【NLP】Recurrent Neural Network and Language Models
0. Overview
What is language models?
A time series prediction problem.
It assigns a probility to a sequence of words,and the total prob of all the sequence equal one.
Many Natural Language Processing can be structured as (conditional) language modelling.
Such as Translation:
P(certain Chinese text | given English text)
Note that the Prob follows the Bayes Formula.
How to evaluate a Language Model?
Measured with cross entropy.
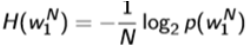
Three data sets:
1 Penn Treebank: www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
2 Billion Word Corpus: code.google.com/p/1-billion-word-language-modeling-benchmark/
3 WikiText datasets: Pointer Sentinel Mixture Models. Merity et al., arXiv 2016
|
Overview: Three approaches to build language models: Count based n-gram models: approximate the history of observed words with just the previous n words. Neural n-gram models: embed the same fixed n-gram history in a continues space and thus better capture correlations between histories. Recurrent Neural Networks: we drop the fixed n-gram history and compress the entire history in a fixed length vector, enabling long range correlations to be captured. |
1. N-Gram models:
Assumption:
Only previous history matters.
Only k-1 words are included in history
Kth order Markov model
2-gram language model:
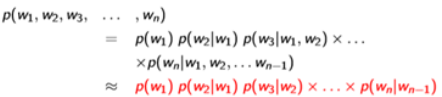
The conditioning context, wi−1, is called the history
Estimate Probabilities:
(For example: 3-gram)
 (count w1,w2,w3 appearing in the corpus)
(count w1,w2,w3 appearing in the corpus)
Interpolated Back-Off:
That is , sometimes some certain phrase don’t appear in the corpus so the Prob of them is zero. To avoid this situation, we use Interpolated Back-off. That is to say, Interpolate k-gram models(k = n-1、n-2…1) into the n-gram models.
A simpal approach:
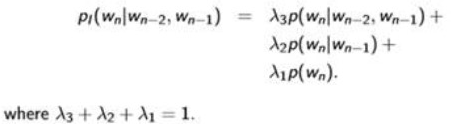
Summary for n-gram:
Good: easy to train. Fast.
Bad: Large n-grams are sparse. Hard to capture long dependencies. Cannot capture correlations between similary word distributions. Cannot resolve the word morphological problem.(running – jumping)
2. Neural N-Gram Language Models
Use A feed forward network like:
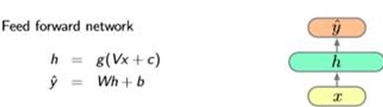
Trigram(3-gram) Neural Network Language Model for example:
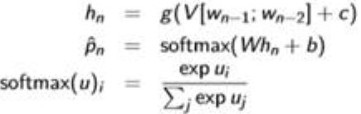
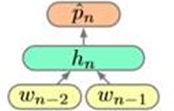
Wi are hot-vectors. Pi are distributions. And shape is |V|(words in the vocabulary)
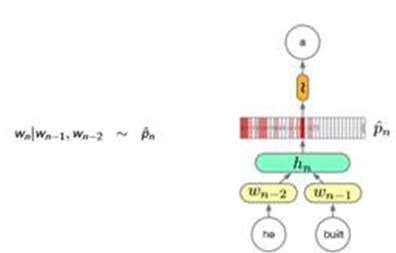
(a sampal:detail cal graph)
Define the loss:cross entopy:

Training: use Gradient Descent

And a sampal of taining:
Comparsion with Count based n-gram LMs:
Good: Better performance on unseen n-grams But poorer on seen n-grams.(Sol: direct(linear) n-gram fertures). Use smaller memory than Counted based n-gram.
Bad: The number of parameters in the models scales with n-gram size. There is a limit on the longest dependencies that an be captured.
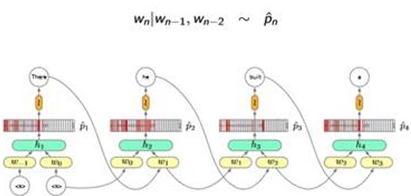
3. Recurrent Neural Network LM
That is to say, using a recurrent neural network to build our LM.
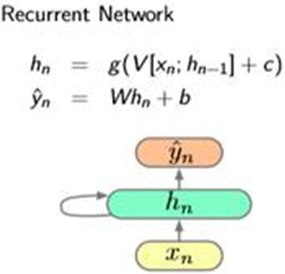

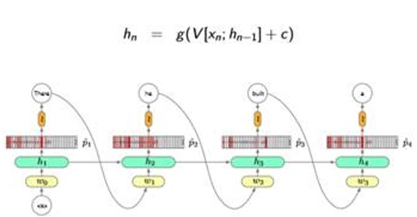
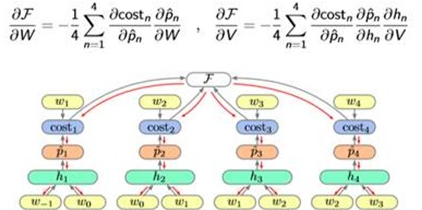
Model and Train:
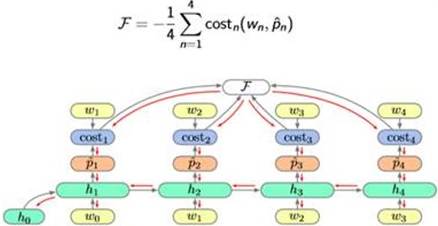
Algorithm: Back Propagation Through Time(BPTT)
Note:
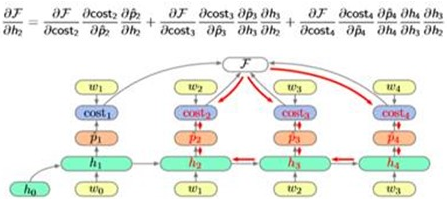
Note that, the Gradient Descent depend heavily. So the improved algorithm is:
Algorithm: Truncated Back Propagation Through Time.(TBPTT)
So the Cal graph looks like this:
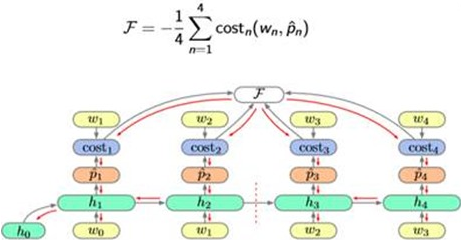
So the Training process and Gradient Descent:

