利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍
Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium也是一个强大的网络数据采集工具,其可以让浏览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据。
Selenium模块是Python的第三方库,可以通过pip进行安装:
|
pip3 install selenium |
Selenium自己不带浏览器,需要配合第三方浏览器来使用。通过help命令查看Selenium的Webdriver功能,查看Webdriver支持的浏览器:
|
from selenium import webdriver help(webdriver) |
查看执行后的结果,如下图所示:
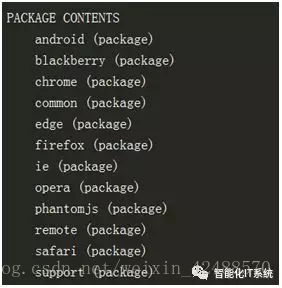
在这个案例中,采用PhantomJS。Selenium和PhantomJS的配合使用可以完全模拟用户在浏览器上的所有操作,包括输入框内容填写、单击、截屏、下滑等各种操作。这样,对于需要登录的网站,用户可以不需要通过构造表单或提交cookie信息来登录网站。
二. 案例介绍
这里所举的案例,是利用Selenium爬取淘宝商品信息,爬取的内容为淘宝网(https://www.taobao.com/)上男士短袖的商品信息,如下图所示:
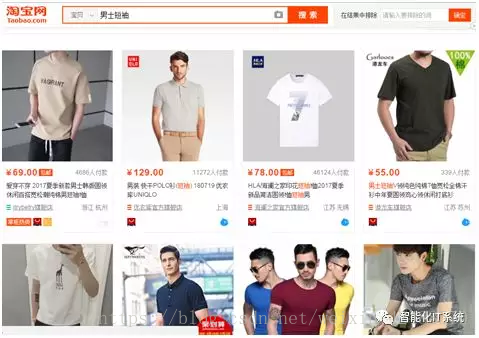
这里可以看到,在用户输入淘宝后,需要模拟输入,在输入框输入“男士短袖”。
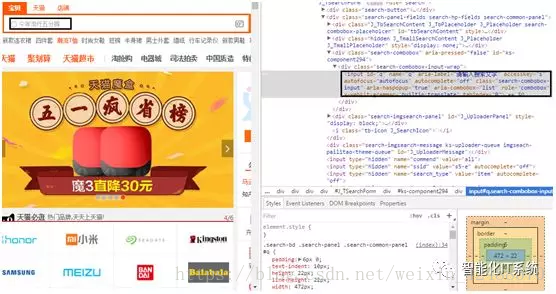
案例中使用Selenium和PhantomJS,模拟电脑的搜索操作,输入商品名称进行搜索,如图所示,“检查”搜索框元素。
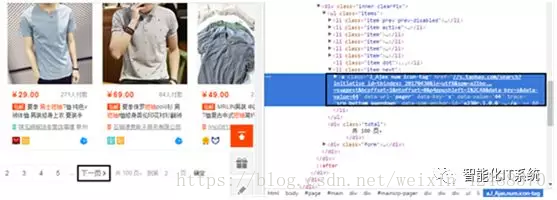
并且如下图所示,“检查”下一页元素:
爬取的内容有商品价格、付款人数、商品名称、商家名称和地址,如下图所示:
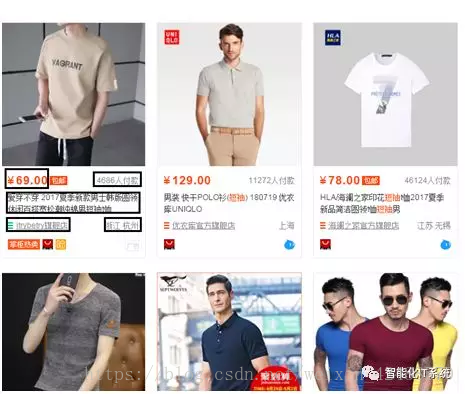
最后把爬取数据存储到MongoDB数据库中。
三. 相关技术
这里把除了selenium之外所需要的知识列一下,这里就不做详细解释了,如果不清楚的话可以百度了解下。
mongoDB的使用,以及在python中用mongodb进行数据存储。
lxml,爬虫三大方法之一,解析效率比较高,使用难度相比正则表达式要低(上一篇文章的解析方法是正则表达式)。
间歇休息的方法:driver.implicitly_wait
四. 源代码
代码如下所示,可复制直接执行:
from selenium import webdriver
from lxml import etree
import time
import pymongo client = pymongo.MongoClient('localhost', 27017)
mydb = client['mydb']
taobao = mydb['taobao'] driver = webdriver.PhantomJS()
driver.maximize_window() def get_info(url,page):
page = page + 1
driver.get(url)
driver.implicitly_wait(10)
selector = etree.HTML(driver.page_source)
infos = selector.xpath('//div[@class="item J_MouserOnverReq"]') for info in infos:
data = info.xpath('div/div/a')[0]
goods = data.xpath('string(.)').strip()
price = info.xpath('div/div/div/strong/text()')[0]
sell = info.xpath('div/div/div[@class="deal-cnt"]/text()')[0]
shop = info.xpath('div[2]/div[3]/div[1]/a/span[2]/text()')[0]
address = info.xpath('div[2]/div[3]/div[2]/text()')[0]
commodity = {
'good':goods,
'price':price,
'sell':sell,
'shop':shop,
'address':address
}
taobao.insert_one(commodity) if page <= 50:
NextPage(url,page)
else:
pass def NextPage(url,page):
driver.get(url)
driver.implicitly_wait(10)
driver.find_element_by_xpath('//a[@trace="srp_bottom_pagedown"]').click()
time.sleep(4)
driver.get(driver.current_url)
driver.implicitly_wait(10)
get_info(driver.current_url,page) if __name__ == '__main__':
page = 1
url = 'https://www.taobao.com/'
driver.get(url)
driver.implicitly_wait(10)
driver.find_element_by_id('q').clear()
driver.find_element_by_id('q').send_keys('男士短袖')
