.推荐系统——SVD/SVD++ 3.SVD++ 4.SVD++协 ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- spark mllib k-means算法实现
package iie.udps.example.spark.mllib; import java.util.regex.Pattern; import org.apache.spark.SparkC ...
- Spark MLlib回归算法LinearRegression
算法说明 线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析方法,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归,在实际情况中大多数都是多 ...
- Spark MLlib基本算法【相关性分析、卡方检验、总结器】
一.相关性分析 1.简介 计算两个系列数据之间的相关性是统计中的常见操作.在spark.ml中提供了很多算法用来计算两两的相关性.目前支持的相关性算法是Pearson和Spearman.Correla ...
- SVD/SVD++实现推荐算法
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不仅可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域. ...
- 机器学习算法总结(九)——降维(SVD, PCA)
降维是机器学习中很重要的一种思想.在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”.另 ...
- 一步步教你轻松学奇异值分解SVD降维算法
一步步教你轻松学奇异值分解SVD降维算法 (白宁超 2018年10月24日09:04:56 ) 摘要:奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分 ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- SVD在推荐系统中的应用详解以及算法推导
SVD在推荐系统中的应用详解以及算法推导 出处http://blog.csdn.net/zhongkejingwang/article/details/43083603 前面文章SVD原理及推 ...
随机推荐
- 第五节 suid/ sgid /sbit /which /locate / find /stat / ln / uname -a
复习上节课内容(重点记录)1.chown -R 递归修改目录下包含子目录和子目录下的文件的属组2.chmod -R 递归修改目录下包含子目录和子目录下的文件的权限 ================== ...
- 微信小程序如何开发制作
微信小程序如何开发制作 微容SMO是一款微信小程序的免费在线制作工具,用户在微容平台上无需编辑代码,可通过拖拽式操作即可完成小程序的制作,真正意义上实现了小程序零代码免费制作! 消除技术门槛:无需代码 ...
- PHP动态图像处理
相关代码见:https://www.github.com/lozybean/learn_www/ 目录 1. 画布管理: imagecreate():创建一个基于调色板的画布,指定画布的长.宽 ...
- 深入了解CSS字体度量,行高和vertical-align
line-height和vertical-align在CSS中是两个简单的属性.如此简单,大多数人都相信自己已经完全理解它们是如何工作的以及如何使用它们.但事实上并不如此.他们其实很复杂,也是CSS中 ...
- vexx 邀请码 送3个比特龙
错过了比特币的行情,注册获取3个原始比特币分叉币,比特龙. 目前10元一个,送3个币.类似于股票IPO,第一天一般会冲高十几倍,建议第一天就卖. 如果看好就继续持有吧. 放心是送的不用钱的. 注册网址 ...
- Invalid bound statement (not found): com.shizongger.chapter2.mapper.UserMapper.insertUser 解决方案
在配置MyBatis时报错信息如下: Invalid bound statement (not found): com.shizongger.chapter2.mapper.UserMapper.in ...
- angular4.0项目main.ts详解
main.ts负责引导整个angular应用的起点 // 导入enableProdMode用来关闭angular开发者模式 import { enableProdMode } from '@angul ...
- 嵌入式linux下wifi网卡的使用(四)——应用程序sub_supplicant编译
有readme先看看readme看看有没有编译的方法 里面告诉我们安装时可能会依赖某些库事实证明会依赖openssl库,之前也使用过openssl 这个文件中有个defualtconfig,先用它做. ...
- python如何玩“跳一跳”!(windows安桌版本请进!)
最近"跳一跳",很火爆,有木有? 看了一下网上的教程,动作搭建了一下环境,就可以用脚本自动跑起来啦!!! 下面说一下android手机的实现过程: 首先,是python环境的搭建 ...
- linux下vsftpd的安装及配置使用详细步骤
vsftpd 是“very secure FTP daemon”的缩写,安全性是它的一个最大的特点. vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 Linux.BS ...