MySQL高级知识(十)——批量插入数据脚本
前言:使用脚本进行大数据量的批量插入,对特定情况下测试数据集的建立非常有用。
0.准备
#1.创建tb_dept_bigdata(部门表)。
create table tb_dept_bigdata(
id int unsigned primary key auto_increment,
deptno mediumint unsigned not null default 0,
dname varchar(20) not null default '',
loc varchar(13) not null default ''
)engine=innodb default charset=utf8;
#2.创建tb_emp_bigdata(员工表)。
create table tb_emp_bigdata(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,/*编号*/
empname varchar(20) not null default '',/*名字*/
job varchar(9) not null default '',/*工作*/
mgr mediumint unsigned not null default 0,/*上级编号*/
hiredate date not null,/*入职时间*/
sal decimal(7,2) not null,/*薪水*/
comm decimal(7,2) not null,/*红利*/
deptno mediumint unsigned not null default 0 /*部门编号*/
)engine=innodb default charset=utf8;
#3.开启log_bin_trust_function_creators参数。
由于在创建函数时,可能会报:This function has none of DETERMINISTIC.....因此我们需开启函数创建的信任功能。
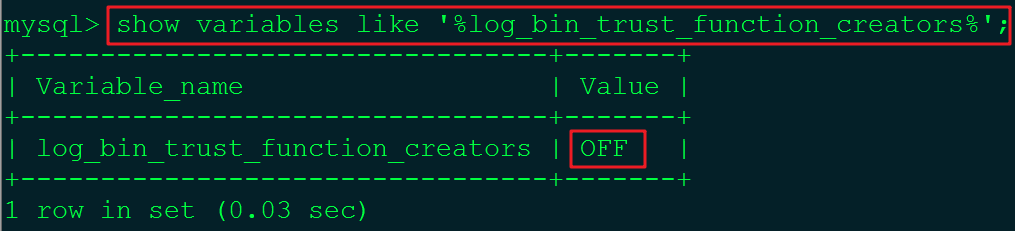
可通过set global log_bin_trust_function_creators=1的形式开启该功能,也可通过在my.cnf中永久配置的方式开启该功能,在[mysqld]下配置log_bin_trust_function_creators=1。
1.创建函数,保证每条数据都不同
#1.创建随机生成字符串的函数。
delimiter $$
drop function if exists rand_string;
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(52) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i<n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
#2.创建随机生成编号的函数。
delimiter $$
drop function if exists rand_num;
create function rand_num() returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*100);
return i;
end $$
2.创建存储过程用于批量插入数据
#1.创建往tb_dept_bigdata表中插入数据的存储过程。
delimiter $$
drop procedure if exists insert_dept;
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit=0;
repeat
set i=i+1;
insert into tb_dept_bigdata (deptno,dname,loc) values(rand_num(),rand_string(10),rand_string(8));
until i=max_num
end repeat;
commit;
end $$
#2.创建往tb_emp_bigdata表中插入数据的存储过程。
delimiter $$
drop procedure if exists insert_emp;
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit=0;
repeat
set i=i+1;
insert into tb_emp_bigdata (empno,empname,job,mgr,hiredate,sal,comm,deptno) values((start+i),rand_string(6),'developer',0001,curdate(),2000,400,rand_num());
until i=max_num
end repeat;
commit;
end $$
3.具体执行过程批量插入数据
#1.首先执行随机生成字符串的函数。
#2.然后执行随机生成编号的函数。
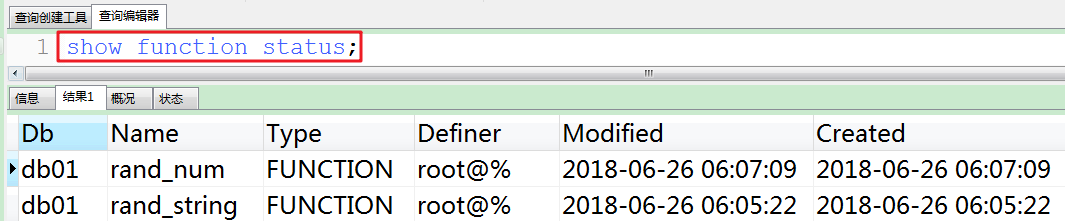
#3.查看函数是否创建成功。
#4.执行插入数据的存储过程,并查看其创建情况。

#5.执行存储过程,插入数据。
a.首先执行insert_dept存储过程。
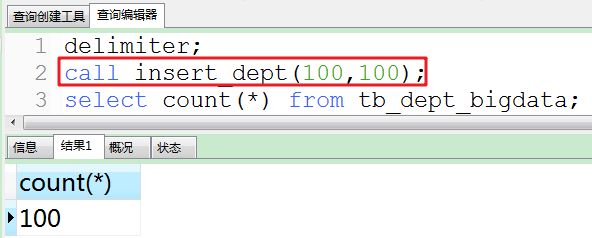
说明:deptno的范围[100,110),因为deptno的值使用了rand_num()函数。
b.然后执行insert_emp存储过程。
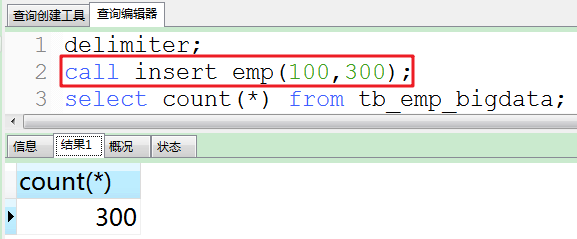
说明:tb_emp_bigdata表中deptno编号的范围[100,110),使用rand_num()函数。
注:对于部门表的deptno和员工表中deptno的数据都使用了rand_num()函数进行赋值,确保两边的值能对应。
4.删除函数与存储过程
#1.删除函数
drop function rand_num;
drop function rand_string;
#2.删除存储过程
drop procedure insert_dept;
drop procedure insert_emp;
总结
①注意mysql中函数和存储过程的写法。
②注意存储过程的调用,call procedurename。
③注意开启对函数的信任,log_bin_trust_function_creators参数。
by Shawn Chen,2018.6.26日,晚。
相关内容
MySQL高级知识(十)——批量插入数据脚本的更多相关文章
- 使用JDBC在MySQL数据库中快速批量插入数据
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(10W+),如何提高效率呢? 在JDBC编程接口中Statement 有两个方法特别值得注意: void addBatch ...