Summary of the Recurrent NN LMs:
Good:
RNNs can represent unbounded dependencies, unlike models with a fixed n-gram order.
RNNs compress histories of words into a fixed size hidden vector.
The number of parameters does not grow with the length of dependencies captured, but they do grow with the amount of information stored in the hidden layer.
Bad:
RNNs are hard to learn and often will not discover long range dependencies present in the data(So we learn LSTM unit).
Increasing the size of the hidden layer, and thus memory, increases the computation and memory quadratically.
Mostly trained with Maximum Likelihood based objectives which do not encode the expected frequencies of words a priori.
Some blogs recommended:
|
Andrej Karpathy: The Unreasonable Effectiveness of Recurrent Neural Networks karpathy.github.io/2015/05/21/rnn-effectiveness/ Yoav Goldberg: The unreasonable effectiveness of Character-level Language Models nbviewer.jupyter.org/gist/yoavg/d76121dfde2618422139 Stephen Merity: Explaining and illustrating orthogonal initialization for recurrent neural networks. smerity.com/articles/2016/orthogonal_init.html |
【NLP】Recurrent Neural Network and Language Models的更多相关文章
- pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类. 论文地址:88888888 模型结构图: 原理自行参考论文,code and comment: # -*- coding: utf-8 -*- # @time : ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- 【NLP】自然语言处理:词向量和语言模型
声明: 这是转载自LICSTAR博士的牛文,原文载于此:http://licstar.net/archives/328 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领 ...
- Recurrent Neural Network Language Modeling Toolkit代码学习
Recurrent Neural Network Language Modeling Toolkit 工具使用点击打开链接 本博客地址:http://blog.csdn.net/wangxingin ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- Recurrent Neural Network(循环神经网络)
Reference: Alex Graves的[Supervised Sequence Labelling with RecurrentNeural Networks] Alex是RNN最著名变种 ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- (zhuan) Recurrent Neural Network
Recurrent Neural Network 2016年07月01日 Deep learning Deep learning 字数:24235 this blog from: http:/ ...
随机推荐
- samba故障:protocol negotiation failed: NT_STATUS_IO_TIMEOUT
windows下无法访问samba共享目录,若无任何提示则需要到linux服务器上访问samba共享,看下是否有问题提示 故障解决过程:(保证网络通畅) 1.查看samba服务器是否正常,smb服务器 ...
- Java函数式编程和lambda表达式
为什么要使用函数式编程 函数式编程更多时候是一种编程的思维方式,是种方法论.函数式与命令式编程的区别主要在于:函数式编程是告诉代码你要做什么,而命令式编程则是告诉代码要怎么做.说白了,函数式编程是基于 ...
- Python从菜鸟到高手(8):print函数、赋值与代码块
1.神奇的print函数 print函数相信读者一定对它不陌生,因为在前面的章节,几乎每个例子都使用了print函数,这个函数的功能就是在控制台输出文本.不过print在输出文本时还可以进行一些设 ...
- 【C#复习总结】细说表达式树
1 前言 系类1:细说委托 系类2:细说匿名方法 系列3:细说Lambda表达式 系列4:细说泛型委托 系列5:细说表达式树 系列6:细说事件 涛声依旧,再续前言,接着用大佬的文章作为开头. 表达式树 ...
- Windows Community Toolkit 4.0 - DataGrid - Part02
概述 在上面一篇 Windows Community Toolkit 4.0 - DataGrid - Part01 中,我们针对 DataGrid 控件的 CollectionView 部分做了详细 ...
- RabbitMQ 3.6.1 升级至 3.7.9 版本(Windows 升级至Centos)
随着公司业务量的增加,原本部署在Windows服务器的RabbitMQ集群(3.6.1)总是出现莫名其妙的问题,经查询官方Issue,确认是RabbitMQ 3.6.1 版本的bug.查看从3.6.1 ...
- linux screen 工具
一.背景 系统管理员经常需要SSH 或者telent 远程登录到Linux 服务器,经常运行一些需要很长时间才能完成的任务,比如系统备份.ftp 传输等等.通常情况下我们都是为每一个这样的任务开一个远 ...
- python之psutil模块详解(Linux)--小白博客
Python-psutil模块 windows系统监控实例,查询 https://www.cnblogs.com/zhou2019/p/10567282.html 1.简单介绍 psutil是一个跨平 ...
- 使用Request+正则抓取猫眼电影(常见问题)
目前使用Request+正则表达式,爬取猫眼电影top100的例子很多,就不再具体阐述过程! 完整代码github:https://github.com/connordb/Top-100 总结一下,容 ...
- java问题
Collection 和 Collections的区别? Collection是集合类的上级接口,继承与他的接口主要有Set 和List. Collections是针对集合类的一个帮助类,他提供一系列 ...