driver.find_element_by_class_name('btn-search').click()
get_info(driver.current_url,page)
五. 代码解析
(1)1~4行
导入程序需要的库,selenium库用于模拟请求和交互。lxml解析数据。pymongo是mongoDB 的交互库。
(2)6~8行
打开mongoDB,进行存储准备。
(3)10~11行
最大化PhantomJS窗口。
(4)14~33行
利用lxml抓取网页数据,分别定位到所需要的信息,并把信息集成至json,存储至mongoDB。
(5)35~47行
分页处理。
(5)51~57行
利用selenium模拟输入“男士短袖”,并模拟点击操作,并获取到对应的页面信息,调取主方法解析。
———————————————————
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。

利用Selenium爬取淘宝商品信息的更多相关文章
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- 爬取淘宝商品信息,放到html页面展示
爬取淘宝商品信息 import pymysql import requests import re def getHTMLText(url): kv = {'cookie':'thw=cn; hng= ...
- 使用Selenium爬取淘宝商品
import pymongo from selenium import webdriver from selenium.common.exceptions import TimeoutExceptio ...
- selenium+pyquery爬取淘宝商品信息
import re from selenium import webdriver from selenium.common.exceptions import TimeoutException fro ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- Selenium爬取淘宝商品概要入mongodb
准备: 1.安装Selenium:终端输入 pip install selenium 2.安装下载Chromedriver:解压后放在…\Google\Chrome\Application\:如果是M ...
- selenium+phantomjs+pyquery 爬取淘宝商品信息
from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium ...
随机推荐
- 微信小程序入门(三)
11.开发框架基本介绍 四个组成部分,其它三个前面介绍过了,主要WXS: WXS:对wxml增强的一种脚本语言,可以对请求的数据进行filter或者做计算处理,帮助wxml快速构建出页面结构. 12. ...
- Android布局中的空格以及占一个汉字宽度的空格,实现不同汉字字数对齐
前言 在Android布局中进行使用到空格,以便实现文字的对齐.那么在Android中如何表示一个空格呢? 空格: (普通的英文半角空格但不换行) 窄空格: (中文全角空格 (一个中文宽度)) ...
- PowerDesigner使用方法
我们需要创建一个测试数据库,一步一步来学习使用PowerDesigner,为了简单,我们在这个数据库中只创建一个Student表和一个Major表.其表结构和关系如下所示. 看看怎样用PowerDes ...
- shiro + jwt 实现 请求头中的 rememberMe 时间限制功能
前言: 上一篇提出, 通过修改 rememberMe 的编码来实现 rememberMe的功能的设想, 事后我去尝试实现了一番, 发现太麻烦, 还是不要那么做吧. 程序还是要越简单越好. 那功能总是要 ...
- docker - 容器里安装redis
在docker中安装redis 使用命令行安装redis 下载并解压 wget http://download.redis.io/releases/redis-3.2.6.tar.gz tar -xv ...
- 安装LoadRunner时提示缺少vc2005_sp1_with_atl_fix_redist解决方案
操作系统重装后,安装LoadRunner11时,会报缺少vc2005_sp1_with_atl_fix_redist错误,类似下图所示: LR自动安装失败,在网上下载此组件安装后依然提示此信息,最终解 ...
- 第一册:lesson seventy one.
原文: He is awful. A:What's Ron Marston like , Pauline? B:He is awful.He telephoned me four times yest ...
- C#装箱和拆箱。
装箱:值类型-->引用类型. 拆箱:引用类型-->值类型 装箱:把值类型拷贝一份到堆里.反之拆箱. 具有父子关系 是拆装箱的条件之一. 所以: class Program { static ...
- Linux下尝鲜IDE Rider .NET又一开发利器
RiderRS 扯淡:很多人说:jetbrains出品,必属精品,jetbrains确实出了不少好东西,但是他的产品总感觉越用越慢,我的小Y430P高配版也倍感压力,内存占用率高. Multiple ...
- [MySQL] INFORMATION_SCHEMA 数据库包含所有表的字段
sql注入后可以通过该数据库获取所有表的字段信息 1. COLLATIONS表 提供有关每个字符集的排序规则的信息. COLLATIONS表包含以下列: COLLATION_NAME 排序规则名称. ...