- MySQL随机字符串函数批量插入数据
简单举个例子: drop table if exists demo1 create table demo1 ( id int primary key auto_increment, name ) ...
- MySQL高级知识(十六)——小表驱动大表
前言:本来小表驱动大表的知识应该在前面就讲解的,但是由于之前并没有学习数据批量插入,因此将其放在这里.在查询的优化中永远小表驱动大表. 1.为什么要小表驱动大表呢 类似循环嵌套 for(int i=5 ...
- MySQL高级知识系列目录
MySQL高级知识(一)——基础 MySQL高级知识(二)——Join查询 MySQL高级知识(三)——索引 MySQL高级知识(四)——Explain MySQL高级知识(五)——索引分析 MySQ ...
- MySQL高级知识(十一)——Show Profile
前言:Show Profile是mysql提供的可以用来分析当前会话中sql语句执行的资源消耗情况的工具,可用于sql调优的测量.默认情况下处于关闭状态,并保存最近15次的运行结果. 1.分析步骤 # ...
- MySQL高级知识(十五)——主从复制
前言:本章主要讲解MySQL主从复制的操作步骤.由于环境限制,主机使用Windows环境,从机使用用Linux环境.另外MySQL的版本最好一致,笔者采用的MySQL5.7.22版本,具体安装过程请查 ...
- MySQL高级知识(十四)——行锁
前言:前面学习了表锁的相关知识,本篇主要介绍行锁的相关知识.行锁偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁,锁定粒度小,发生锁冲突的概率低,但并发度高. 0.准备 #1.创建相关测试表tb_ ...
- mybatis foreach批量插入数据:Oracle与MySQL区别
mybatis foreach批量插入数据:Oracle与MySQL不同点: 主要不同点在于foreach标签内separator属性的设置问题: separator设置为","分 ...
- MySQL批量插入数据的几种方法
最近公司要求测试数据库的性能,就上网查了一些批量插入数据的代码,发现有好几种不同的用法,插入同样数据的耗时也有区别 别的先不说,先上一段代码与君共享 方法一: package com.bigdata; ...
随机推荐
- 腾讯云图片鉴黄集成到C#
官方文档:https://cloud.tencent.com/document/product/641/12422 请求官方API及签名的生成代码如下: var urlList = new List& ...
- 理解 Python 中的可变参数 *args 和 **kwargs:
默认参数: Python是支持可变参数的,最简单的方法莫过于使用默认参数,例如: def getSum(x,y=5): print "x:", x print "y:& ...
- [PHP] PHP在CLI环境下的错误日志
1.display_errors = Off;//控制php是否输出错误;在生产环境中输出会泄露敏感信息;建议记录错误而不是将它们发送到STDOUToff :不显示任何错误;stderr :向STDE ...
- 2018最新iOS端界面UI设计规范整理
在iPhone 6还没出的时候,都是用640×1136 px来做设计稿的,自从6的发布,所有的设计稿尺寸以750×1334 px来做设计稿尺寸 以750x1334px作为设计稿标准尺寸的原由: 从中间 ...
- Math.max()/min()
返回一组数中最大值: 找到数组中的最大值,有两种方法,一种是apply,一种使用拓展运算符. 释义: 由于max()里面参数不能为数组,所以借助apply(funtion,args)方法调用Math. ...
- js 二叉树遍历
二叉树定义这里不再赘述. 我这里有个二叉树: var tree = { "id": 0, "name": "root", "lef ...
- 将Y-m-d转换为Y年m月d日
自己编写的,不能直接套用,理解后可自行变化: $var=explode(' ',$res['act_starting']); $var1=$var[0]; $time=explode ...
- xshell工具source导入几个G的数据库
直奔主题 xshell工具source导入几个G的数据库 1.先把sql文件通过ftp或者winscp上传到服务器对应站点根目录,如图所示 2.进入xshell界面,进入数据库之前一定设定编码,否者会 ...
- 浏览器解析JavaScript原理
1.浏览器解析JavaScript原理特点: 1.跨平台 2.弱类型 javascript 定义的时候不需要定义数据类型,数据类型是根据变量值来确定的. var a = 10; 数字类型 ...
- 06-HTML-表格标签
<html> <head> <title>表格标签学习</title> <meta charset="utf-8"/> ...